
本記事は「Amazon Bedrock Advent Calendar 2024」22 日目の記事です。
re:Invent 2024 での Update と関連のないトピックですみませんmm
Amazon Bedrock ナレッジベース のデータソースについて
Amazon Bedrock ナレッジベースは、検索拡張生成 (RAG) を使用した生成 AI アプリケーションを構築するのに役立ちます。
通常、ベクトルデータベースを使用した RAG の仕組みを構築する場合は、次のような処理を実装する必要があります。
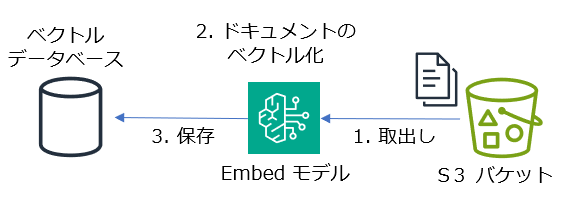
事前処理
- データソースからドキュメントを取り出す
- 埋め込みモデルでドキュメント内のテキストのベクトル値を取得する
- ベクトル値をデータベース(ベクトルデータベース)に保存する
(下図は例です)
推論実行時の処理
- 埋め込みモデルでプロンプトのテキストのベクトル値を取得する
- ベクトルデータベースからプロンプトのベクトル値と類似するドキュメントを取得する
- 取得した類似ドキュメントをコンテキストとしてプロンプトに含め、テキスト生成モデルに推論を実行する
(下図は例です)

Amazon Bedrock ナレッジベースの場合は、AWS マネジメントコンソールを使用すれば上記の事前処理を設定作業だけで実現できます。 また推論実行時の処理もナレッジベースが提供する API を使用するだけで内部的に実行してくれるので、アプリケーション側で 上記の 1 から 3 の処理を実装する必要がありません。
下図は Amazon Bedrock ナレッジベースを使用した場合の処理の流れです。 流れが複雑にみえるかもしれませんが、ナレッジベースを作成しておけば、アプリケーションからはその API を呼び出すだけでよいという部分に着目して下さい。
(下図は データソースとして Amazon S3 バケットを使用している例です)

このナレッジベースでデータソースとして使用できるのは、この記事を執筆している 2024年12月時点では下記となります。
- ベクトルストアを使用する場合のデータソース
- Amazon Kendra を使用する場合のデータソース
- Amazon Kendra GenAI Index
- 構造化データストアを使用する場合のデータソース
- Amazon Redshift
ただし、ベクトルストアを使用する場合のデータソースとしては、上記以外で、プレビュー として Web クローラーやConfluence、Salesforce、Sharepoint も試すことができます。
この記事では、このうち Web クローラーを試してみた結果を紹介したいと思います。
ただし、2024年12月現在 Web クローラーはプレビューリリースであり、今後変更される可能性があることはご注意下さい。
Web クローラーをデータソースに指定した場合のイメージ
Web クローラーをデータソースに指定するということは、推論実行時にコンテキストとして参照させたいドキュメントは、Web サイトに存在するという前提になります。
今回、Web クローラーを試すにあたって、デモ用の Web サイトを用意しました。これは、AnyCompany という架空の会社の最新情報を発しするニュースリリースサイトという想定です。(内容が プアなのはご容赦下さいw) このサイトには、AnyCompany 社の決算説明資料として PDF ファイルもリンクされています。
AnyCompany (架空の会社)のニュースリリースサイト
AWS マネジメントコンソールでの設定の流れ
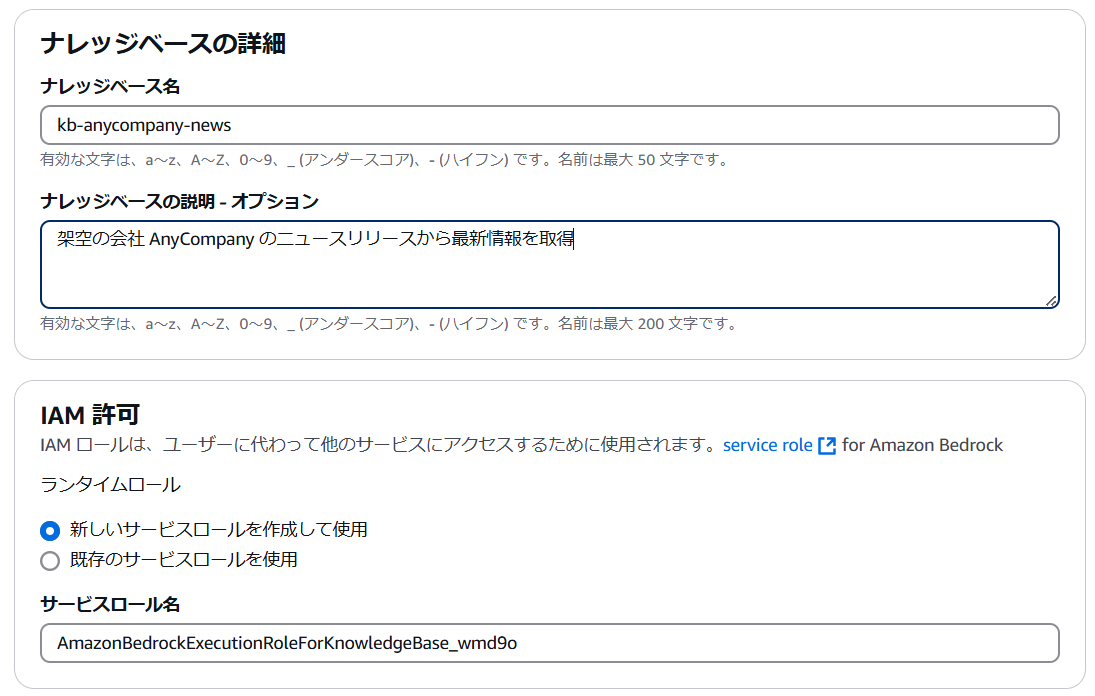
まず、Amazon Bedrock のコンソールの左側ナビゲーションメニューから [オーケストレーション] - [ナレッジベース] を選択します。右側に表示される [ナレッジベースの作成] を選択し、[Knowledge Base with vector store] を選択します。

ナレッジベースの名前や説明を入力します。IAM ロールは今回は [新しいサービスロールを作成して使用] を選択しました。
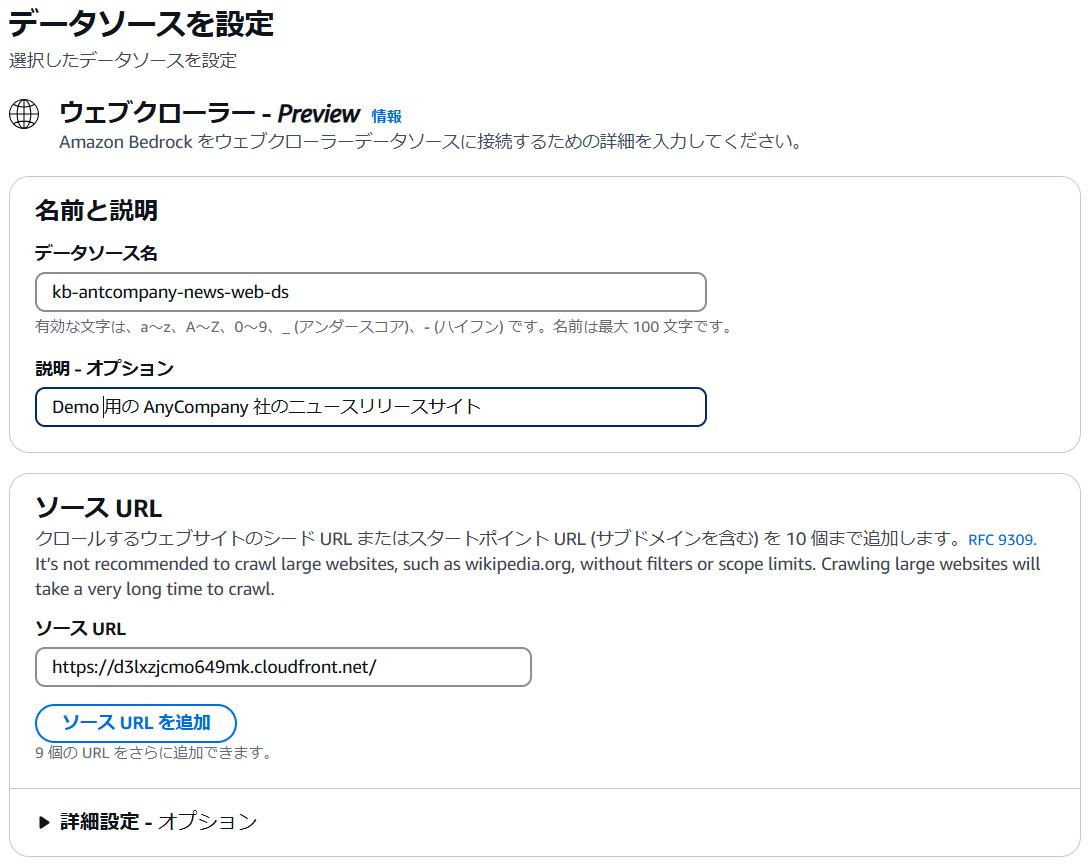
次にデータソースとして [Web Crawler - Preview] を選択します。

それ以外は今回はデフォルトのまま、[次へ] を選択します。
次にデータソース名や クロール対象となる URL を設定します。
その下に [同期スコープ] というセクションがあり、クロール対象とするドメイン範囲や、対象ファイルの Regex パターンなどを設定できますが、今回はデフォルトのままとしました。
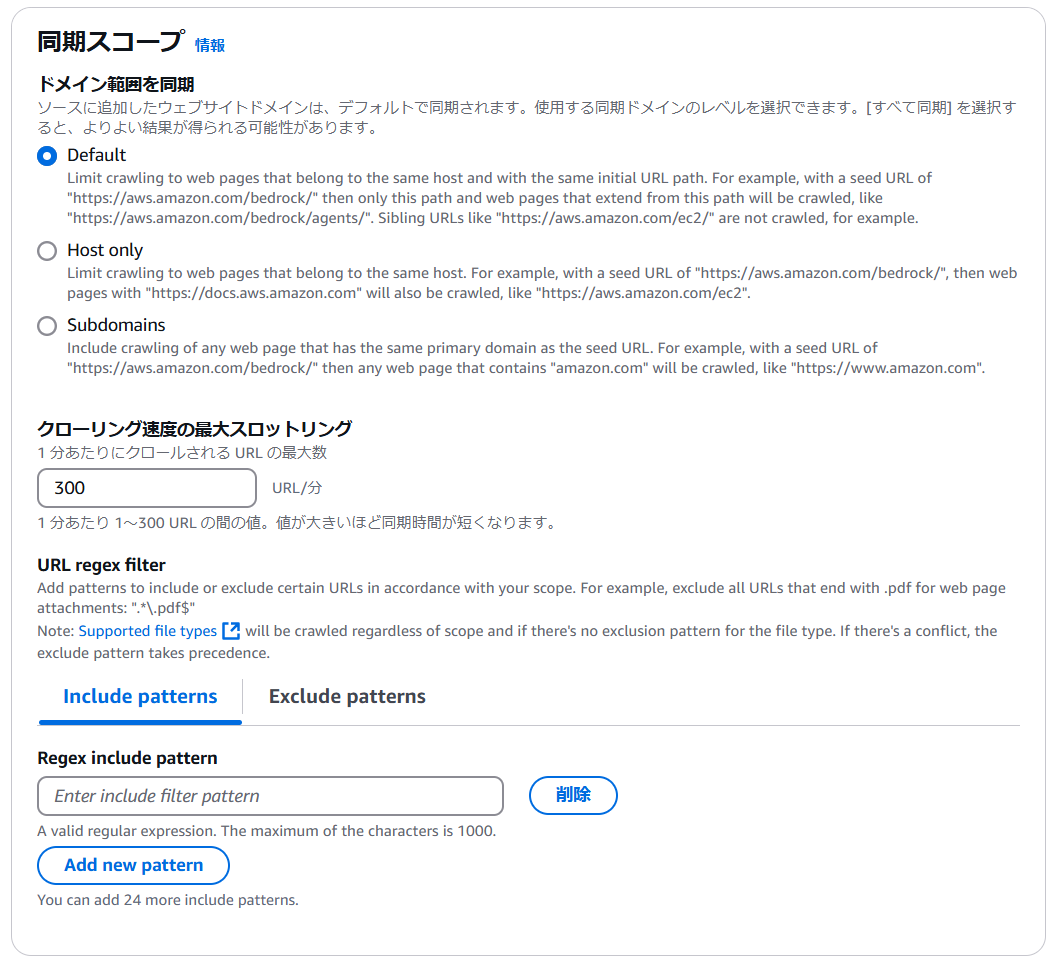
例えばドメイン範囲では、次のようなオプションを選択できます。
| オプション | 概要 |
|---|---|
| Default | 同じホストに属し、同じ初期 URL パスを持つ Web ページにクロールを制限します。たとえば、シード URL が「https://aws.amazon.com/bedrock/」の場合、このパスと、このパスから拡張された Web ページ (「https://aws.amazon.com/bedrock/agents/」など) のみがクロールされます。たとえば、「https://aws.amazon.com/ec2/」などの兄弟 URL はクロールされません。 |
| Host only | クロール対象を同じホストに属する Web ページに制限します。たとえば、シード URL が「https://aws.amazon.com/bedrock/」の場合、「https://docs.aws.amazon.com」を含む Web ページ (「https://aws.amazon.com/ec2」など) もクロールされます。 |
| Subdomains | シード URL と同じプライマリ ドメインを持つすべての Web ページのクロールを含めます。たとえば、シード URL が「https://aws.amazon.com/bedrock/」の場合、「https://www.amazon.com」のように「amazon.com」を含むすべての Web ページがクロールされます。 |
それ以外は今回はデフォルトのまま、[次へ] を選択します。
次に埋め込みモデルを選択します。今回は多言語に対応していることやコストなども考慮し、Amazon Titan Text Embeddings v2 を選択しました。

さらにベクトル値を格納するベクトルデータベースを選択します。
ここは注意が必要です。 Web クローラーをデータソースに選択した場合はベクトルデータベースとして Amazon OpenSearch Serverless を指定する必要があります。 当初、Amazon OpenSearch Serverless 以外をベクトルデータベースとして指定して作成しようとしたのですが、下記のエラーが表示されました。
データソース「kb-anycompany-news-web-ds」をナレッジベースに追加できませんでした。 WEB data source is currently only supported for knowledge bases created with an Amazon OpenSearch Serverless vector database.
そのため今回は、[新しいベクトルストアをクイック作成] を選択しました。ただし、Amazon OpenSearch Serverless を使用するコストには十分ご注意ください。 今回は、動作確認後にナレッジベースも Amazon OpenSearch Serverless も削除することにします。

それ以外は今回はデフォルトのまま、[次へ] を選択し、ナレッジベースを作成します。
作成が完了すると、次のようなメッセージが表示されます。

次に同期処理が必要になるので、[データソース] のセクションで作成したナレッジベースのチェックボックスをチェックして、[同期] を選択します。

同期の時間は対象データの量に依りますが、今回のクロール対象の Webサイトはさほどデータ量は多くないので数分待つと完了し、次のようなメッセージが表示されます。
![]()
これでナレッジベースが使えるようになりました。
では引き続きマネジメントコンソールを使用してテストしてみましょう。
ページ右側にある [ナレッジベースをテスト] で 推論に使うテキスト生成モデルを選択します。
その後、「AnyCompany 社の最新情報を教えてください」と問い合わせてみます。

上図は例ですが、Web サイトの情報から回答を出せていることがわかりますね!
回答の中には、[1] や [2] など、参照先を示すリンクもありますが、それらをクリックしても指定した Web サイトや Web サイトにリンクされている PDF ファイルを参照していることがわかります。
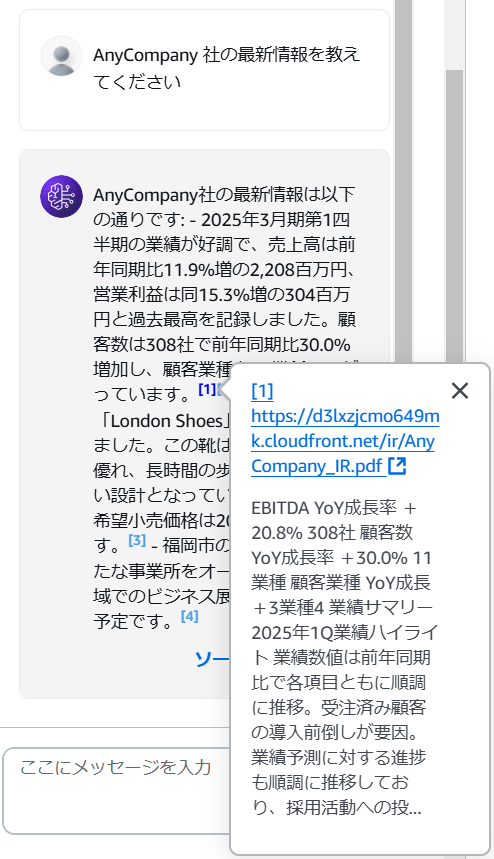
これで、Web クローラーが正しく動作していることが確認できました!
最後に
RAG の仕組みを実装する上では、使用したいドキュメントや情報が Amazon S3 バケットではなく、Web サイトに存在している場合もありえます。 Amazon Bedrock のナレッジベースの Web クローラーを今回試してみて、そういったケースではシンプルに使用できて非常に有益であると実感できました。
今回は基本的な機能だけを試してみましたが、下記のドキュメントに詳細が記載されているので、詳細を知りたい方はご参照ください。
ただし、2024年12月時点では Web クローラーはプレビューであることは十分、ご留意ください。
また、不要であればナレッジベースとそのベクトルデータベースは削除しましょう。Amazon OpenSearch Serverless の場合、OpenSearch のコンソールからコレクションやセキュリティの各種ポリシーも削除しておきましょう。
ではみなさん、よいクリスマスを!