仕事上、AWS 環境のリソースをマルチテナントで管理する手法について調査する機会があったのですが、「そういえば AWS Lambda でテナント分離モードって機能があったな」と思い出し、実際に試してみることにしました。
この記事に記載している内容は、2026年4月に検証した結果に基づいています。
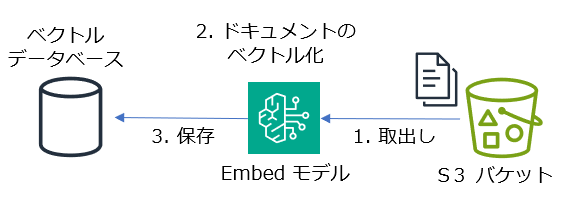
なお、AWS 環境における SaaS 環境の構築やマルチテナント管理については下記のドキュメントも参考になるので紹介しておきます。
目次
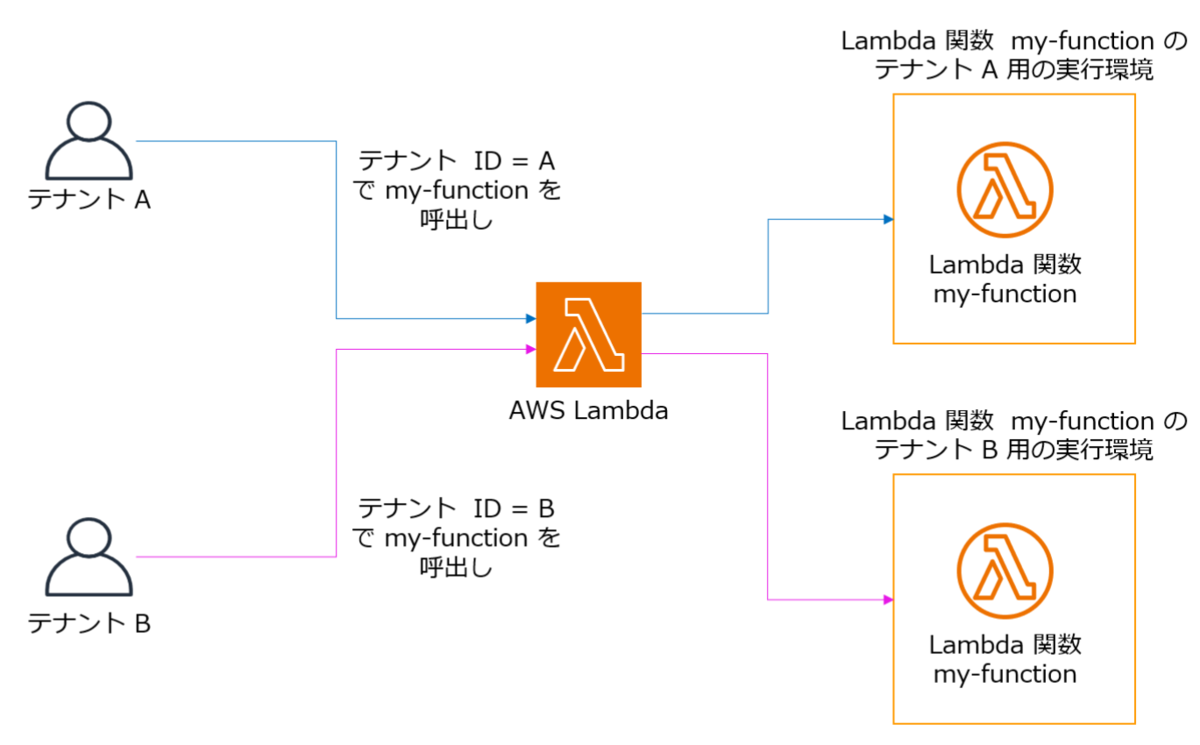
AWS Lambda のテナント分離モード
- AWS Lambda のテナント分離モードは 2025年11月に導入された機能ですが、それ以前までは SaaS のような環境でテナント別に Lambda 関数の実行環境を分離することはできませんでした。
- このテナント分離モードを指定することで、指定したテナントの ID 別に Lambda 関数の実行環境を分離することができます。
- ただしこの機能にはいくつか注意点があるので、記事の後半で説明します。
- AWS 公式のブログ記事でも、このテナント分離モードの紹介と簡単に試す手順が説明されています。
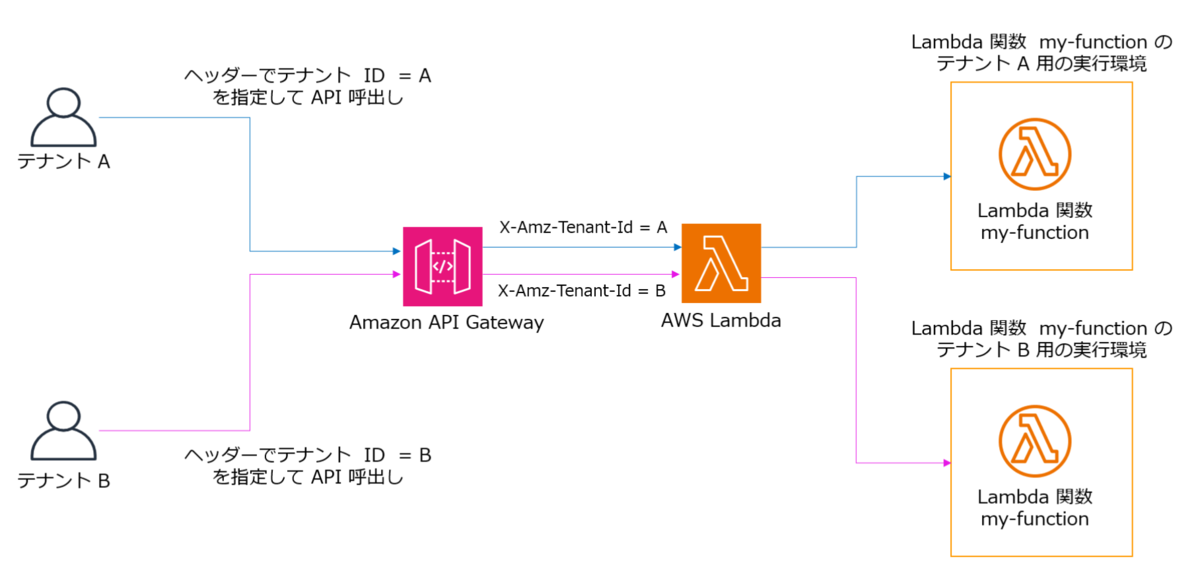
- 上記のブログ記事の内容をベースに、今回は Amazon API Gateway の REST API を使用し、リクエストヘッダーにテナントの ID を指定して REST API 経由でテナント分離モードの Lambda 関数を呼び出してみたいと思います。
Lambda 関数のコード
- 上記のブログ記事とほぼ全く同じです。テナント ID (tenant_id) は、Lambda 関数のハンドラーでコンテキストオブジェクトから取得します。
"""テナント分離モードが有効なLambda関数のハンドラー"""
tenant_id = context.tenant_id
- ただ、ログを出力するコード(下記)だけを追加しました。これにより、テナント毎に実行環境が異なるため、CloudWatch Logs のログループもテナント毎に異なることを確認したいと思います。
# ログ print(f"tenant_id: {tenant_id}, request_count: {data['request_count']}")
- コード全体は下記から参照できます。 aws-lambda-tenant-isolation/functions/app.py at main · tetsuo-nobe/aws-lambda-tenant-isolation · GitHub
AWS SAM テンプレート
- 上記の Lambda 関数を Amazon API Gateway の REST API と統合してデプロイするための SAM テンプレートです。
リクエストのヘッダー x-tenand-id を X-Amz-Tenant-Id にマップして Lambda 関数を呼び出します。ここがポイントですね。
下記はその部分の抜粋です。
# POSTメソッド(x-tenant-id ヘッダーを X-Amz-Tenant-Id にマッピング) TenantApiMethod: Type: AWS::ApiGateway::Method Properties: RestApiId: !Ref TenantApi ResourceId: !Ref TenantApiResource HttpMethod: POST AuthorizationType: NONE RequestParameters: method.request.header.x-tenant-id: true Integration: Type: AWS_PROXY IntegrationHttpMethod: POST Uri: !Sub arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${TenantIsolatedFunction.Arn}/invocations RequestParameters: integration.request.header.X-Amz-Tenant-Id: method.request.header.x-tenant-id
- テンプレート全体は下記から参照できます。 aws-lambda-tenant-isolation/template.yaml at main · tetsuo-nobe/aws-lambda-tenant-isolation · GitHub
実行確認
- AWS SAM でデプロイが完了したら、curl コマンドで呼び出します。
- まず テナント ID に tenant-A を指定して実行します。
curl -X POST https://abcdef1234.execute-api.ap-northeast-1.amazonaws.com/prod/process \
-H "Content-Type: application/json" \
-H "x-tenant-id: tenant-A" \
-d '{"action": "process"}'
- 結果
{ "message": "File contents for tenant-A (isolated per tenant)", "file_data": { "tenant_id": "tenant-A", "request_count": 1, "first_request": "2026-04-30T01:58:01.534762", "requests": [ { "request_number": 1, "timestamp": "2026-04-30T01:58:01.534787" } ] } }
- 続けて、再びテナント ID に tenant-A を指定して実行します。結果は下記のようになり、同一の実行環境が使用されるので、同じ /tmp/tenant_data.json ファイルにアクセスして、前回の結果を読み込めていることがわかります。
{ "message": "File contents for tenant-A (isolated per tenant)", "file_data": { "tenant_id": "tenant-A", "request_count": 2, "first_request": "2026-04-30T01:58:01.534762", "requests": [ { "request_number": 1, "timestamp": "2026-04-30T01:58:01.534787" }, { "request_number": 2, "timestamp": "2026-04-30T01:58:07.027854" } ] } }
- CloudWatch Logs で Lambda 関数の実行ログをみても、同一のロググループでログイベントが出力されていることがわかります。
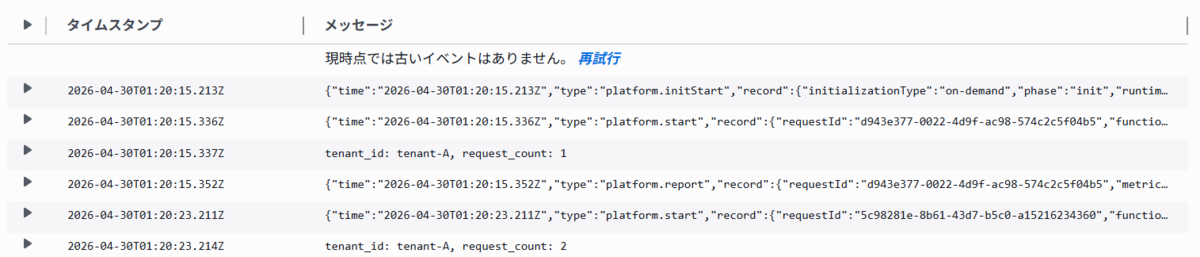
- 次にテナント ID に tenant-B を指定して実行します。テナント ID が異なるため、異なる実行環境が使用され、/tmp/tenant_data.json ファイルも異なり、テナント A で実行された結果が読み込まれていないことがわかります。
{ "message": "File contents for tenant-B (isolated per tenant)", "file_data": { "tenant_id": "tenant-B", "request_count": 1, "first_request": "2026-04-30T01:58:29.779452", "requests": [ { "request_number": 1, "timestamp": "2026-04-30T01:58:29.779484" } ] } }
- CloudWatch Logs で Lambda 関数の実行ログをみても、tenant_id に A を指定した場合と異なるロググループでログイベントが出力されていることがわかります。

単一の Lamda 関数でもテナント ID 別に実行環境が分離されていることを確認できました。
ちなみに、テナント ID を指定せずに実行すると、次のようなエラーになります。
{ "message": "The invoked function is enabled with tenancy configuration. Add a valid tenant ID in your request and try again." }
注意点
テナント分離モードを使うこと自体は難しくありませんが、以下のような 注意点 があるので意識しておきましょう。
- テナント分離モードは関数作成時にのみ設定可能です。既存の関数に対して後から有効化することはできません。
- テナント分離モード使用時は、コンソールや AWS CLI 、 AWS SDK のコードから テナント ID を指定して呼び出す必要があります。
- イベントソースとして他の AWS サービスと連携する場合は、Amazon API Gateway の REST API のみ使用できます。
- テナントごとに新しい実行環境が作成されるため、コールドスタートが増加する可能性があります。
- Amazon API Gateway と統合する場合は、REST API を使用しています。
- HTTP API ではヘッダーオーバーライドができないため、使用できません。
- テナント分離実行環境の作成時に追加料金が発生します。
- 詳細は AWS Lambda の料金 を参照してください。