Amazon SNS でサポートされた AWS X-Ray のアクティブトレースを試してみる
今回は、つい先日にアナウンスがあった Amazon SNS の下記の新しい機能を試してみます。
なお、この記事の内容は 2023 年 2 月 12 日時点の検証結果に基づいて記載しています。
何ができるようになったのか
これまでも、Amazon SNS トピックは、呼び出し先が AWS Lambda 関数または HTTP/HTTPS のエンドポイントの場合は、AWS X-Ray のトレースを取得するために必要なコンテキストを伝播することはできました。
そのため、下図のようにトピックを経由して AWS Lambda 関数を呼び出すまでの一連のフローを AWS X-Ray で可視化することはできました。
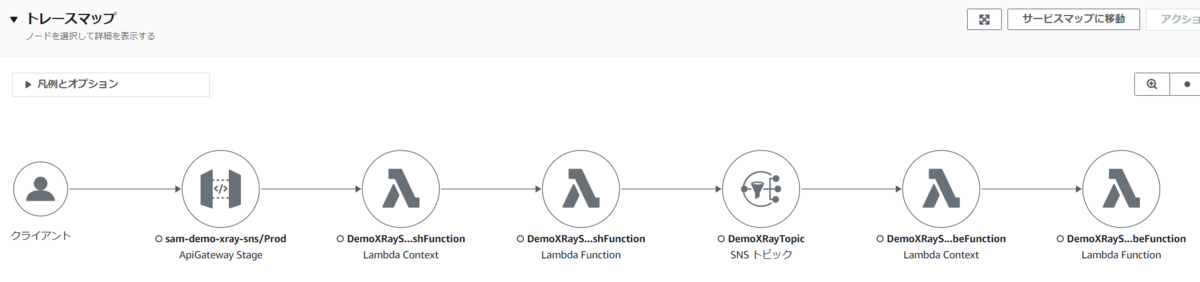
ただし、この場合、Amazon SNS のトピックは トレースのコンテキストを AWS Lambda 関数や HTTP/S のエンドポイントに伝播しているだけで、Amazon SNS のトピック自体は AWS X-Ray のトレースを出力することはできませんでした。
そのため、例えば トピックのサブスクライバーが Amazon SQS のキューの場合は、トピックからキューに対してメッセージを送信したときのトレースは取得できませんでした。
今回の Update で Amazon SNS トピックとしてどのような動作を行ったかを AWS X-Ray のトレースとして出力できるようになりました。
この機能を適用できるのは標準トピック だけで、FIFO トピックには適用できません。
また、トレース取得の対象にできるのは、サブスクライバーが 下記の場合のみです。
上記以外のEmail や SMS ( Short Message Service ) には適用できないことは留意しておきましょう。
それでは試してみましょう!
サブスクライバーが AWS Lambda 関数や Amazon SQS キュー、Email の構成で試してみる
Amazon SNS のトピックで X-Ray トレースの取得を有効化して、下図のような構成でトピックにメッセージを発行してみます。

AWS マネジメントコンソール での設定
X-Ray トレースの有効化は、AWS マネジメントコンソールの場合は トピックの設定ページの [編集] ボタンから行えます。
また、トピックの設定ページの 下部にある [統合] タブから有効化を確認できます。

取得したトレース
AWS マネジメントコンソールからトピックに対してメッセージを発行してトレースを取得して表示してみましょう。
今回は、Amazon CloudWatch のコンソールの左側のメニューで [ X-Ray トレース ] - [ トレース ] を選択して表示してみます。

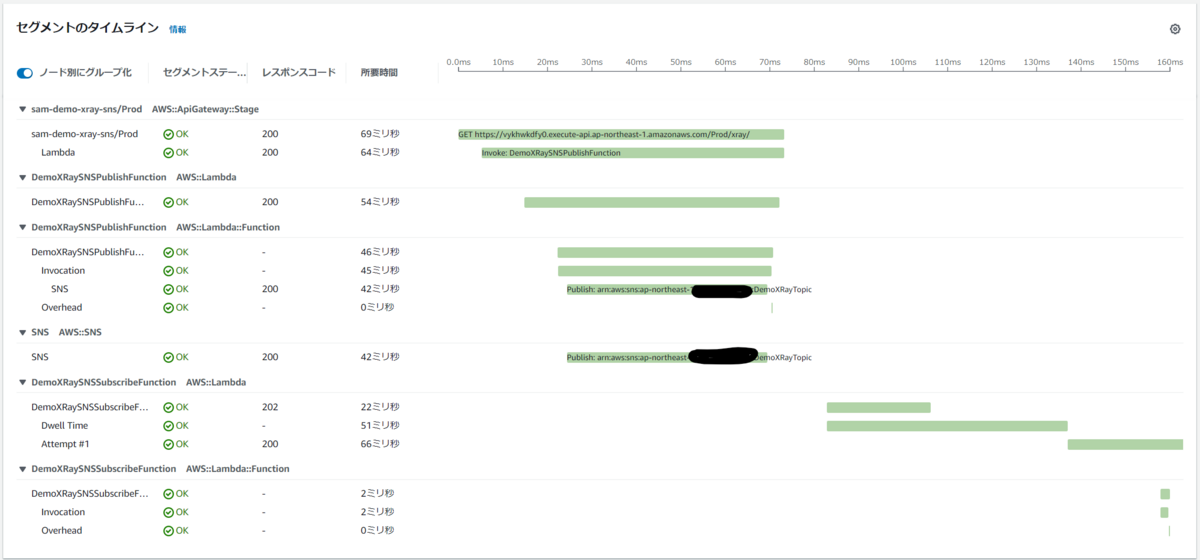
トレースマップでは、Amazon SNS トピックと サブスクライバーである Amazon SQS キューや、AWS Lambda 関数が表示されています。
セグメントのタイムラインでは、Amazon SNS が Amazon SQS キューに SendMessage API を発行、また AWS Lambda 関数を invoke する API を発行したことも表示され、その処理にかかった時間も表示されています。
実際はサブスクライバーとして Email も設定しメールも送信されているのですが、トレースには含まれていません。ただ Email はもともとトレース取得の対象外なので、これは想定通りですね。
次に、敢えて サブスクライバーとして設定している AWS Lambda 関数を削除してから トピックにメッセージを送信したときのトレースをみてみましょう。
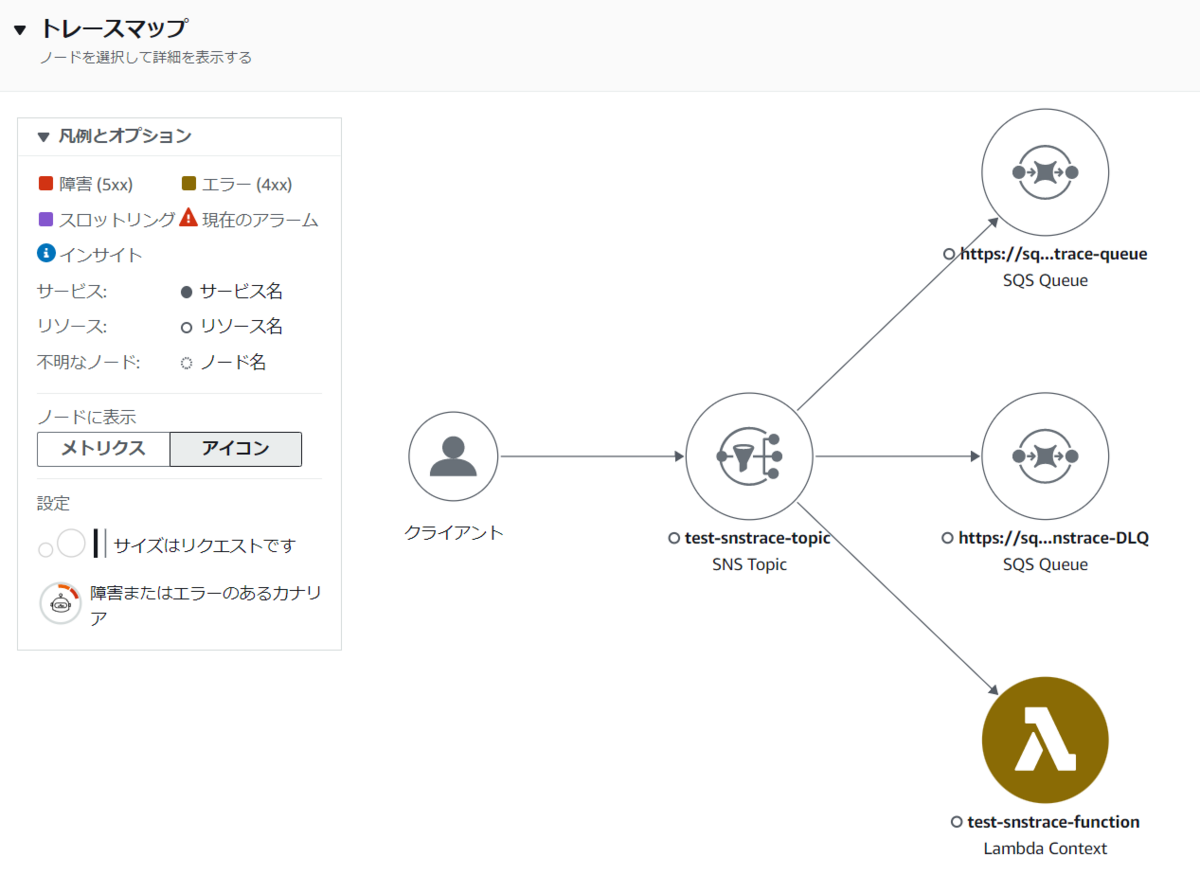
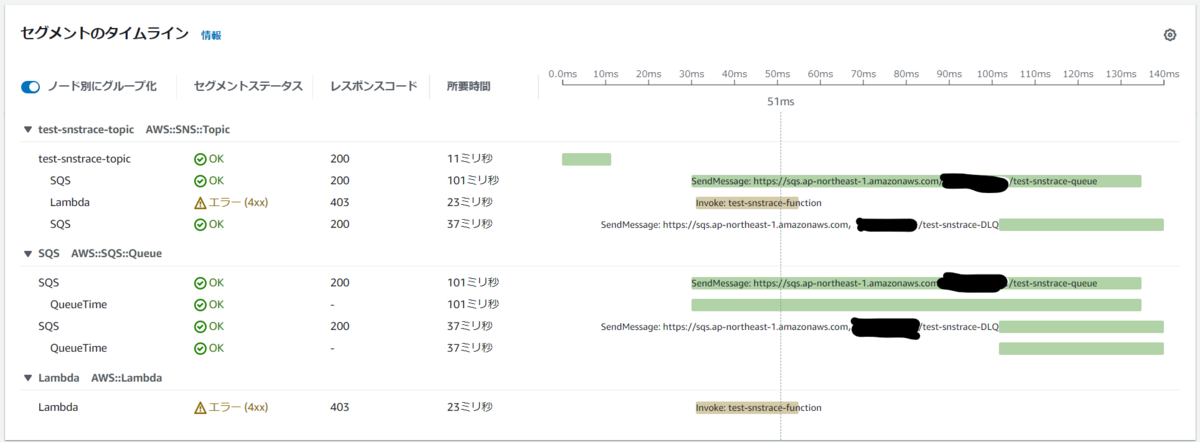
AWS Lambda 関数の invoke が エラーコード 403 で失敗していることがわかりますね。またそのため、サブスクリプションに設定した デッドレターキューに メッセージが送信されたこともわかります。
シンプルなファンアウトの構成で試してみる
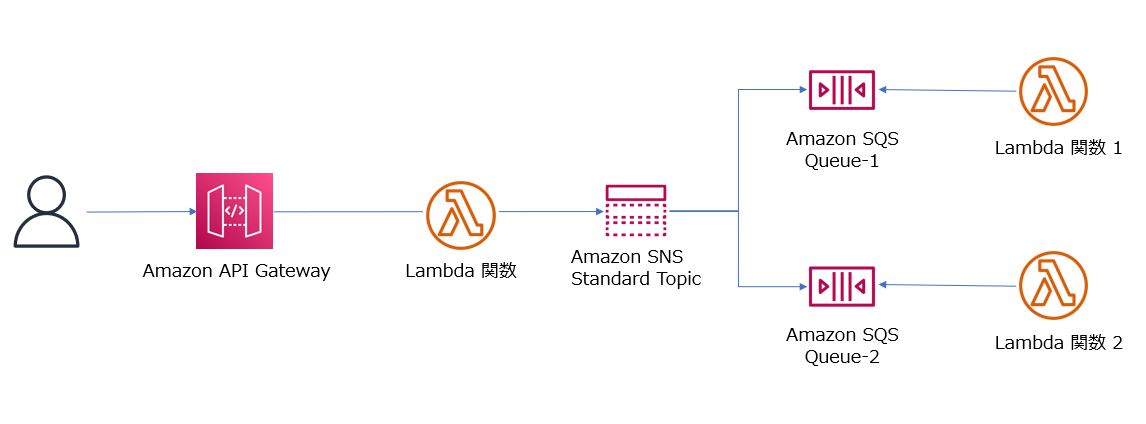
次に、Amazon SNS と Amazon SQS、AWS Lambda を組み合わせて下図のようなシンプルなファンアウトを実装した場合、AWS X-Ray ではどのようにトレースを可視化できるのかを試してみます。
使用する AWS Lambda 関数のコード
今回は、Python の Lambda 関数を使用します。下記は、Amazon SNS の標準トピックにメッセージを発行する Lambda関数です。
メッセージとして、ハンドラ関数の引数であるイベントオブジェクトを文字列化したものを送信する前提とします。
import json import boto3 import datetime import os from botocore.config import Config from aws_xray_sdk.core import patch patch(['boto3']) sns = boto3.client('sns') def lambda_handler(event, context): topic_arn = os.getenv('SNS_TOPIC_ARN') dt = datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S %Z') # Topicへメッセージ送信 response = sns.publish( TopicArn=topic_arn, Message=json.dumps(event), Subject='Message from Lambda Function ' + dt ) # return { "statusCode": 200, "body": json.dumps({ "message": "Done:"+ dt }), }
次は、トピックをサブスクライブしている Amazon SQS のキューからメッセージを取得する Lambda 関数です。
関数名とイベントオブジェクトをそのまま print 関数で出力するだけのシンプルな内容です。
ファンアウトではありますが、今回はキューからメッセージを取得する 2 つの Lambda 関数は同じコードを使用します。
import json import boto3 import datetime import os from botocore.config import Config from aws_xray_sdk.core import patch patch(['boto3']) def lambda_handler(event, context): print("Lambda function name:", context.function_name) print("-----") print(event) # return { "statusCode": 200, "body": json.dumps({ "message": "Done" }), }
なお、AWS X-Ray の SDK を使用していますが、AWS X-Ray SDK のパッケージは AWS Lambda レイヤーとして用意し、今回使用する全てのLambda 関数から共用する前提にしています。
シンプルなファンアウトを構築するための AWS SAM テンプレート
もちろん、AWS マネジメントコンソールから構築しても良かったんですが、再利用性を考え 今回は AWS SAM テンプレートで構築することにしました。
Amazon API Gateway のAPI 、AWS Lambda 関数、そして今回のテーマである Amazon SNS トピックと全て AWS X-Ray のトレース取得を有効化する前提です。
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > sam-demo-xray-fanout Sample SAM Template for sam-demo-xray-fanout Parameters: SNSTOPIC: Type: String Default: 'DemoXRayFanoutTopic' SQSQUEUE1: Type: String Default: 'DemoXRayFanoutQueue1' SQSQUEUE2: Type: String Default: 'DemoXRayFanoutQueue2' Globals: Function: Timeout: 15 Tracing: Active Layers: - !Ref DemoXRayLambdaLayer Api: TracingEnabled: True Resources: DemoXRayFanoutSNSPublishFunction: Type: AWS::Serverless::Function Properties: FunctionName: 'DemoXRayFanoutSNSPublishFunction' CodeUri: demo_xray_fanout_sns_publish_function/ Handler: app.lambda_handler Runtime: python3.8 Role: !GetAtt DemoXRayFunctionRole.Arn Environment: Variables: SNS_TOPIC_ARN: !GetAtt DemoXRayTopic.TopicArn Events: DemoXRayEvent: Type: Api Properties: Path: /xray Method: get DemoXRayFanoutSQSReceiveFunction1: Type: AWS::Serverless::Function Properties: FunctionName: 'DemoXRayFanoutSQSReceiveFunction1' CodeUri: demo_xray_fanout_sqs_receive_function/ Handler: app.lambda_handler Runtime: python3.8 Role: !GetAtt DemoXRayFunctionRole.Arn Events: DemoSQSEvent: Type: SQS Properties: Queue: !GetAtt DemoXRayQueue1.Arn BatchSize: 1 DemoXRayFanoutSQSReceiveFunction2: Type: AWS::Serverless::Function Properties: FunctionName: 'DemoXRayFanoutSQSReceiveFunction2' CodeUri: demo_xray_fanout_sqs_receive_function/ Handler: app.lambda_handler Runtime: python3.8 Role: !GetAtt DemoXRayFunctionRole.Arn Events: DemoSQSEvent: Type: SQS Properties: Queue: !GetAtt DemoXRayQueue2.Arn BatchSize: 1 DemoXRayLambdaLayer: Type: AWS::Serverless::LayerVersion Properties: LayerName: 'DemoXRayLambdaLayer' CompatibleRuntimes: - python3.8 ContentUri: demo_xray_layer/xray-python.zip DemoXRayFunctionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: "sts:AssumeRole" Principal: Service: "lambda.amazonaws.com" Policies: - PolicyName: "my-demo-xray-policy" PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: - "logs:*" - "sns:*" - "sqs:*" - "xray:PutTraceSegments" - "xray:PutTelemetryRecords" Resource: "*" DemoXRayTopic: Type: AWS::SNS::Topic Properties: TopicName: !Ref SNSTOPIC TracingConfig: Active DemoXRayQueue1: Type: AWS::SQS::Queue Properties: QueueName: !Ref SQSQUEUE1 DemoXRayQueue2: Type: AWS::SQS::Queue Properties: QueueName: !Ref SQSQUEUE2 DemoXRayTopicSubscription1: Type: 'AWS::SNS::Subscription' Properties: TopicArn: !Ref DemoXRayTopic Endpoint: !GetAtt - DemoXRayQueue1 - Arn Protocol: sqs RawMessageDelivery: 'true' DemoXRayTopicSubscription2: Type: 'AWS::SNS::Subscription' Properties: TopicArn: !Ref DemoXRayTopic Endpoint: !GetAtt - DemoXRayQueue2 - Arn Protocol: sqs RawMessageDelivery: 'true' DemoXRayQueuePolicy: Type: AWS::SQS::QueuePolicy Properties: Queues: - !Ref DemoXRayQueue1 - !Ref DemoXRayQueue2 PolicyDocument: Statement: - Action: - "SQS:SendMessage" Effect: "Allow" Resource: - !GetAtt DemoXRayQueue1.Arn - !GetAtt DemoXRayQueue2.Arn Principal: Service: - "sns.amazonaws.com" Condition: ArnLike: aws:SourceArn: - !GetAtt DemoXRayTopic.TopicArn DemoXRayResoucePolicy: Type: AWS::XRay::ResourcePolicy Properties: BypassPolicyLockoutCheck: True PolicyName: "PolicyforDemoXRayFanoutTopic" PolicyDocument: !Sub | { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "sns.amazonaws.com" }, "Action": [ "xray:PutTraceSegments", "xray:GetSamplingRules", "xray:GetSamplingTargets" ], "Resource": "*", "Condition": { "StringEquals": { "aws:SourceAccount": "${AWS::AccountId}" }, "StringLike": { "aws:SourceArn": "${DemoXRayTopic.TopicArn}" } } } ] } Outputs: DemoXRayFunctionApi: Description: "API Gateway endpoint URL for Prod stage " Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/xray/"
この AWS SAM テンプレートでポイントになる部分は 2つです。
1 つ目は、104 行目 (下記)です。
TracingConfig: Active
この Amazon SNS トピックの TracingConfig プロパティで Active を指定することで、AWS X-Ray トレースの取得を有効化します。
2 つ目は、153 行目から 183 行目で、AWS X-Ray のリソースベースのポリシーを作成している部分です。
AWS マネジメントコンソールから Amazon SNS トピックに対して トレースを有効化したときには自動的に AWS X-Ray のリソースベースのポリシーも設定してくれたのですが、AWS SAM などを使用する場合は、明示的に作成する必要があります。
また、このポリシーの内容については 158行目からの PolicyDocument で指定するのですが、このプロパティは Type (型)が String になっています。
そのため、例えば 89 行目にある IAM ロールのポリシードキュメントの記述方法が異なるので注意が必要です。
89行目からの IAM ロールのポリシードキュメントは、Type が Json なので、下記のように記述できます。
PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: - "logs:*" - "sns:*" - "sqs:*" - "xray:PutTraceSegments" - "xray:PutTelemetryRecords" Resource: "*"
しかし 153行目からの AWS X-Ray の リソースポリシーのポリシードキュメントは、Type が String なので、下記のように記述する必要があります。
PolicyDocument: !Sub | { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "sns.amazonaws.com" }, "Action": [ "xray:PutTraceSegments", "xray:GetSamplingRules", "xray:GetSamplingTargets" ], "Resource": "*", "Condition": { "StringEquals": { "aws:SourceAccount": "${AWS::AccountId}" }, "StringLike": { "aws:SourceArn": "${DemoXRayTopic.TopicArn}" } } } ] }
この SAM テンプレートをデプロイしてスタックを作成し、Amazon API Gateway の API のエンドポイント URL に GET リクエストを発行することで、今回のアプリケーションが実行され、AWS X-Ray トレースも取得されます。
取得したトレース
では、取得された AWS X-Ray トレースを AWS マネジメントコンソールからみてみましょう。
まずは、Amazon CloudWatch のページから表示した サービスマップ です。
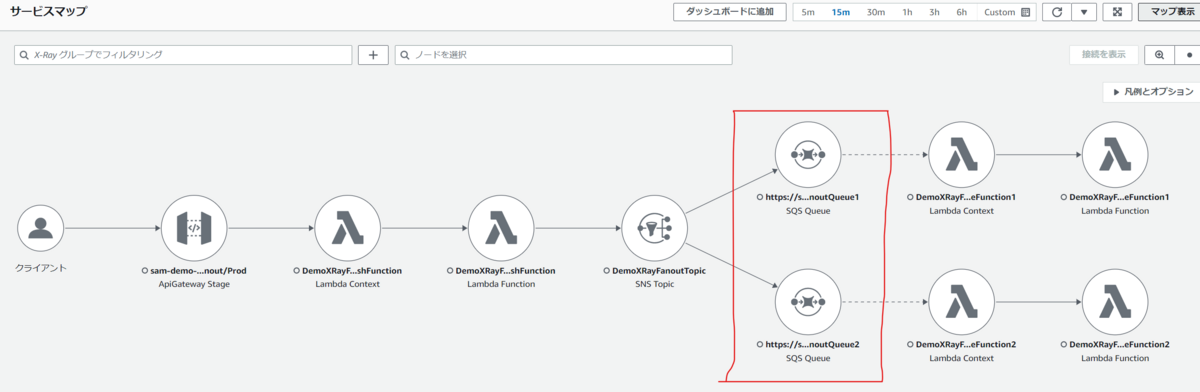
赤枠部分で、ファンアウトで Amazon SQS のキューが表示されていますね。そのキューから、さらに AWS Lambda コンテキストや AWS Lambda 関数が表示されていることがわかりますね。
これは、Amazon SNS トピックがサブスクライバーである Amazon SQS の 2 つのキューにメッセージを送信していることを示しており、そのキューをイベントソースにしている AWS Lambda 関数が実行されたこともわかります。
Amazon SQS のキューにいったんメッセージは入りますが、トレースはそこで途切れずに AWS Lambda 関数が実行されたところまでが1つのマップとして表示されています。これについては以前、ブログで記事にしたので下記を参考にしてみて下さい。
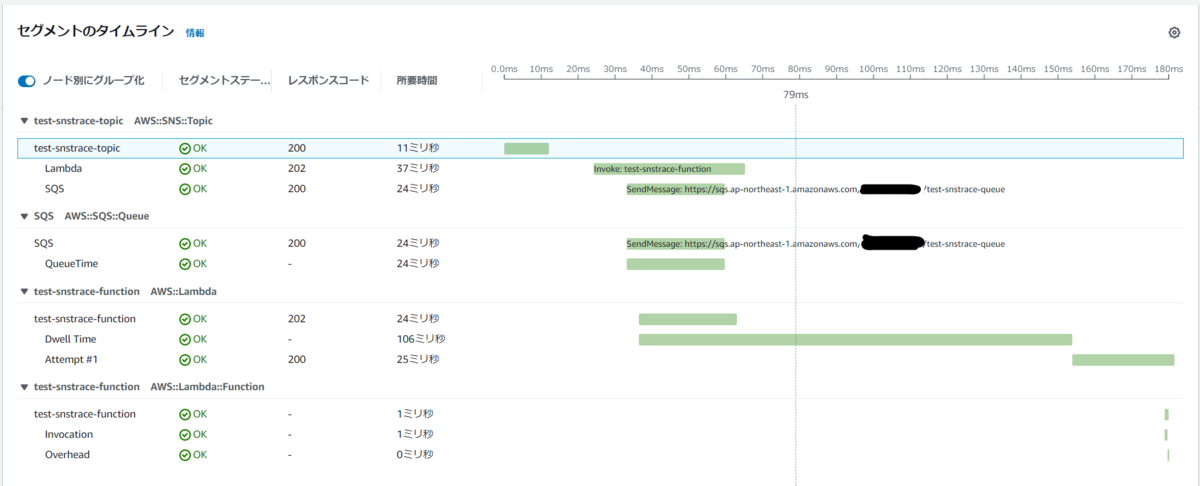
次に Amazon CloudWatch のページからトレースを選択して、トレースマップ をみてみます。
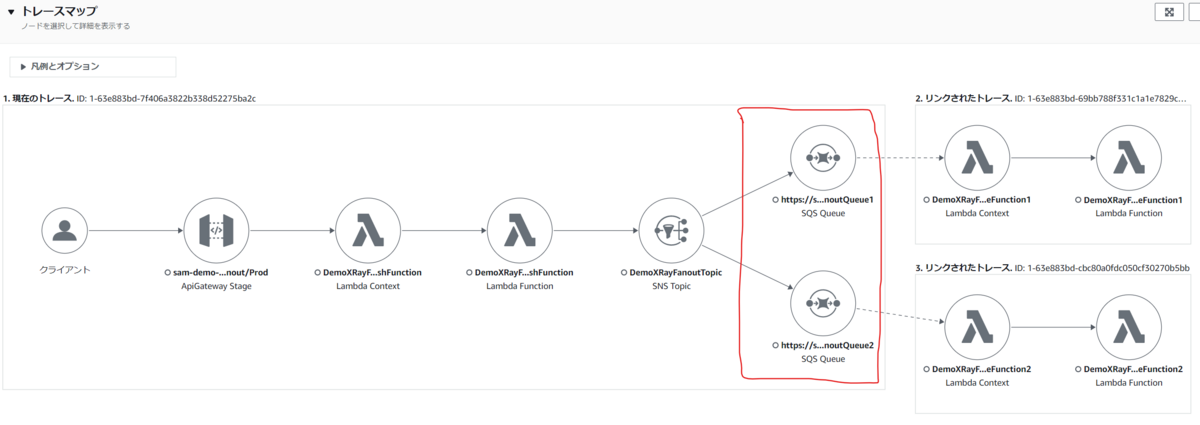
サービスマップと似ていますが、明示的に「現在のトレース」と「リンクされたトレース」を枠で分けて表示してくれていますね。
その下に表示される セグメントのタイムライン をみてみます。
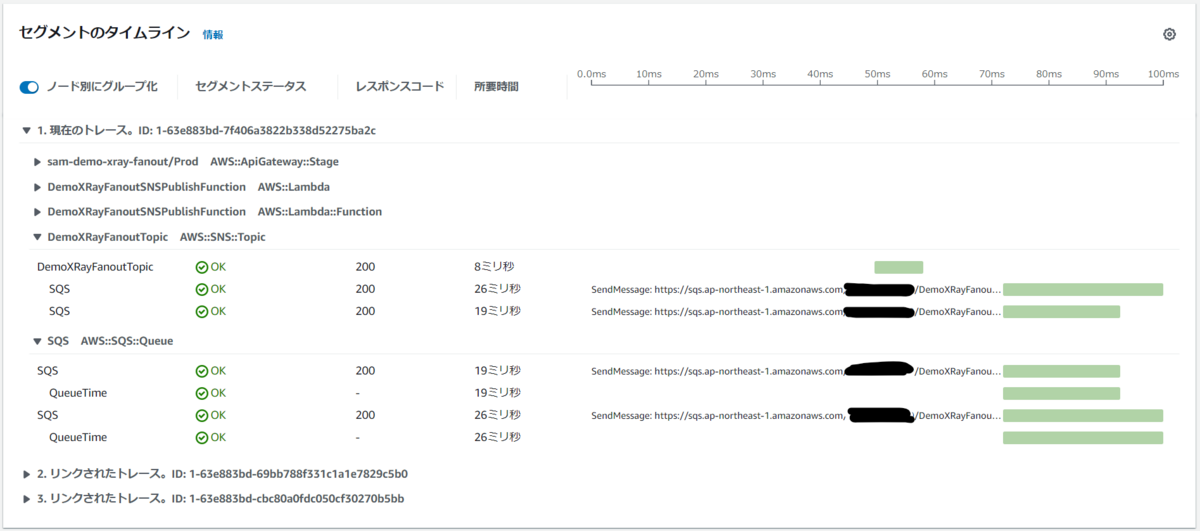
こちらも、明示的に「現在のトレース」と「リンクされたトレース」をわけて表示してくれていますね。
また、Amazon SNS のトピックをサブスクライブしている Amazon SQS の Queue について表示されており、トピックから SendMessage され、それが成功したこと、それらにかかった時間も確認できます。
最後に
これまでの Amazon SNS では AWS X-Ray については、正直、部分的な機能しかサポートされていないと感じていたのですが、今回の Update で Amazon SNS を使用したファンアウトのような構成を全体的に可視化できるようになったのは、とても便利だと感じました。
また、今回の検証を通じて、AWS X-Ray のリソースポリシーを AWS SAM ( AWS CloudFormation )で作成する方法も確認できたのも収穫でした!


Amazon Athena を AWS SDK for Python ( boto3 ) から使用してみる
前回の記事では、Amazon Athena を AWS CLI から操作してみましたが、今回は AWS SDK for Python 、つまり boto3 を使って Python のコードから Amazon Athena を操作してみます。
操作する内容は、前回の記事のAWS CLI で行った操作と同じことをやってみようと思います。
なお、この記事の内容は 2023年 1月時点で検証した結果に基づきます。
boto3 で Amazon Athena を操作するにあたって、参考にしたドキュメントは、もちろん boto3 の API リファレンスです。
boto3 の client オブジェクトを使用するので、前回の AWS CLI で使用したコマンドと一致するメソッドを見つけてコードを書けばよさそうです。
まずは、完成形を掲載します。
import boto3 import pprint workgroup_name = "my-workgroup-with-boto3" result_location = "s3://tnobe-datalake-athena-result/my-workgroup-with-boto3/" catalog_name = "AwsDataCatalog" database_name = "mydatabaseboto3" sql_create_database = "CREATE SCHEMA " + database_name sql_create_table = '''\ CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs ( \ LogDate DATE, \ Time STRING, \ Location STRING, \ Bytes INT, \ RequestIP STRING, \ Method STRING, \ Host STRING, \ Uri STRING, \ Status INT, \ Referrer STRING, \ ClientInfo STRING \ ) \ ROW FORMAT DELIMITED \ FIELDS TERMINATED BY '\t' \ LINES TERMINATED BY '\n' \ LOCATION 's3://athena-examples-ap-northeast-1/cloudfront/plaintext/' \ ''' sql_query = '''\ SELECT logdate, location, uri, status \ FROM cloudfront_logs \ WHERE method = 'GET' and status = 200 and location like 'SFO%' limit 10 \ ''' sql_drop_database = "DROP SCHEMA " + database_name client = boto3.client('athena') try: # ワークグループの作成 response = client.create_work_group( Name=workgroup_name, Configuration={ 'ResultConfiguration': { 'OutputLocation': result_location } }, Description='demo workgroup with boto3' ) # ワークグループの一覧表示 response = client.list_work_groups() print("--- Workgroup ---") pprint.pprint(response) # データベースの作成 response = client.start_query_execution( QueryString=sql_create_database, WorkGroup=workgroup_name ) # データベースの一覧表示 response = client.list_databases( CatalogName=catalog_name ) print("--- Database ---") pprint.pprint(response) # テーブルの作成 response = client.start_query_execution( QueryString=sql_create_table, QueryExecutionContext={ 'Database': database_name, 'Catalog': catalog_name }, WorkGroup=workgroup_name ) # クエリーの発行 response = client.start_query_execution( QueryString=sql_query, QueryExecutionContext={ 'Database': database_name, 'Catalog': catalog_name }, WorkGroup=workgroup_name ) # QueryExecutionId の取得 query_exec_id = response["QueryExecutionId"] # クエリーが終了するまで待機 status = "" while status != "SUCCEEDED": response = client.get_query_execution( QueryExecutionId=query_exec_id ) status = response["QueryExecution"]["Status"]["State"] print(status) # クエリーの結果取得 response = client.get_query_results( QueryExecutionId=query_exec_id ) print("--- Query Result ---") pprint.pprint(response) except Exception as e: print(e) finally: print("--- Drop Database ---") response = client.start_query_execution( QueryString=sql_drop_database, WorkGroup=workgroup_name ) print("--- Delete Workgroup ---") response = client.delete_work_group( WorkGroup=workgroup_name, RecursiveDeleteOption=True ) print("--- END ---")
このコードのポイント部分をみていきます。
最初は、6 行目と 7行目(下記)です。
database_name = "mydatabaseboto3" sql_create_database = "CREATE SCHEMA " + database_name
上記のように、AWS CLI 使用時と同じくデータベース作成時に CREATE DATABASE ではなく、CREATE SCHEMA を使用しなければエラーになります。、
これは、データベース削除時も同じで DROP DATABASE ではなく DROP SCHEMA にする必要があります。
また、データベース名に ハイフン (-) を含めることができません。
次に、86 行目から 93 行目(下記)に注目して下さい。
# クエリーが終了するまで待機
status = ""
while status != "SUCCEEDED":
response = client.get_query_execution(
QueryExecutionId=query_exec_id
)
status = response["QueryExecution"]["Status"]["State"]
print(status)
AWS CLI を使用する時は 1 つ 1 つのコマンドの実行の間に時間があったので問題なかったのですが、Python のコードでクエリー発行から結果取得まで一気に行うと、まだクエリーが完了していない状態で結果を取得しようとしてしまうこともあり、下記のエラーが発生します。
An error occurred (InvalidRequestException) when calling the GetQueryResults operation: Query has not yet finished. Current state: QUEUED
よって、get_query_execution メソッドを使用してクエリーのステータスが SUCCEEDED になるまで待機してから結果を取得するようなコードにしています。
ループで待機せず、Waiter のような自動的に待機してくれる方法があればいいのですが、見当たらなかったため、致し方なく while ループを使いました。
ちなみに、ステータスとしては、クエリー発行後は QUEUED 、クエリー実行中は RUNNING、クエリーが成功したら SUCCEEDED となります。
この Python のコードを実行すると、Amazon Athena のワークグループの一覧、データベースの一覧、クエリ結果が表示されます。
下記は、クエリ結果部分を抜粋した内容です。
--- Query Result --- {'ResponseMetadata': {'HTTPHeaders': {'connection': 'keep-alive', 'content-length': '2183', 'content-type': 'application/x-amz-json-1.1', 'date': 'Sun, 22 Jan 2023 08:18:03 GMT', 'x-amzn-requestid': '216f5ef6-8e7c-479a-976a-1c5dcb43bedd'}, 'HTTPStatusCode': 200, 'RequestId': '216f5ef6-8e7c-479a-976a-1c5dcb43bedd', 'RetryAttempts': 0}, 'ResultSet': {'ResultSetMetadata': {'ColumnInfo': [{'CaseSensitive': False, 'CatalogName': 'hive', 'Label': 'logdate', 'Name': 'logdate', 'Nullable': 'UNKNOWN', 'Precision': 0, 'Scale': 0, 'SchemaName': '', 'TableName': '', 'Type': 'date'}, {'CaseSensitive': True, 'CatalogName': 'hive', 'Label': 'location', 'Name': 'location', 'Nullable': 'UNKNOWN', 'Precision': 2147483647, 'Scale': 0, 'SchemaName': '', 'TableName': '', 'Type': 'varchar'}, {'CaseSensitive': True, 'CatalogName': 'hive', 'Label': 'uri', 'Name': 'uri', 'Nullable': 'UNKNOWN', 'Precision': 2147483647, 'Scale': 0, 'SchemaName': '', 'TableName': '', 'Type': 'varchar'}, {'CaseSensitive': False, 'CatalogName': 'hive', 'Label': 'status', 'Name': 'status', 'Nullable': 'UNKNOWN', 'Precision': 10, 'Scale': 0, 'SchemaName': '', 'TableName': '', 'Type': 'integer'}]}, 'Rows': [{'Data': [{'VarCharValue': 'logdate'}, {'VarCharValue': 'location'}, {'VarCharValue': 'uri'}, {'VarCharValue': 'status'}]}, {'Data': [{'VarCharValue': '2014-08-05'}, {'VarCharValue': 'SFO4'}, {'VarCharValue': '/test-image-3.jpeg'}, {'VarCharValue': '200'}]}, (・・・中略・・・) {'Data': [{'VarCharValue': '2014-08-05'}, {'VarCharValue': 'SFO4'}, {'VarCharValue': '/test-image-2.jpeg'}, {'VarCharValue': '200'}]}]}, 'UpdateCount': 0}
上記結果の 50 行目以降で、クエリー結果のデータを表示することができていますね。
なお、このサンプルのコードでは、finally 句を使用して最後に Amazon Athena で作成したデータベースやワークグループを削除していますが、これは単に環境をクリアしておきたいという意図があるだけです。
最後に:
Amazon Athena を AWS CLI から使用してみる
今回は、AWS CLI を使って Amazon Athena のデータベースとテーブル、ワークグループを作成し、クエリーを発行してみます。
標準 SQL を使用して Amazon S3のバケット内のデータに対して直接クエリーを発行して集計や分析が行えるインタラクティブなサービスです。
AWS マネジメントコンソールを使用して容易に操作することもできますが、AWS CLI だとどのようなコマンドになるのか試してみます。
なお、この記事の内容は 下記のドキュメントを参考に、2023年 1月に検証した内容に基づいています。Linux で AWS CLI v2 を使用する前提とします。
Amazon Athena には ワークグループ というグルーピングの概念があり、ワークグループ単位で処理できるデータ量や Amazon CloudWatch のメトリクスの設定などを行えます。
デフォルトでも primary というワークグループがあり、それを使用できますが今回は新たにワークグループ my-workgroup を作成する前提とします。
まず、ワークグループで発行したクエリ結果を保存するための Amazon S3 のバケットとフォルダをあらかじめ作成しておきます。
ここでは、バケット tnobe-datalake-athena-result のフォルダ my-workgroup とします。
次に AWS CLI でワークグループ my-workgroup を作成します。
# ワークグループの作成 aws athena create-work-group \ --name my-workgroup \ --configuration ResultConfiguration={OutputLocation="s3://tnobe-datalake-athena-result/my-workgroup/"} \ --description "demo workgroup"
今回は、クエリーの結果の保存先以外の設定はデフォルトのままにしています。
ワークグループの作成を確認するため、次の AWS CLI コマンドを発行します。
# ワークグループの一覧表示
aws athena list-work-groups
下記のように、primary の他に my-workgroup が表示されていれば OK です。
{
"WorkGroups": [
{
"Name": "my-workgroup",
"State": "ENABLED",
"Description": "demo workgroup",
"CreationTime": "2023-01-09T03:12:47.798000+00:00",
"EngineVersion": {
"SelectedEngineVersion": "AUTO",
"EffectiveEngineVersion": "Athena engine version 2"
}
},
{
"Name": "primary",
"State": "ENABLED",
"Description": "",
"CreationTime": "2022-12-22T23:20:09.520000+00:00",
"EngineVersion": {
"SelectedEngineVersion": "AUTO",
"EffectiveEngineVersion": "Athena engine version 2"
}
}
]
}
では次に データベースを作成します。今回は mydatabase という名前にします。
# データベースの作成 aws athena start-query-execution \ --query-string "CREATE SCHEMA mydatabase" \ --work-group "my-workgroup"
作成したデータベースを確認します。
# データベースの一覧表示 aws athena list-databases --catalog-name AwsDataCatalog
環境によっては複数のデータベースが表示されますが、下記のように mydatabase が表示されれば OK です。
{
"Name": "mydatabase"
}
ここであることに気づきました。
AWS マネジメントコンソールにて、Amazon Athena のクエリエディタからデータベースを作成する場合は、次のコマンドで作成できます。
CREATE DATABASE mydatabase
しかし、AWS CLI の start-query-execution コマンドを使用して上記データベースを作成する SQL を発行すると、次のようなエラーが発生します。
An error occurred (InvalidRequestException) when calling the StartQueryExecution operation: line 1:8: mismatched input 'database'. Expecting: 'OR', 'SCHEMA', 'TABLE', 'VIEW'
つまり、CREATE DATABASE が使えないという事ですね。
しかし、次のドキュメントに、CREATE DATABASE は CREATE SCHEMA と同じでどちらでも使用できると記載されています。
よって今回は CREATE SCHEMA を使用しました。
また、データベースの名前を my-database のように ハイフン (-) を含んだ名前にすると次のようなエラーになります。
An error occurred (InvalidRequestException) when calling the StartQueryExecution operation: line 1:17: mismatched input '-'. Expecting: '.', 'WITH', <EOF>
これも AWS マネジメントコンソールでは発生しないエラーなので、少しハマってしまいました。
このように、AWS CLI ならではの書き方が必要なケースがあるので、注意が必要です。
データベースが作成できたら、次はテーブルを作成します。
今回は、Amazon Athena のチュートリアル用として公開されている CloudFrontへのアクセスログデータを使用します。
# テーブルの作成 aws athena start-query-execution \ --query-string \ "CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs ( \ LogDate DATE, \ Time STRING, \ Location STRING, \ Bytes INT, \ RequestIP STRING, \ Method STRING, \ Host STRING, \ Uri STRING, \ Status INT, \ Referrer STRING, \ ClientInfo STRING \ ) \ ROW FORMAT DELIMITED \ FIELDS TERMINATED BY '\t' \ LINES TERMINATED BY '\n' \ LOCATION 's3://athena-examples-ap-northeast-1/cloudfront/plaintext/'" \ --query-execution-context Database=mydatabase
テーブルを作成したら、さっそくクエリーを発行してみます。
aws athena start-query-execution \ --query-string "select logdate, location, uri, status from cloudfront_logs where method = 'GET' and status = 200 and location like 'SFO%' limit 10" \ --work-group "my-workgroup" \ --query-execution-context Database=mydatabase
クエリーを発行すると次のような ID 値が返されるので、メモしておきます。
{
"QueryExecutionId": "0df4e7c9-b9f7-46cf-92f0-42344cdfce23"
}
この ID 値を指定して、クエリーの結果を取得します。
aws athena get-query-results \ --query-execution-id 0df4e7c9-b9f7-46cf-92f0-42344cdfce23
次のように、カラム名とクエリーの結果が表示されれば OK です。
{
"ResultSet": {
"Rows": [
{
"Data": [
{
"VarCharValue": "logdate"
},
{
"VarCharValue": "location"
},
{
"VarCharValue": "uri"
},
{
"VarCharValue": "status"
}
]
},
{
"Data": [
{
"VarCharValue": "2014-07-05"
},
{
"VarCharValue": "SFO4"
},
{
"VarCharValue": "/test-image-2.jpeg"
},
{
"VarCharValue": "200"
}
]
},
{
"Data": [
{
"VarCharValue": "2014-07-05"
},
{
"VarCharValue": "SFO4"
},
{
"VarCharValue": "/test-image-2.jpeg"
},
{
"VarCharValue": "200"
}
]
},
・・・(以下略)・・・
最後に
AWS CLI ならではの書き方のところは要注意ですが、コマンドの種類もそんなに多くなく、パラメータの書き方もさほど複雑ではないので思いのほかシンプルに記述できた、というのが感想です!
AWS SAM で Open API の API 仕様を使って Amazon API Gateway の REST API を作成する
Amazon API Gateway では、 Open API 仕様(OpenAPI-Specification)をインポートすることで REST API を作成できます。
例えば、/order のパスで POST リクエストを受け付ける API を Open API 仕様に基づきファイルに記述しておくと、AWS CLI のコマンドにて API Gateway の REST API としてインポートできます。
ただし、その API から AWS Lambda 関数を呼び出すための、いわゆる 統合 の設定については Amazon API Gateway 固有のものであり、Open API 仕様には含まれていません。
それを実現するためには、Open API の仕様に対する API Gateway 拡張という記述方法があるので、それを使用します。
一方、AWS Lambda 関数や Amazon API Gateway の API をコードからデプロイするには、AWS SAM という強力なツールも存在します。
そこで今回は、Open API 仕様をベースに API をデザインして、それを AWS SAM を使用して Amazon API Gateway の REST API としてデプロイしてみたいと思います。
この REST API から呼び出す AWS Lambda 関数も 同じ AWS SAM テンプレートで作成する前提です。
(この記事の内容は、2023年 1月に検証した内容を基に記載しています。)
使用する Open API 仕様
今回は、/hello のパスで GET リクエストを発行すると、Python で記述した AWS Lambda関数を呼び出す API を作ります。
使用する Open API 仕様は下記です。これを demo-openapi.yaml として保存します。
openapi: "3.0.1" info: title: "demo-sam-openapi-api" version: "v1" paths: /hello: get: responses: "200": description: "200 response" content: application/json: schema: $ref: "#/components/schemas/Empty" x-amazon-apigateway-integration: httpMethod: "POST" uri: Fn::Sub: "arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${DemoSamOpenApiFunction.Arn}/invocations" responses: default: statusCode: "200" passthroughBehavior: "when_no_match" contentHandling: "CONVERT_TO_TEXT" type: "aws_proxy" components: schemas: Empty: title: "Empty Schema" type: "object"
上記中で、x-amazon-apigateway-integration: で指定している箇所が Amazon API Gateway の拡張部分で、AWS Lambda 関数とのプロキシ統合を指定しています。
プロキシ統合の対象、つまり呼び出す AWS Lambda 関数自体も 同じ AWS SAM テンプレートで作成するため、uri: で指定する AWS Lambda 関数の ARN は組込み関数 Sub を用いて設定しています。
使用する AWS SAM テンプレート
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > sam-openapi Sample SAM Template for sam-openapi Globals: Function: Timeout: 3 Resources: DemoSamOpenApi: Type: AWS::Serverless::Api Properties: Name: demo-sam-openapi-api StageName: Prod EndpointConfiguration: Type: REGIONAL DefinitionBody: Fn::Transform: Name: AWS::Include Parameters: Location: demo-openapi.yaml DemoSamOpenApiFunction: Type: AWS::Serverless::Function Properties: FunctionName: demo-sam-openapi-function CodeUri: hello_world/ Handler: app.lambda_handler Runtime: python3.7 Events: DemoSamOpenApiEvent: Type: Api Properties: Path: /hello Method: get RestApiId: !Ref DemoSamOpenApi Outputs: DemoSamOpenApi: Description: "API Gateway endpoint URL for Prod stage for DemoSamOpenApiFunction" Value: !Sub "https://${DemoSamOpenApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/" DemoSamOpenApiFunction: Description: "DemoSamOpenApiFunction ARN" Value: !GetAtt DemoSamOpenApiFunction.Arn DemoSamOpenApiFunctionIamRole: Description: "Implicit IAM Role created for DemoSamOpenApiFunction" Value: !GetAtt DemoSamOpenApiFunctionRole.Arn
上記テンプレートでは、Resources: にある DemoSamOpenApi で API を定義しています。
その中で、Open API 仕様のファイルを指定します。
Open API 仕様のファイル ( demo-openapi.yaml ) は、この AWS SAM テンプレートのファイルと同じ場所にコピーしておきます。
なお今回は、AWS SAM テンプレート のファイルと Open API の仕様のファイルを別にしてローカルで保存していますが、Open API の仕様をそのまま AWS SAM テンプレートの中に記述することもできます。
その他の方法として、Open API の仕様ファイルを Amazon S3 バケットに保存して、AWS SAM テンプレートから その S3 の URI を指定することもできます。
AWS Lambda 関数は、今回の例では AWS SAM プロジェクトのフォルダに hello_world/ フォルダを作成し、そこに下記の Python の AWS Lambda 関数のコードを app.py として保存しています。
これは、hello world を返すだけのシンプルなコードです。
import json def lambda_handler(event, context): return { "statusCode": 200, "body": json.dumps({ "message": "hello world", }), }
AWS SAM テンプレートのデプロイと 結果確認
テンプレートの検証とビルドを行い、その後デプロイします。
sam validate
sam build
sam deploy --guided
上記では --guided オプションをつけて sam deploy を実行しているので、その後 対話式でデプロイが進みます。下記の時だけ y を入力します。それ以外はデフォルトのままで大丈夫です。
DemoSamOpenApiFunction may not have authorization defined, Is this okay? [y/N]:
デプロイが完了すると、出力された中で Key が DemoSamOpenApi の Value で示されている URL を Web ブラウザでアクセスします。
下記は例です。
Key DemoSamOpenApi Description API Gateway endpoint URL for Prod stage for DemoSamOpenApiFunction Value https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/
その結果、下記のような hello world のメッセージが表示されれば成功です。
{"message": "hello world"}
やってみた所感
さて、今回やってみて成功したのですが、ひとつだけ気になる部分があります。
それは、AWS SAM テンプレートのリソースで AWS Lambda 関数の Events: の指定です。
この Events: で指定している内容は、Open API 仕様の中で指定している内容と同じなので、二重定義になってしまいます。
であれば、この Events: を記述しなければいい、という発想になるのですが、記述しない場合、Amazon API Gateway の API からのアクセスを許可するという AWS Lambda 関数のリソースベースのポリシーが作成されません。
ではでは、そのポリシーを作成するように自分で明示的に記述すればいいではないかという発想になります。
確かに、下記のようなポリシー定義を AWS SAM テンプレートに追記することで Events: の記述は不要になります。
DemoSamOpenApiFunctionPermission: Type: "AWS::Lambda::Permission" Properties: Action: lambda:InvokeFunction FunctionName: !Ref DemoSamOpenApiFunction Principal: apigateway.amazonaws.com
ただし、上記のような記述でデプロイすると、AWS Lambda 関数のトリガーとして Amazon API Gateway の API が認識されず、AWS マネジメントコンソールで AWS Lambda 関数のページを表示した場合、トリガーが表示されません。

それでも気にしない、運用上問題ない、ということであればよいのですが、どこか気持ち悪さを感じますよね。
よって、ポリシーも(自動)作成して、かつAWS Lambda 関数のトリガーとして Amazon API Gateway の API を認識させたい場合は、 Events: を記載するのが良いかもしれません。
ただ、Open API 仕様で記述した内容と同じような内容を再び記述することになるので、混乱せず注意して記述するようにしましょう。
AWS Cloud9 の デバッグ機能をさわってみる
今回は AWS Cloud9 のデバッグ機能の基本的な使い方をまとめたいと思います。
AWS Cloud9は、ブラウザのみでコードを記述、実行、デバッグできる統合開発環境 (IDE) です。
Cloud9 には、あらかじめ AWS CLI や AWS SAM、AWS CDK などの 主要な AWS のコマンドラインツールや、主要なプログラミング言語のランタイム、Git や Docker もインストールされており、短時間で環境をプロビジョニングできるので、私も重宝してます。
この Cloud9 でデバッグをサポートしているプログラミング言語は、次のドキュメントに記載されています。
Python や Node.js、PHP、Java などがサポートされていますね。
今回は、Python のシンプルなプログラミングを使用してデバッグ機能を試していきます。
なお、この記事の内容は 2022年 12月に検証した内容を基にしています。
def add(num1, num2): return num1 + num2 a = 2 b = 8 result = add(a,b) if result == 10: print('ten!') print(result)
最初に addという足し算を行う関数を定義し、それを呼出し、結果が 10かどうかを確認します。10なら ten! というメッセージを表示しますが、10以外なら表示しません。そして最後に足し算の結果を表示します。非常にシンプルですね。
これを Cloud9 で calc.py というファイルに保存しておきます。
ブレークポイントの設定
では、この calc.py のコードにブレークポイントを設定してみます。
ブレークポイントを設定すると、デバッグ実行時にその設定したコードでいったん停止して、変数の状況などを確認できます。
Cloud9 では、行番号の左側をクリックすることで、ブレークポイントの設定や解除が行えます。
今回は、下図のように 4 行目 の a = 2 のコードに設定します。設定すると、ピンク色の丸印がつきます。

デバッグ実行
次にデバッグ実行をしていきます。Cloud9 でデバッグ実行していく方法はいくつかありますが、今回は手っ取り早く実行する方法を紹介します。
まず、Cloud9 のメニューで Run をクリックして、デバッグではない通常の実行を行います。

すると Cloud9 の画面下部に結果が表示されますが、その中に 虫のアイコン が表示されているので、それをクリックして虫アイコンに色がついた状態にします。
このクリックにより、calc.py の実行をデバッグモードに切り替えることができます。
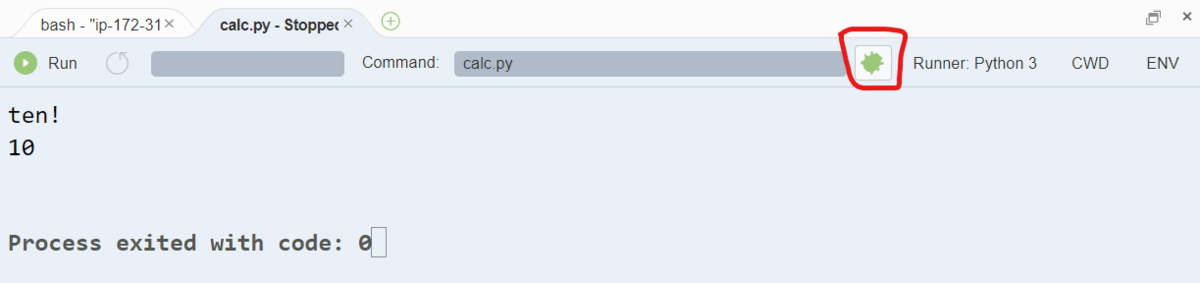
その後、再び Run メニューをクリックすると、デバッグモードで実行することができます。
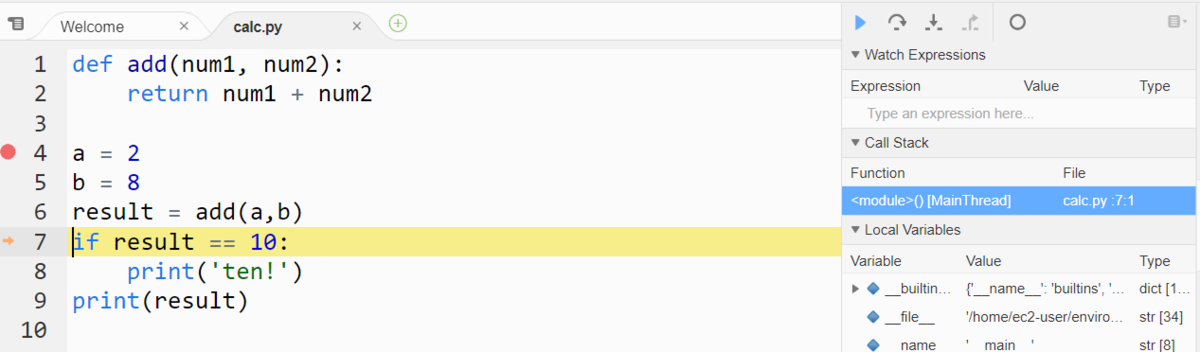
Step Overと変数の内容の表示
デバッグ実行すると、ブレークポイントを設定した 4 行目の a = 2 で 実行が停止状態になります。
この状態で、Cloud9 の画面の右側に表示されている Debugger メニューをクリックします。
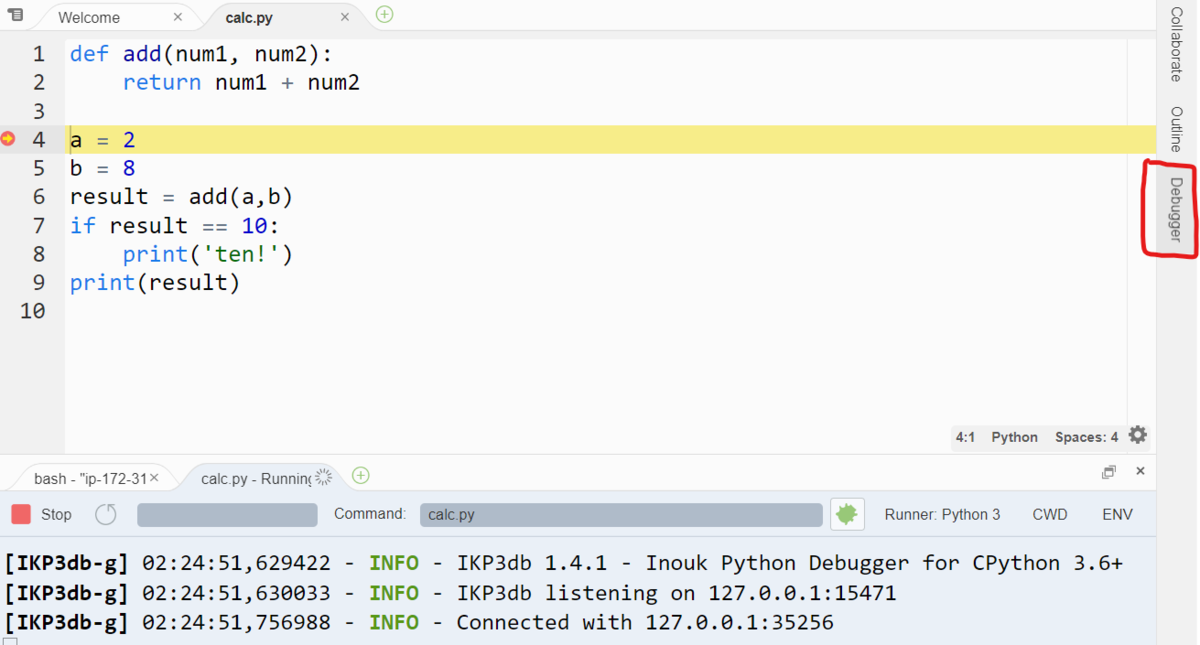
Debugger メニューをクリックすると、下図のようなペインが表示されます。
このペインの上にある、Step Over のメニュー(下図赤枠の部分)を1回クリックします。
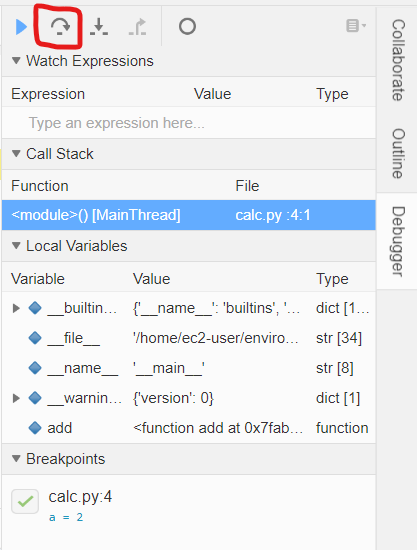
するとブレークポイントで停止していた実行が1行進みます。これで ブレークポイントの 4 行目のコードの実行が完了した状態になります。
このように、ブレークポイントで実行をいったん停止し、1行づつコードを実行していくことを一般的に ステップ実行 などといいます。
また、下図の赤線部分をみると、変数 a には 2 という int 型の値が格納されていることがわかります。
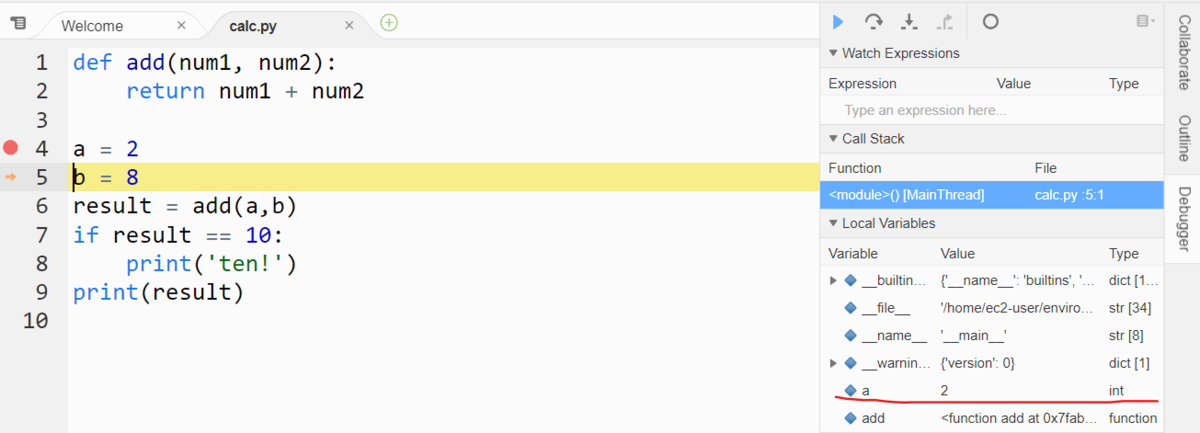
このように、ブレークポイントでコードの実行をいったん停止したあとに、 Step Overでコードをステップ実行しながら変数の内容を確認していくことができます。
Step Over のメニューのクリックを続けてみましょう。すると 5 行目から 9行目まで 1行づつ実行され、デバッグ実行が完了しましたね。
ただ、1行目、2行目に定義されている add 関数のコードにステップ実行ができませんでした。
実は、Step Over では、呼び出している関数の内部のコードにステップ実行することができません。
それを行うには、Step Into や Step Into という操作を行います。
Step IntoとStep Out
では、Step Into と Step Out を試してみましょう。
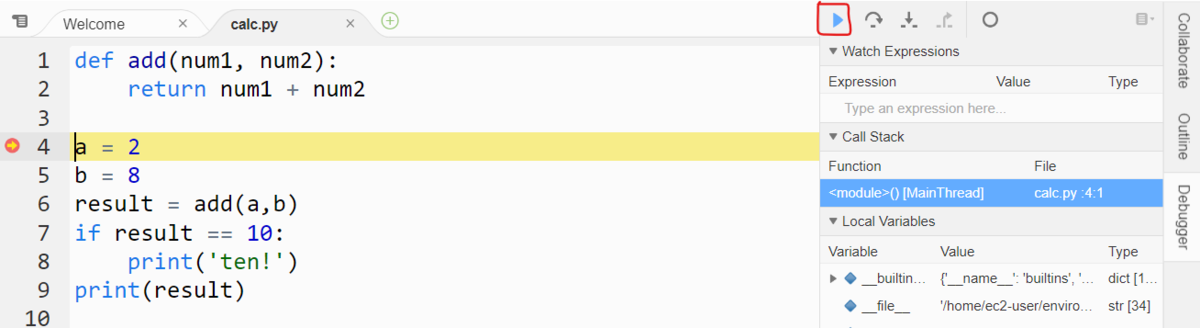
もう一度 Run メニューをクリックして 4 行目のブレークポイントで停止します。
その後、6 行目まで、Step Over でステップ実行を続けます。
6 行目では add 関数を呼び出していますね。ステップ実行が 6 行目きたら、下図のように Step Intoのメニューをクリックします。
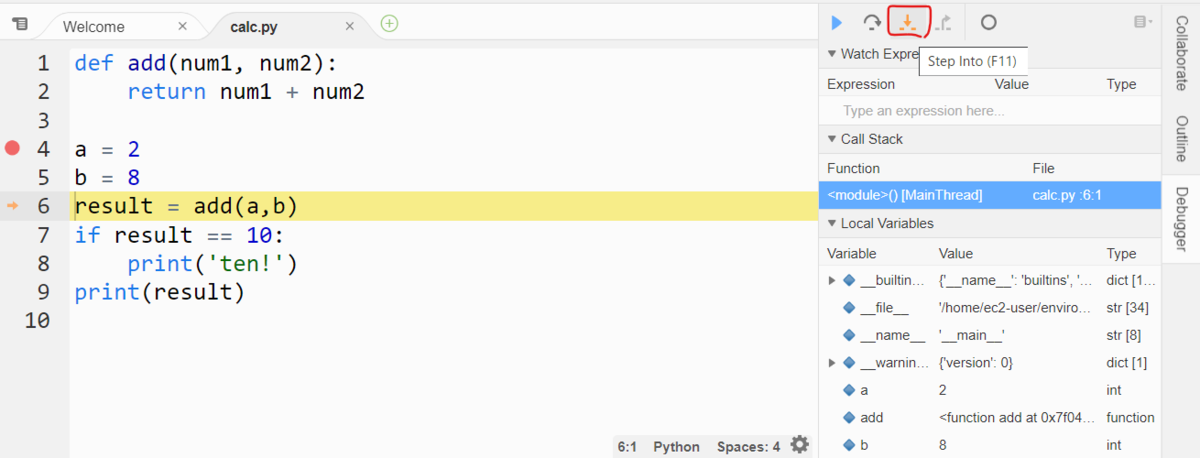
すると、ステップ実行が 2行目に進みましたね。
このように、呼び出し先の関数にステップ実行を進めるには、Step Into を行います。
また、呼び出し先の関数から、呼び出し元のコードにステップ実行を戻すには、Step Out を行います。
下図のように、ステップ実行が 2行目に進んだ状態で、Step Out のメニューをクリックします。
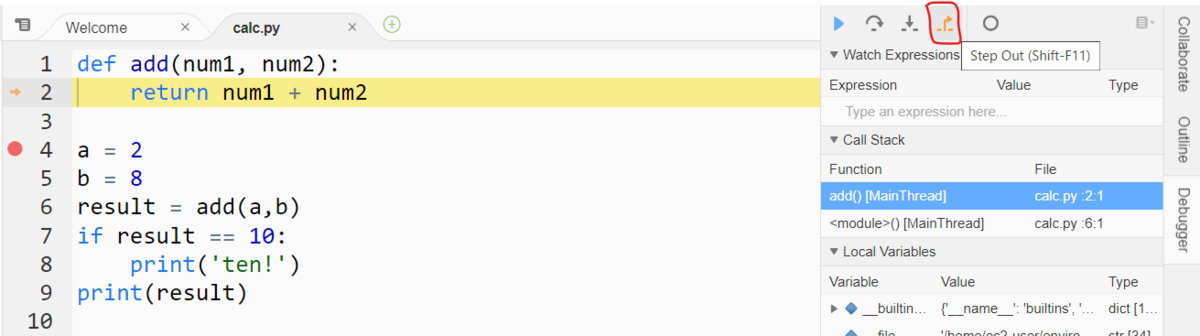
Step Outすると、下図のようにステップ実行が 7行目になりましたね。呼び出し元のコードに戻って、ステップ実行を続けることができます。
Resume と Stop
デバッグ実行中、ステップ実行ではなく、一気にコードを実行したい場合は、Resume メニューをクリックします。
これにより、次のブレークポイントが設定されていれば、そこまで一気にコードを実行できます。
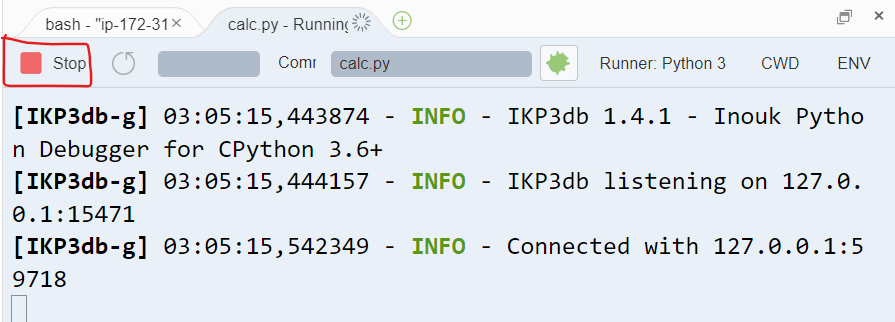
また、デバッグ実行を途中で停止したい場合は画面下部にある Stop をクリックします。
これにより、ステップ実行の途中でもデバッグ実行を停止できます。
最後に
今回は、Cloud9 のデバッグ機能の基本的な使用方法についてまとめました。
Cloud9 のデバッグ機能は、他にも様々な使い方ができますので、下記のドキュメントを参考にしてみて下さい!
AWS Step Functions の Distributed Map ステートを試してみる
これまで、AWS Step Functions の Map ステートを試してみる記事を 2 つ(下記)書いてきました。
今回は、その続きとして 2022 年 12 月にアナウンスされた Distributed Map を試してみます。
この記事の内容は、2022 年 12月時点で検証した内容に基づきます。リージョンは東京リージョンを使用しています。
これまでの Map ステートでは、並列度は 40 までしかサポートされていませんでした。
そのため、40 以上の並列度で処理をしたい場合は、Map ステートから別のステートマシンを呼出し、そのステートマシンでさらに Map ステートを使用するという Mapの入れ子構造を作成する必要がありました。
例えば、1024 の並列処理を行いたい場合は、親のステートマシンで 32 の並列度を指定した Map ステートを用意し、そこから呼び出した子となるステートマシンで 32 の並列度を指定した Map を構成することで、結果的に 32 × 32 = 1024 の並列度を実現していました。
しかし、今回 リリースされた Distributed Map では、並列度が 10,000 までサポートされましたので、「Map の 入れ子構造」を作成する必要はなくなりました。
では、実際に Distributed Map を使ったステートマシンを作成してみます。
今回も、Distributed Map に渡す配列は、下記の Lambda関数 ArrayGenerator で作成することにします。
この ArrayGenerator は Python 3.9 で作成されており、イベントオブジェクトから length というキーで指定された数値に基づき、動的に配列を生成してリターンします。
import json def lambda_handler(event, context): print(event) length = event['length'] items = [] for id in range(length): items.append({'item': id}) return items
次に、ステートマシンを作成します。下記の JSON を使用して、前回の記事と同様の手順で作成します。
なお、前回は Map から Lambda関数を invoke していましたが、今回はコスト面を考慮し、特に何もしないステートである Passステートを Distributed Map から実行する形にします。
ステートマシンの JSON は下記です。
(なお、Workflow Studio で GUI から作成することもできますが、その場合は Map ステートを選択して、「処理モード」として「分散」を指定します。)
{ "Comment": "A description of my state machine", "StartAt": "Lambda Invoke", "States": { "Lambda Invoke": { "Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "Parameters": { "Payload.$": "$", "FunctionName": "arn:aws:lambda:ap-northeast-1:123412341234:function:ArrayGenerator" }, "Retry": [ { "ErrorEquals": [ "Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException" ], "IntervalSeconds": 2, "MaxAttempts": 6, "BackoffRate": 2 } ], "ResultPath": "$.generatedArray", "Next": "Map" }, "Map": { "Type": "Map", "ItemProcessor": { "ProcessorConfig": { "Mode": "DISTRIBUTED", "ExecutionType": "STANDARD" }, "StartAt": "Pass", "States": { "Pass": { "Type": "Pass", "End": true } } }, "End": true, "Label": "Map", "MaxConcurrency": 1000, "InputPath": "$.generatedArray.Payload" } } }
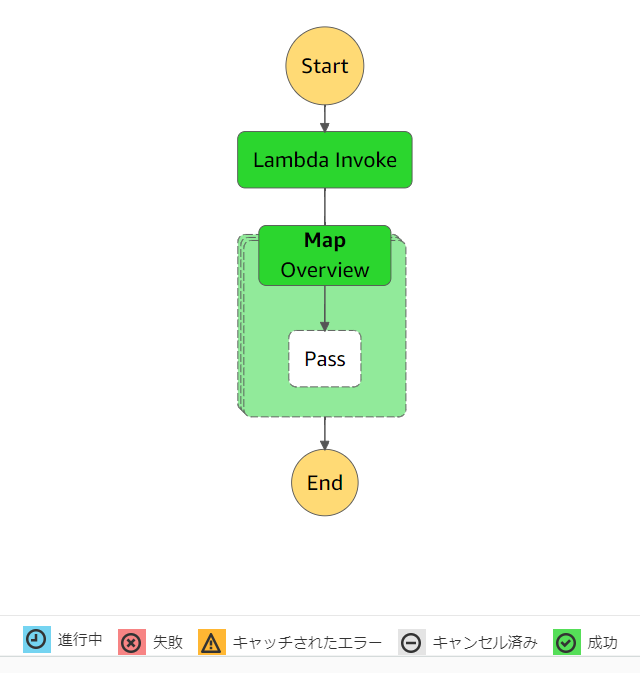
作成したステートマシンは、下図のようになります。

内容は、Passステートを使っている以外は、こちらの記事の内容とほぼ同じですね。
では、AWS マネジメントコンソールから実行してみます。ひとまず、配列の要素数を 3 で指定してみます。
作成したステートマシンのページで [実行の開始] ボタンを選択して [入力] に下記のパラメータを指定します。[実行の開始] をクリックします。
{"length": 3}
結果、下図のようにステートマシンは成功します。
ページの下側の「イベント」セクションをみてみましょう。
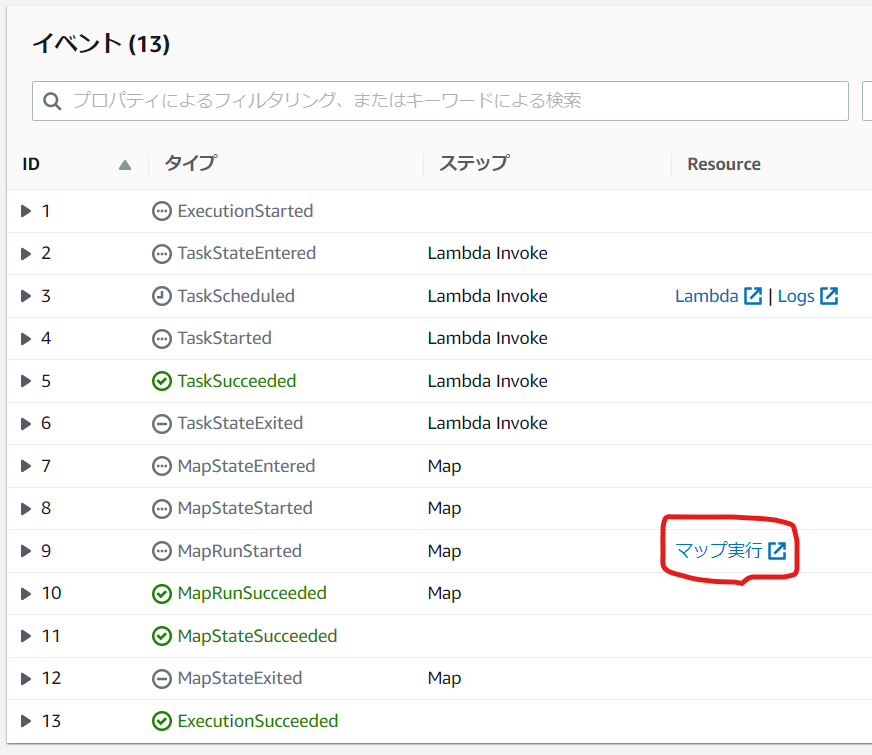
「Resource」列に「マップ実行」というリンクがありますね。これをクリックすると、次のように並列処理の結果を確認できます。

「実行」セクションの中の「名前」のリンクをどれか1つクリックすると、Pass が実行されたことも確認できます。
問題なく動作できていたら、並列度を 40よりも大きい値でも試してみましょう。このステートマシンを実行する時のパラメータの値を変えるだけで試せます。
{"length": 50}
また、Distributed Map では全体の処理のうち、許容される失敗のしきい値を割合(%)、または失敗した数で指定することもできたり、処理対象を配列だけでなく Amazon S3 のバケットのオブジェクトにすることもできます。
非常に興味深いですね。このような Distributed Map のその他の機能も、試していきたいです!
AWS Lambda の Provisioned Concurrency を設定した後、利用可能になるまでの状況を確認してみる
本記事は「AWS LambdaとServerless Advent Calendar 2022」11日目の記事です。
AWS Lambda では、「プロビジョニングされた同時実行数」を設定することができます。本記事においては便宜上、この設定を Provisioned Concurrency と呼称します。
この Provisioned Concurrency の設定を行うと、AWS Lambda 関数の実行環境を初期化して、関数の呼び出しに即座に応答する準備を行うため、コールドスタートによるレイテンシーの影響を低減することが期待できます。ただし、この設定を行うと AWS アカウントに課金が発生することに注意してください。詳細は、次のドキュメントを確認しましょう。
この Provisioned Concurrency の設定は、AWS マネジメントコンソールからも行えます。
AWS マネジメントコンソールで 対象の AWS Lambda 関数のページを表示し、[設定] タブを選択、左側のメニューで、[同時実行] のメニューを選択すると [プロビジョニングされた同時実行設定] セクションが表示されるので、そのセクションから [追加] ボタンを選択します。

その後、対象の AWS Lambda 関数のエイリアス または バージョン とプロビジョニングさせる実行環境の数を入力、保存することで設定は完了です。
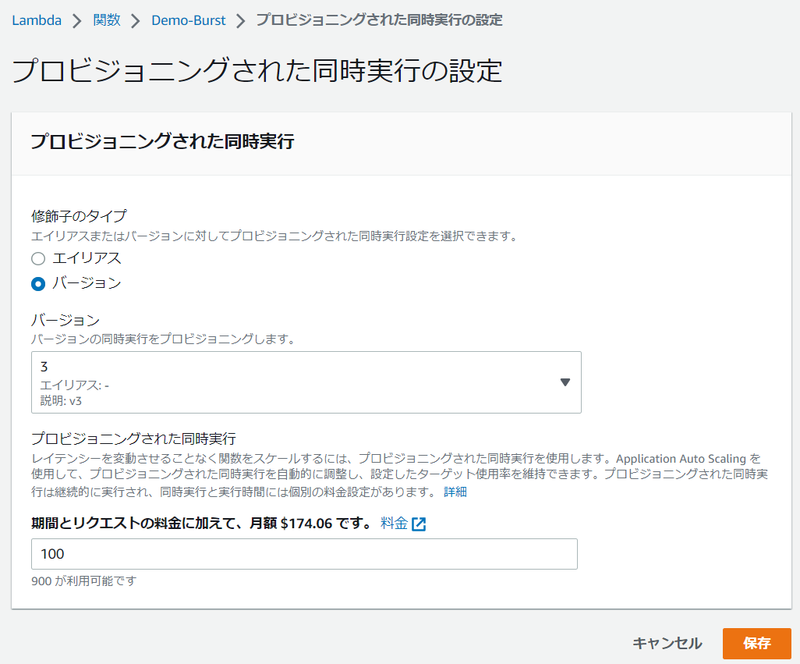
ただしここで設定したからといって、すぐに AWS Lambda 関数の実行環境が作成され、利用可能になるわけではありません。
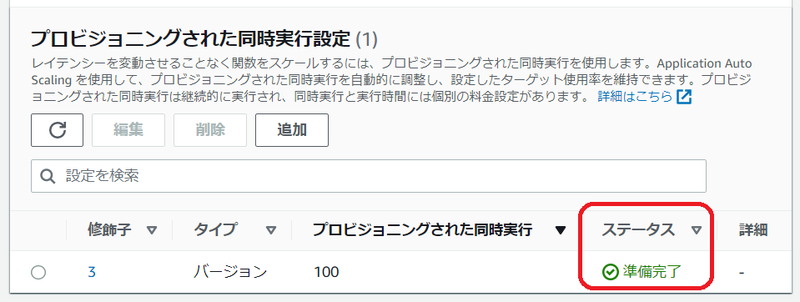
上記の設定後、AWS マネジメントコンソールでは下図のように表示されます。
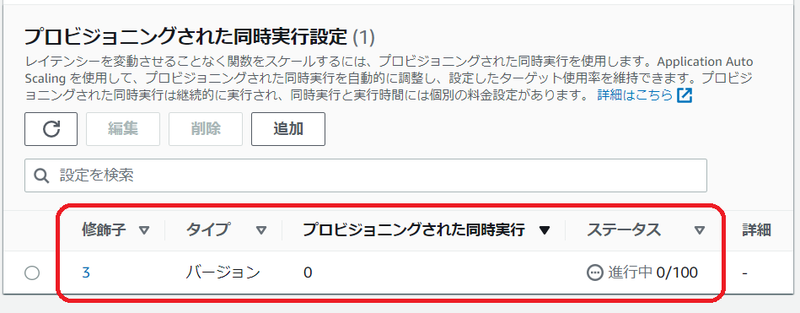
指定した値にも依りますが、しばらく待ってから手作業でページをリフレッシュ表示しないと [準備完了] とは表示されません。
ここで 私は 下記 2つの点が気になりました。
- Provisioned Concurrency の設定後に利用可能になるまで、どれくらいの時間がかかったのか知りたいけど、現状のAWS マネジメントコンソールでは、その情報は表示されない。
- Provisioned Concurrency の設定後、現時点でどれくらいの環境の数をプロビジョニングできたのか知りたいけど、現状のAWS マネジメントコンソールでは手動でページをリフレッシュしないと、その情報は表示されない。
しかし、次の AWS CLI のドキュメントを読んで、 aws lambda get-provisioned-concurrency-config コマンド を活用すれば、この気になった 2つの情報を知ることができるのでは、と考えました。
この AWS CLI のコマンドの出力には、下記が含まれます。
- AllocatedProvisionedConcurrentExecutions: アロケート(作成)済の実行環境数
- AvailableProvisionedConcurrentExecutions: 利用可能な実行環境数
- Status: アロケートの状態
Provisioned Concurrency の設定後に、この AWS CLI のコマンドを継続的に実行すれば、上記 2つの情報を得られそうです。
そこで、下記のスクリプトを作成しました。(このスクリプトは Linux での使用を前提にしています。)
#!/bin/bash # Provisioned Concurrency を設定 aws lambda put-provisioned-concurrency-config --function-name $1 --qualifier $2 --provisioned-concurrent-executions $3 # 開始時刻を取得 started_time=$(date +'%s.%3N') # Status が READY になるまで待機 while [ "$STATUS" != "READY" ] do RESULT=$(aws lambda get-provisioned-concurrency-config --function-name $1 --qualifier $2) STATUS=$(echo ${RESULT} | jq -r '.Status') ALLOCATE=$(echo ${RESULT} | jq -r '.AllocatedProvisionedConcurrentExecutions') AVAILABLE=$(echo ${RESULT} | jq -r '.AvailableProvisionedConcurrentExecutions') echo `date`, ${STATUS}, ${ALLOCATE}, ${AVAILABLE} sleep 1 done # 完了時刻を取得 ended_time=$(date +'%s.%3N') # 完了時刻 - 開始時刻で経過時間を算出 elapsed=$(echo "scale=3; $ended_time - $started_time" | bc) # 経過時間を表示 echo "ELAPSED : ${elapsed} seconds" # Provisioned Concurrencyの状況を表示 aws lambda get-provisioned-concurrency-config --function-name $1 --qualifier $2
このスクリプトでは、第1引数に AWS Lambda 関数名を、第2引数に エイリアス名またはバージョンIDを、第3引数に Provisioned Concurrency の値を受け取る前提にしています。
また、Provisioned Concurrency の設定後、1秒毎に AWS CLI でステータスとアロケート済の環境数や利用可能な環境数を取得・表示させています。またステータスの値をチェックして 設定した Provisioned Concurrency が利用可能になったら、それまでかかった時間(秒)を算出して停止します。
実際の実行例を次に示します。 上記スクリプトを test.sh として実行しています。AWS Lambda 関数名は Demo-Burst、バージョンIDは3、Provisioned Concurrency の値は 100 で指定しています。
$ ./test.sh Demo-Burst 3 100 { "RequestedProvisionedConcurrentExecutions": 100, "AllocatedProvisionedConcurrentExecutions": 0, "AvailableProvisionedConcurrentExecutions": 0, "LastModified": "2022-12-03T06:30:51+0000", "Status": "IN_PROGRESS" } Sat Dec 3 06:30:51 UTC 2022, IN_PROGRESS, 0, 0 Sat Dec 3 06:30:53 UTC 2022, IN_PROGRESS, 0, 0 Sat Dec 3 06:30:54 UTC 2022, IN_PROGRESS, 0, 0 (・・・中略・・・) Sat Dec 3 06:32:41 UTC 2022, IN_PROGRESS, 0, 0 Sat Dec 3 06:32:43 UTC 2022, IN_PROGRESS, 0, 0 Sat Dec 3 06:32:45 UTC 2022, IN_PROGRESS, 0, 0 Sat Dec 3 06:32:46 UTC 2022, IN_PROGRESS, 87, 0 Sat Dec 3 06:32:48 UTC 2022, IN_PROGRESS, 87, 0 Sat Dec 3 06:32:50 UTC 2022, IN_PROGRESS, 87, 0 Sat Dec 3 06:32:52 UTC 2022, IN_PROGRESS, 87, 0 Sat Dec 3 06:32:54 UTC 2022, IN_PROGRESS, 87, 0 Sat Dec 3 06:32:55 UTC 2022, IN_PROGRESS, 87, 0 Sat Dec 3 06:32:57 UTC 2022, READY, 100, 100 ELAPSED : 127.205 seconds { "RequestedProvisionedConcurrentExecutions": 100, "AllocatedProvisionedConcurrentExecutions": 100, "AvailableProvisionedConcurrentExecutions": 100, "LastModified": "2022-12-03T06:30:51+0000", "Status": "READY" }
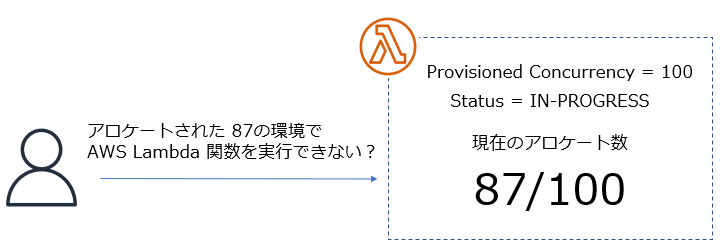
上記の出力はあくまで例の1つですが、Provisioned Concurrency の設定後、約 127秒で利用可能になりました。また、利用可能になるまでアロケートされた数として 87 という数字が確認できました。 もちろん、このスクリプトは1つの例ですが、少なくとも AWS マネジメントコンソールで手動でページをリフレッシュしなくともよくなりました。
このスクリプトを何度か実行していて、また気になる点が出てきました。
Provisioned Concurrency の設定後、現在のアロケートされた値はスクリプトで確認できるようになりましたが、最終的にステータスが READY、つまり利用可能になるのは、AvailableProvisionedConcurrentExecutions の値が設定した値になったタイミングです。
上記の出力例だと、途中にアロケートされた値が 87 と表示されてますが、いくら 87 の環境がアロケートされていても、その段階ではまだ Provisioned Concurrency によってプロビジョニングされた環境は利用不能ということになります。
そこで、本当に利用できないのか確認してみました。
方法としてはシンプルに、上記のスクリプトを実行しアロケートされた値が 50 より大きい値になったタイミングで、その AWS Lambda関数に同時アクセスを行い、Amazon CloudWatch のメトリクスで確認することにしました。
この仕組みを解説すると長くなるので、概略だけ説明します。
- 対象の AWS Lambda 関数は、実行環境が再利用されにくい状態で一気に同時アクセスを行いたかったので、コードの中に 3秒ほど sleep するコードを入れておきます。
- Python だと、
time.sleep(3)など
- Python だと、
- Amazon CloudWatch では、次のメトリクスを監視できるように Amazon CloudWatch のダッシュボードに設定しておきます。
- ProvisionedConcurrencyInvocations
- Invocations
- ProvisionedConcurrentExecutions
- ConcurrentExecutions
- ProvisionedConcurrencyUtilization
- ProvisionedConcurrencySpilloverInvocations
- 一気に同時アクセスを行う方法として、下記の AWS Step Functions の Distributed Map を使ったステートマシンを実行することにしました。Distributed Mapを使用し、AWS Lambda 関数に対して 並列度 50 で同時アクセスしてみます。
上記の仕組みで試してみた結果をみると、やはり アロケートの値が 50 以上になっても、ステータスが IN-PROGRESS の状態だと、Provisioned Concurrency として使用できない ということがわかりました。
Amazon CloudWatch の メトリクスを確認してみます。
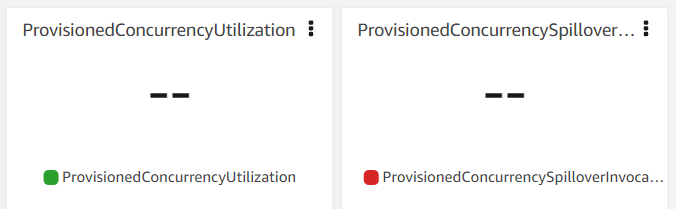
- まず Invocations が50に対して、ProvisionedConcurrencyInvocations は値なしという結果から、Provisioned Concurrency によって関数コードは実行されなかったことを示しています。

- 次に ConcurrentExecutions が 50に対して、ProvisionedConcurrentExecutions は値なしという結果から、Provisioned Concurrency の環境でイベントを処理しているものがないことがわかります。つまり通常 のコールドスタートのプロセスを経て実行環境がプロビジョニングされたことを示します。

- なお、ProvisionedConcurrencyUtilization と ProvisionedConcurrencySpilloverInvocations は値がないという結果になりました。これは、そもそも 利用可能な Provisioned Concurrency の環境がないため算出されなかったと推察できます。
同じ環境で、Provisioned Concurrency のステータスが READY になった後に同様のアクセスを行うと、これらのメトリクスの値は下記のようになります。
- Invocations が50に対して、ProvisionedConcurrencyInvocations も 50 という結果から、50のリクエストは全て Provisioned Concurrency 環境の AWS Lambda 関数を呼び出したことがわかります。

- ConcurrentExecutions が 50に対して、ProvisionedConcurrentExecutions も 50 という結果から、50 の Provisioned Concurrency の環境で AWS Lambda 関数のコードを処理したことがわかります。

- ProvisionedConcurrencyUtilization は 0.5、つまり Provisioned Concurrency の 100 の環境のうち 50 が使用されて AWS Lambda 関数が実行されたことがわかります。また ProvisionedConcurrencySpilloverInvocations は 0 であり、Provisioned Concurrency で賄いきれなかったリクエストがなかったことがわかります。

なお、AWS Lambda 関数の メトリクスについては下記のドキュメントにも説明がありますので、ご参照ください。
まとめ
- AWS Lambda の Provisioned Concurrency を設定後の状況については、AWS CLI を活用することで取得、表示できます。
- その AWS CLI でアロケートされた環境数は確認できるものの、ステータスが READY になるまでは、Provisioned Concurrency としては使用できません。
これからも、このように「ちょっとした疑問」から Dive Deep して調べてみる、ということをドンドンやっていきたいと思います!
なお繰り返しの説明になりますが、Provisioned Concurrency を使用すると料金がかかりますので、もし実際に試す場合は課金に十分に留意して下さい。 詳細は、下記をご参照ください。
(本記事は 2022年12月11日時点で確認した内容を基に記載しています。)