Amazon Linux 2 に rbac-lookup をインストールする
Amazon Linux 2 に rbac-lookup をインストールする時に、やや試行錯誤が必要だったので正しくインストールする手順をメモしておきます。
rbac-lookupは、Kubernetes 環境の ロールやクラスターロールとバインドしているユーザーやサービスアカウントの情報をシンプルに表示してくれるコマンドラインツールです。
rbac-lookup.docs.fairwinds.com
rbac-lookup は、Linux で brew コマンドが使用できる環境であれば容易にインストールできるはずなのですが、Amazon Linux 2 ではデフォルトでは brewが使えません。
よって、まず brew が使用できるようにします。
(実は、ここが一番試行錯誤したところです。)
まず前提として、Kubernetes クラスタに接続できる Amazon Linux 2 の環境にログインします。
以降は、OSユーザーが ssm-user という前提でコマンドを記載します。
まず、Development Tools グループを指定して必要なパッケージ群をインストールします。
sudo yum groupinstall 'Development Tools' -y
次に、Linuxbrew をインストールします。
sh -c "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install.sh)"
途中で次のように表示されるので、Enter キーを押します。
Press RETURN/ENTER to continue or any other key to abort:
この後、少し時間がかかりますが、brew のインストールが完了しますので、PATH を通しておきましょう。
PATH を通すためのコマンドは、brew のインストール完了時にも表示されています。
次のコマンドは、OSユーザーが ssm-user であることを前提にしています。
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> /home/ssm-user/.bash_profile eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"
念のため、brew doctor を実行して brew が正しく使用できるか確認しておきましょう。
brew doctor
次のように表示されれば OK です。
Your system is ready to brew.
これでようやく、rbac-lookup をインストールできます。
brew install FairwindsOps/tap/rbac-lookup
インストール完了後、さっそく rbac-lookup を試してみましょう。
次のコマンドでは、Kubernetes のグループにバインドされているロールを表示します。
rbac-lookup -k group
結果の例です。
SUBJECT SCOPE ROLE eks:kube-proxy-windows cluster-wide ClusterRole/system:node-proxier system:authenticated cluster-wide ClusterRole/eks:podsecuritypolicy:privileged system:authenticated cluster-wide ClusterRole/system:basic-user system:authenticated cluster-wide ClusterRole/system:discovery system:authenticated cluster-wide ClusterRole/system:public-info-viewer system:bootstrappers cluster-wide ClusterRole/eks:node-bootstrapper system:masters cluster-wide ClusterRole/cluster-admin system:monitoring cluster-wide ClusterRole/system:monitoring system:node-proxier cluster-wide ClusterRole/system:node-proxier system:nodes cluster-wide ClusterRole/eks:node-bootstrapper system:serviceaccounts cluster-wide ClusterRole/system:service-account-issuer-discovery system:unauthenticated cluster-wide ClusterRole/system:public-info-viewer
無事に rbac-lookup を実行できましたね!
今回は、EC2 インスタンスに AWS Systems Manager のセッションマネージャーを使用してアクセスしたので、OS ユーザーは ssm-user となっています。
再度セッションマネージャーで接続した後は、rbac-lookup コマンドの PATH を通すために、.bash_profile の内容を反映させる必要があります。
これを手っ取り早く行うには、 sudo su - ssm-user を実行するとよいでしょう。
rbac-lookup はすごく便利なのですが、如何せん、brew でのインストールが必要になります。
macOS 環境であれば簡単にインストールできるのですが、Amazon Linux 2 では、brew 自体のインストールが必要なため、少し手間取りました。
この記事がどなたかの参考になれば嬉しいです!
AWS Step Functions と Amazon EKS の連携でハマったこと
AWS Step Functions のステートマシンから Amazon EKS クラスターで Job を実行しようとしたときにハマったことをメモしておきます。
最初は、次の AWS Blog の記事がキッカケでした。
AWS Step FunctionsとAmazon EKSの統合のご紹介
この記事では、AWS Step Functions と Amazon EKS の統合について記載されてます。
これを、自分なりに試してみようと思ったわけです。
ただシンプルに試したかったので、EKS クラスターで Job の実行を行うだけのステートマシンを作成することにしました。
まず、自分が既に用意している EKS クラスターのエンドポイントや CertificateAuthority の情報を用意しておきます。
これは AWS マネジメントコンソール で EKSのクラスターの情報を表示すれば参照できますが、今回は AWS CLI で取得しています。
次のコマンドは dev-cluster というクラスターのエンドポイントを取得する例です。
aws eks describe-cluster --name dev-cluster | jq '.cluster.endpoint'
結果の例
"https://xxxxxxxxxxxxxxx.yz5.ap-northeast-1.eks.amazonaws.com"
次は CertificateAuthority を取得する例です。
aws eks describe-cluster --name dev-cluster | jq '.cluster.certificateAuthority.data'
結果の例 (実際は長い文字列ですが、省略しています。)
"LS0t6UFBwS29jU ... 0tCg=="
次に、AWS Step Functions で 標準タイプのステートマシンを作成していきます。
WorkFlow Builderで、次の図のように作成します。③ の APIパラメータに、EKS クラスター名やエンドポイント、CertificateAuthority を設定します。
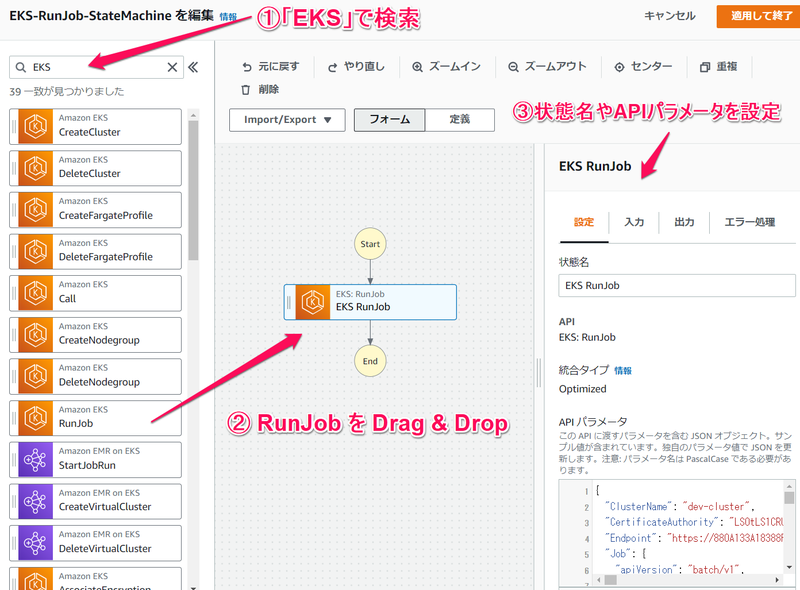
③ の APIパラメータで、実行する Job のマニフェストを指定できます。デフォルトのままでもいいのですが、Job の実行時間を短縮したかったので、print bpi(2000) の個所を print bpi(20) に変更しました。
次の例は、APIパラメータで、Job のマニフェスト部分を抜粋したものです。
"Job": { "apiVersion": "batch/v1", "kind": "Job", "metadata": { "name": "my-example-job20" }, "spec": { "template": { "metadata": { "name": "my-example-job" }, "spec": { "containers": [ { "name": "my-function-name", "image": "perl", "command": [ "perl" ], "args": [ "-Mbignum=bpi", "-wle", "print bpi(20)" ] } ], "restartPolicy": "Never" } } } } },
次に、[ステートマシン設定を指定] のページの [アクセス許可] のセクションで、ステートマシンに設定するIAM ロールを指定します。 今回は、新しい IAM ロールを作成するように指定します。
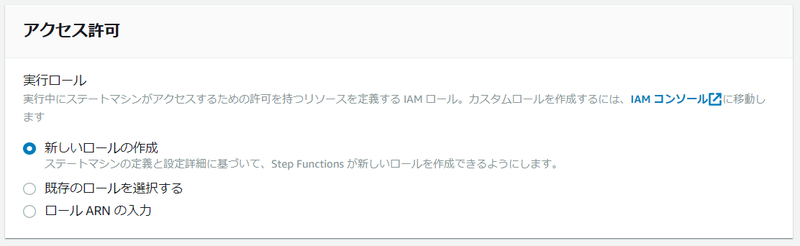
そしてステートマシンの作成を完了させると、自動作成された IAM ロールの ARN が表示されるので、それをコピーします。
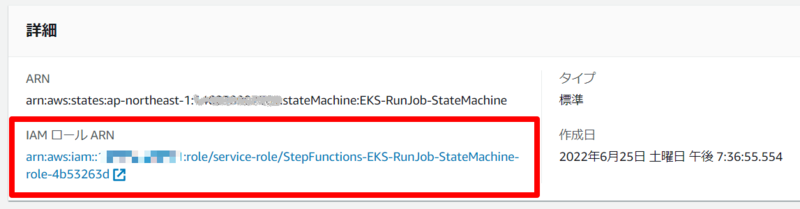
この IAM ロールは、 EKS クラスターで Job を実行する許可を与える必要があるため、EKS クラスターに接続できる環境から eksctl コマンドを使って次を実行します。
なお、AWSアカウント ID や IAM ロール名、EKS クラスター名は環境に応じて変更する必要があります。
実はこれがハマるポイントなのですが、説明は後にして、ひとまずこのまま実行します。
eksctl create iamidentitymapping --cluster dev-cluster --arn arn:aws:iam::000000000000:role/service-role/StepFunctions-EKS-RunJob-StateMachine-role-4b53263d --group system:masters --username my-statemachine
このコマンドは、あくまで例の一つですが、ステートマシンの IAM ロールと Kubernetes の system:masters グループをマッピングすることで、ステートマシンが EKS クラスターで Job を実行することを許可しています。
これで、ステートマシンから EKS クラスターに対して Job を実行する準備が整いました。
しかし、ステートマシンを実行すると、次のようなエラーが出てしまいます。
エラー EKS.401 原因 { "ResponseBody": { "kind": "Status", "apiVersion": "v1", "metadata": {}, "status": "Failure", "message": "Unauthorized", "reason": "Unauthorized", "code": 401 }, "StatusCode": 401, "StatusText": "Unauthorized" }
さきほどの ekstctl コマンドで、IAM ロールを system:masters グループにマッピングしたはずなのに、なぜ Unauthorized になるのか理解できず、しばらく悩みました。
しかし、次の Step Functions のドキュメントをみると、この原因がわかりました。
Permissions | Call Amazon EKS with Step Functions
このドキュメントには、Note として次のような記載があります。
Note You may see the ARN for an IAM role displayed in a format that includes the path /service-role/, such as arn:aws:iam::123456789012:role/service-role/my-role. This service-role path token should not be included when listing the role in aws-auth.
つまり、ekstctl コマンドで、IAM ロールを system:masters グループにマッピングするときに、IAM ロールのARNに /service-role/ というパスを含めてはいけない! ということなんですね。
では、修正していきます。
まず、さきほどのマッピングを削除します。
eksctl delete iamidentitymapping --cluster dev-cluster --arn arn:aws:iam::000000000000:role/service-role/StepFunctions-EKS-RunJob-StateMachine-role-4b53263d
次に、/service-role/ を含まない ARN を指定して、マッピングを作成します。
eksctl create iamidentitymapping --cluster dev-cluster --arn arn:aws:iam::000000000000:role/StepFunctions-EKS-RunJob-StateMachine-role-4b53263d --group system:masters --username my-statemachine
このあと、ステートマシンを実行すると問題なく Job を起動することができました。
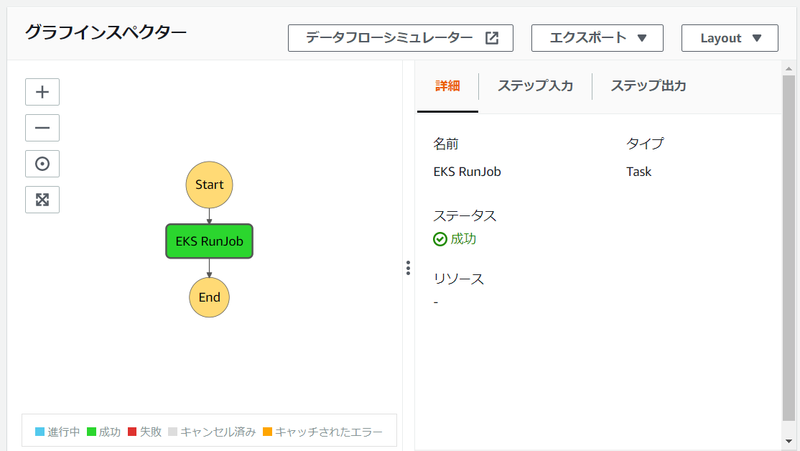
また、EKS クラスター側でも Job が完了したことを確認できました。
$ kubectl get jobs NAME COMPLETIONS DURATION AGE my-example-job 1/1 4s 4m21s $ kubectl describe job my-example-job Name: my-example-job Namespace: default Selector: controller-uid=cc291e67-8d12-4f64-b6c3-01e330957bed Labels: controller-uid=cc291e67-8d12-4f64-b6c3-01e330957bed job-name=my-example-job Annotations: <none> Parallelism: 1 Completions: 1 Start Time: Sun, 26 Jun 2022 00:24:58 +0000 Completed At: Sun, 26 Jun 2022 00:25:02 +0000 Duration: 4s Pods Statuses: 0 Running / 1 Succeeded / 0 Failed Pod Template: Labels: controller-uid=cc291e67-8d12-4f64-b6c3-01e330957bed job-name=my-example-job Containers: my-function-name: Image: perl Port: <none> Host Port: <none> Command: perl Args: -Mbignum=bpi -wle print bpi(20) Environment: <none> Mounts: <none> Volumes: <none> Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulCreate 4m33s job-controller Created pod: my-example-job-8k5xr Normal Completed 4m29s job-controller Job completed
ハマったといっても実はドキュメントには Note として記載してあったので、うっかりのレベルではあります。
ただ、ステートマシン作成時に IAM ロールを作成して、そのままコンソールに表示されている ARN をコピーしてしまうということは、ありがちではないかと思うので注意したいと思います。
Amazon Linux 2 に microk8s をインストールする方法
先日、Amazon Linux 2 に minikube をインストールする方法という記事を書きましたが、今回は microk8s をインストールする方法をまとめていきます。
インストール手順は、 Canonical 社の microk8s の Getting Start のページに記載されていますが、まず推奨される環境を用意します。
Getting Startのページでは次のような環境が推奨されています。
- 最低 20G のディスク空き容量
- 最低 4G のメモリ
そのため、EC2 インスタンスのインスタンスタイプは t3.medium を選択して、EBS のストレージ容量も 余裕をもって 30GB に設定することにしました。 t3.medium は、AWSの無料利用枠ではないためご注意ください。
また、EC2インスタンスに接続した後のシェルを bash にしておきましょう。
そのため、もし Systems Manager の Session Manager で接続した場合は、次の例のコマンドを実行して、シェルをbash にして、かつホームディレクトリに移動しておくとよいでしょう。
sudo su - ssm-user
インスタンスに接続したら、さっそく microk8s をインストールしたいところですが、Amazon Linux 2 の場合は、まずは snapd をインストールする必要があります。
snapdのリポジトリをダウンロードします。
cd /etc/yum.repos.d/
sudo wget https://people.canonical.com/~mvo/snapd/amazon-linux2/snapd-amzn2.repo
次に /etc/yum.conf を開きます。
sudo vi /etc/yum.conf
そして、一番最後に下記を追記して保存します。
exclude=snapd-*.el7 snap-*.el7
これで、snapd をインストールできるようになります。
cd sudo yum install -y snapd sudo systemctl enable --now snapd.socket
snapd のインストールが完了したら、いよいよ microk8s をインストールします。
sudo snap install microk8s --classic --channel=1.24
注意: 実行後、次のようなエラーが表示された場合は、1,2分待ってから再度実行して下さい。
error: too early for operation, device not yet seeded or device model not acknowledged
インストールが完了すると、次のようなメッセージが表示されます。
microk8s (1.24/stable) v1.24.0 from Canonical installed
次に、OSユーザーを microk8sグループ に追加するなどの処理を行います。
sudo usermod -a -G microk8s $USER sudo chown -f -R $USER ~/.kube
設定を反映させるため、新たにセッションを開始します。
sudo su - $USER
microk8sのステータスを確認しておきましょう。
microk8s status --wait-ready
これで、microk8s を使用する準備が整いました。
ただ、microk8s では、Kubernetes を操作するのに microk8s kubectl を使うため、次のような alias を設定しておくことにします。
alias kubectl='microk8s kubectl'
では、シンプルな Deployment を作成して確認みましょう。
kubectl create deployment nginx --image=nginx
kubectl get pods
kubectl get deploy
microk8s を問題なくインストールできていれば、Pod のステータスは Running になっているはずです。
bash を使う、snapd のインストールが必要、という点に注意すれば、minikube よりもシンプルに使えそうだというのが個人的な感想です!
Amazon Linux 2 に minikube をインストールする方法
この記事に記載されている方法は、minikube 1.26 以降のバージョンでは適用できませんのでご注意ください。 詳細は、下記の v1.26.0 のリリース情報をご参照ください。
Releases · kubernetes/minikube · GitHub
こちら minikube start の内容を参考に実施しました。 minikube start の記載だけでは不十分な箇所があったので、迷わずインストールできるよう手順をこの記事に書いていきます。
この時、minikube start に記載されている次の要件を満たすため、インスタンスタイプは t3.small で EBSボリュームの容量も 20 GB 以上にしておきます。(このスペックは AWS の 無料枠 ではありませんのでご注意ください。)
- 2 CPUs or more
- 2GB of free memory
- 20GB of free disk space
インスタンスが作成されたら、接続します。 私は Session Manager で接続しましたが、ssh を使って ec2-user で接続してもかまいません。
接続後、次の手順を実施していきます。
Docker をインストールする
sudo yum update -y sudo amazon-linux-extras install -y docker sudo systemctl enable docker sudo systemctl start docker
OSユーザーをdockerグループに追加
次の例では OSユーザーを ssm-user にしています。
sudo gpasswd -a ssm-user docker
この後、いったんログアウトして、もう一度ログインします。
minikube のインストール
いよいよ minikube をインストールします。
conntrack のインストールも必要です。
curl -LO https://github.com/kubernetes/minikube/releases/download/v1.25.2/minikube-linux-amd64 sudo install minikube-linux-amd64 /usr/local/bin/minikube sudo yum install -y conntrack
minikubeの起動
インストールが終了したら、起動します。
次の例では --vm-driver=none で起動しています。
minikube start --vm-driver=none
kubectl の設定
次の例では、minikube の handbook の kubectl の内容を参考に、シンボリックリンクを使って kubectl を使うようにしています。
sudo ln -s $(which minikube) /usr/local/bin/kubectl
kubectl を試してみます。
kubectl get all
結果の例:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2m
これで、完了です。 一度手順が確立できれば、簡単に、いつでもすぐに再構築できますね。