Python 3エンジニア認定 基礎試験の勉強記録:関数の引数編
 先週から引き続き、あらためて Python を体系的に勉強してみて学べたことや、メモとして残しておきたいことなどを記載していきます。今回は 関数の引数編 です。
先週から引き続き、あらためて Python を体系的に勉強してみて学べたことや、メモとして残しておきたいことなどを記載していきます。今回は 関数の引数編 です。
学習のゴールとして、Python 3エンジニア認定 基礎試験 の合格ですが、Python というプログラミング言語の仕様の全てや、試験合格のコツを解説するのではなく、あくまで自分が気づけたことのメモであることはご了承ください!
この試験ですが、先日受験して合格できました! 今回の記事では、Python の学習や試験を受けて合格するまで振返ってみた所感も記述します。
目次
引数のデフォルト値
まず、次のコードをみてみましょう。
a = 1 def hello(x = a): return x a = 2 res = hello() print(res)
このコードを実行した結果はどうなるでしょうか? 2 と表示される?それとも 1 と表示される?
正解は、1 と表示されます。
a という変数には、最終的に 2 が代入されていて、その後に hello 関数を呼び出しているから 2 が表示されるんじゃないの?と考えてしまうかもしれません。
ただ、コードを最初から順番にみていきましょう。最初は、 a = 1 で a に 1 を代入しています。
次に、hello 関数を定義しています。この定義の段階で、仮引数 x にデフォルト値として 変数の a の値を設定しています。この時の a の値は 1 なので、x には 1が代入されています。
その後、a に 2 を再代入したとしても、hello 関数の仮引数 x の値は変わらないので、hello 関数を引数を設定せずに呼び出した場合は、デフォルトの値 1 が表示されます。
仮引数のデフォルト値が決定するタイミングの理解が重要ですね!
引数の位置とキーワード
次のような関数があったとします。
def print_param(x,y,z): print(x,y,z)
この関数に引数を設定して呼び出す方法として、次の a から e のうち 誤っているもの が 2 つ あります。どれとどれでしょうか?
print_param(1, y=2, z=3)print_param(1, 2, z=3)print_param(x=1, y=2, 3)print_param(x =1, 2, z=3)print_param(y=2, z=3, x=1)
いかがでしょうか?
どの選択肢も、引数を 3つ指定しています。また、キーワード引数、つまり x=1 と引数の値を指定してるものもありますが、 仮引数名 (x, y, z) を間違えているわけではないですよね。
ただし、キーワード引数と、位置引数(1 のように引数の値だけを記載するもの)を混在して使っているものがあります。
この問題を解くための重要なポイントは、キーワード引数の後に位置引数を指定できない というルールです。
- 選択肢 A では、キーワード引数 は、
y=2とz=3ですが、これらは1という 位置引数の後 に指定されているので、正しい指定となります。 - 選択肢 B も、同様ですね。
- 選択肢 C はどうでしょうか? キーワード引数
x=1とy=2は、位置引数3の前に指定されています。これは誤った指定となります。 - 選択肢 D も、選択肢C と同様で、キーワード引数が 位置引数の前に指定されているので誤りです。
- 選択肢 E は、位置引数がないので問題ありません。
ということで、誤っている選択肢は、C と D となります。
可変長引数
次はメモとして記載しています。仮引数に * をつけることで、複数の値を タプル として受け取ることができます。
def print_as_tapple(*args): print(args) print_as_tapple("a","b","c")
このコードを実行すると、次のように a, b, c の値をもつ タプルとして 表示されます。
('a', 'b', 'c')
また、仮引数に ** をつけることで、複数の値を 辞書型 として受け取ることができます。
def print_as_dict(**args): print(args) print_as_dict(a="1",b="2",c="3")
このコードを実行すると、次のように 辞書型として 表示されます。
{'a': '1', 'b': '2', 'c': '3'}
引数のアンパック
次のコードをみてみましょう。
def greeting(name): print("Hello!" + name) 【A】 greeting(**me)
このコードで、Hello!Alex という結果を得るには、【A】にはどのようなコードを挿入すればいいでしょうか?
次の選択肢の中から 1 つ選択して下さい。
me = "name=Alex"me = ("name","Alex")me = {"name" : "Alex"}me = "["name","Alex"]"
これは、引数のアンパック に関する問題です。コードの 4 行目で greeting 関数の引数にアスタリスクを 2 つつけて **me と指定しています。
これにより、me の辞書型のキーを、キーワード引数の名前として指定して関数に値を渡すことができます。
つまり辞書型を指定する必要があるので、選択肢 C が正解になります。
greeting 関数の仮引数名は name なので、辞書型のキーの名前と一致する必要があります。
選択肢 C では、辞書型のキーは name で、値が Alex です。キーの name は 仮引数名と一致してますよね。
ちなみに、引数が {"name" : "Alex", "address" : "Kyoto"} の場合は、name 以外のキーも含んでいるので、実行時に次のエラーが発生します。
TypeError: greeting() got an unexpected keyword argument 'address'
参考までに、次のコードは問題なく動作して、Hello!John Doe と表示されます。
def greeting_fullname(fname,lname): print("Hello!" + fname + " " + lname) me = {"fname" : "John", "lname" : "Doe"} greeting_fullname(**me)
勉強開始から合格までの振り返り
さて、3 回にわたり Python 3エンジニア認定 基礎試験の勉強記録を投稿してきました。
振返ってみると、もともとは、「Python を独学ではなく、体系的に学んでスキルを強化したい!」という思いから始めた取組みでした。
これまで、サンプルなどを参考に Python のコードを書く機会は多々ありましたが、わからないことがあれば、その都度、その部分だけ調べるという取り組みをしてきたので、体系的な学習ができていませんでした。
今回、体系的に Python を学習することで、中途半端に理解していた部分(まさにブログに書いてきた部分)を正確に理解することができたので、とても収穫が大きかったと思ってます。
試験については、市販の問題集や Web から利用できる模擬試験を活用して勉強しました。
そこでわからなかった問題や、間違えた問題は、実際にコードを書いてみて動作を確認するようにしました。また、その際、「もし、コードをこう変えたらどうなるだろう?」というアレンジも積極的に行いました。そのアレンジが、このブログで紹介したサンプルコードになっています。
こういった取り組みはけっこう時間はかかりますが、その分、自分の理解をより深めることができす。
試験本番の直前に受けた模擬試験では、自分にとって難しい問題が多く点数が 730 (合格点は 700) とギリギリだったので、「もしかしたら、危ないかな」ともあせりましたが、実際に試験を受けてみると、難易度は模擬試験より低かったように感じました。(あくまで個人の感想です。たまたま自分にとって簡単だった問題が多かっただけかもしれません。)
そのため、20分ほどで試験を終了して、875 点で合格することができました。
合格してホッとしましたが、同時に「これ以降、Python を積極的に勉強するモチベーションを維持できるかな」という懸念も出てきました。
他にも Dive Deep したいプログラミング言語はあるのですが、せっかくなので Python の勉強は継続したいなと思ってます。また何か Python における テーマをみつけて、そのテーマに沿って学んで、ブログに書いていきます!
そして、今回のチャレンジであらためて感じたことは、プログラミングは楽しい! コードを書くのは楽しい! ということです。
いろんな仕事に忙殺されてコードを書くことが少なくなっているのですが、もっと積極的にコードを書きたい!それが楽しい!と気づけたことも大きな収穫でした!
今後もプログラミングして、コードを書くことを楽しみたいです!
Python 3エンジニア認定 基礎試験の勉強記録:式の評価編
 先週から引き続き、あらためて Python を体系的に勉強してみて学べたことや、メモとして残しておきたいことなどを記載していきます。今回は 式の評価編 です。
先週から引き続き、あらためて Python を体系的に勉強してみて学べたことや、メモとして残しておきたいことなどを記載していきます。今回は 式の評価編 です。
さしあたってのゴールは、Python 3エンジニア認定 基礎試験 の合格ですが、Python というプログラミング言語の仕様の全てや、試験合格のコツを解説するのではなく、あくまで自分が気づけたことのメモであることはご了承ください!
目次
整数の真偽評価
整数を対象にした真偽評価は、ふだん使うことがないので練習問題ではひっかかってしまいました 💦 よってメモしておきます。
次のサンプルコードを実行すると、どのような結果になるでしょう?
result1 = 0 and 2 and -1 result2 = 0 or 2 or -1 print(result1) print(result2)
これを理解するには 2 つのポイントがあります。
まず 1 つは、Python において 整数を真偽評価する場合、0 が 偽(False) であり、0以外が 真 (True) であるということです。
そしてもう1つは、and や or をつかった真偽評価では、短絡評価となるという点です。
例えば、x and y の場合、まず x の評価を行い、結果が偽 (False) であれば、それ以上の評価は行わず、結果は x となります。
つまり、y の評価はパスされるわけです。もし x の評価が真 (True) の場合、y の評価も行われます。
ではそれをふまえて サンプル result1 = 0 and 2 and -1 を考えてみるとどうなるでしょう?
まず、
0 and 2の0を評価します。0は、偽 (False) なので、そこで評価は終わり、結果は0となります。つまり、
print(result1)の結果は、0となるわけです。
次に、or ですが、x or y の場合、まず x の評価を行い、結果が真 (True) であれば、それ以上の評価は行わず、結果は x となります。
つまり、y の評価はパスされるわけです。もし x の評価が偽 (False) の場合、y の評価も行われます。
では サンプル result2 = 0 or 2 or -1 を考えてみるとどうなるでしょう?
まず、
0 or 2の0を評価します。0は、偽 (False) なので、次に2を評価します。2は、真 (True) なので、そこで評価は終わり、結果は2となります。つまり、
print(result2)の結果は、2となるわけです。
よって、サンプルコードの結果は、下記のようになります。
0 2
Python 以外のプログラミング言語の知識があると、0 は False か True かの判定で混乱するかもしれませんね。気をつけたいです。
set を使用した集合演算
set はコレクションの一種で、下記のような特性をもちます。
- 要素を重複して保持しない
- 要素の挿入時の順序や位置を記録しない(順不同)
- 要素を追加する時は、add( ) を使う
- list 型の場合は append ( ) を使うので、間違えて覚えないように気をつけましょう!
また set を使用した集合演算も可能です。次のサンプルコードがどのような結果になるか考えてみましょう。
myset1 = {'1','2','3','4','5','6','7','8','9'}
myset2 = {'2','4','6','8','a','b','c'}
print(myset1 - myset2)
print(myset1 & myset2)
print(myset1 | myset2)
print(myset1 ^ myset2)
set を使用した集合演算では、演算子の意味を理解したうえでベン図で考えるとわかりやすいです。
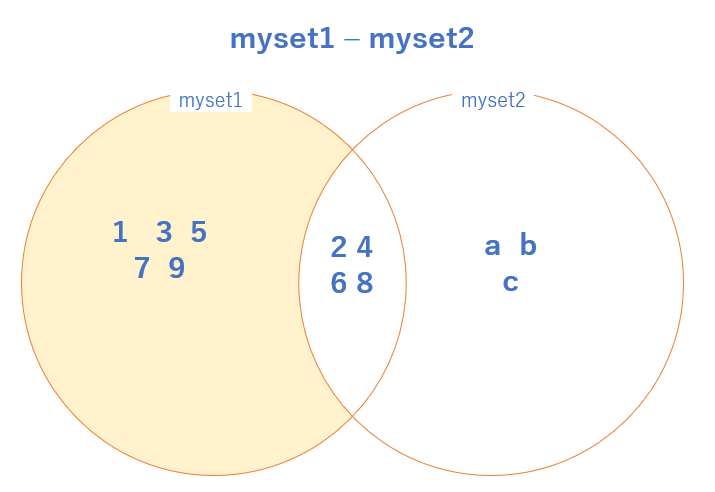
3 行目の print(myset1 - myset2) ですが、これは 差集合 の演算を行っています。
ベン図で書くと、背景色がついている部分が結果となります。
4 行目の print(myset1 & myset2) は 積集合 の演算を行っています。
ベン図で書くと、背景色がついている部分、つまり myset1 と myset2 の両方に重複して存在している要素が結果となります。

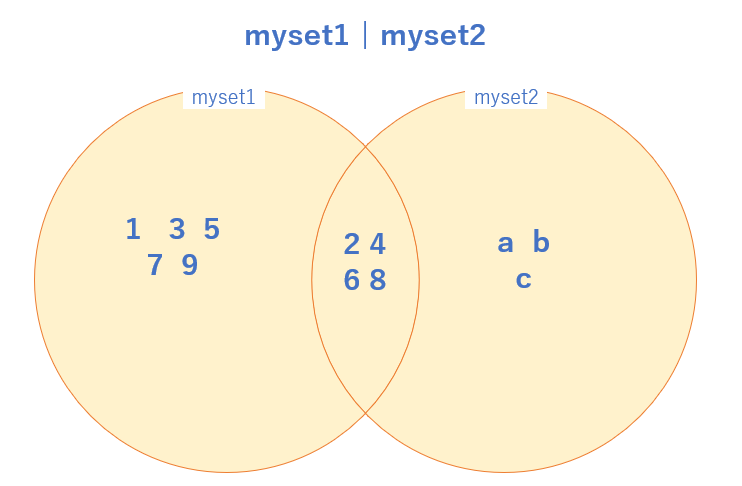
5 行目の print(myset1 & myset2) は 和集合 の演算を行っています。
ベン図で書くと、背景色がついている部分、つまり myset1 と myset2 のすべての要素が結果となります。
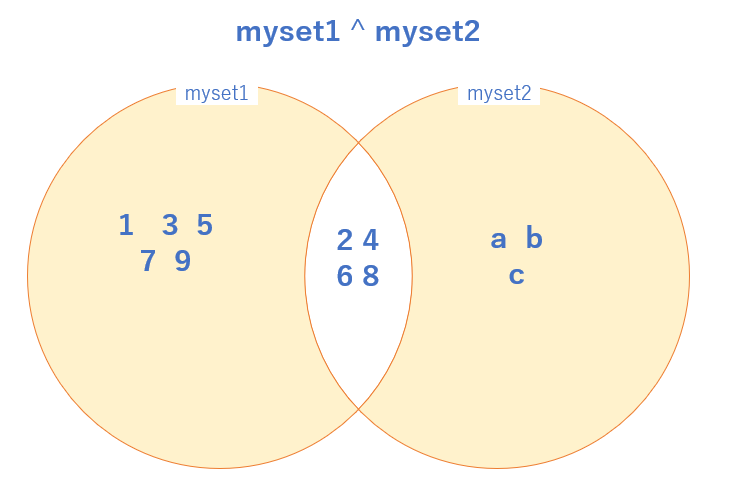
6 行目の print(myset1 ^ myset2) は 対称差集合 の演算を行っています。
ベン図で書くと、背景色がついている部分、つまり 積集合を除く部分が結果となります。
以上、まとめるとサンプルコードの実行結果(例)は下記になります。
{'9', '5', '1', '7', '3'}
{'2', '4', '6', '8'}
{'4', '9', '5', 'c', '6', 'b', 'a', '8', '1', '2', '7', '3'}
{'5', 'c', 'a', '1', '7', '9', 'b', '3'}
上記はあくまで例です。set では要素の順序は維持されないので出力する時も要素の順は不確定ですが、要素の値としてはベン図の通りになっていますね。
先日、Python 3エンジニア認定 基礎試験 の申し込みを完了して受験日が確定しました!
普段、よく受けている AWS の認定とは申し込み方法が違い、慣れていないので少し苦労しましたが受験日が決まったので計画的に勉強を進めて合格を目指します!
Python 3エンジニア認定 基礎試験の勉強記録:基本編
 Python はこれまで長い間、独学で なんとなく コードを書いてきたんですが、体系的に学んで理解を深めたいと思い至りました。
Python はこれまで長い間、独学で なんとなく コードを書いてきたんですが、体系的に学んで理解を深めたいと思い至りました。
ただ、目標設定をせずにプログラミング言語を学ぶと途中で飽きてしまいそうなので、Python 3エンジニア認定 基礎試験 の合格を目標することにしました。
このブログでは、あらためて Python を体系的に勉強してみて学べたことや、メモとして残しておきたいことなどを記載していきます。今回は 基本編 です。
Python というプログラミング言語の仕様の全てや、試験合格のコツを解説するのではなく、あくまで自分が気づけたことのメモであることはご了承ください!
なお、Python 3 エンジニア認定 基礎試験 の試験情報については下記を参照してください。
目次
Python プログラミングのスタイルガイド
Python では、プログラミングにおける推奨事項をまとめたスタイルガイド PEP (Python Enhancement Proposals) があります。この PEP の 8番目である通称 PEP 8 で最低限、覚えておこうと思ったものを列記します。
- インデント レベルごとに 4 つのスペースを使用する
- インデントではタブよりもスペースの方がのぞましい
- 1行の長さを最大79文字までに制限する
- 関数や変数の名前は小文字にする。読みやすくするために必要に応じて単語をアンダースコアで区切る
PEP 8 を読んでみると、何より重視しているのは 可読性 であることがわかります。スタイルガイドでありながら、ガイドラインに従うと可読性を損なわれる場合は敢えてガイドラインに準拠しないことも検討すべしと記載されています。実プロジェクトではチームでルールを決めることもありますし、可読性の判断基準も人によって異なる場合があるので、特定のガイドラインだけでガチガチに縛らない、というのは重要なことですね。
除算演算子 / による演算結果
試験の練習問題でひっかかってしまったので、シンプルな例でメモしておきます。
result = 5 / 5 print(result)
上記のコードで、print 関数の実行結果はどうなるでしょう?
正解は、1.0 になります。つまり、除算の対象が整数同士であっても結果は浮動小数点型になります。
1 ではないので注意したいです。
文字列のスライス
次のサンプルコードをみてみましょう。
message = "Hello" sliced_message1 = message[2:4] print(sliced_message1) sliced_message2 = message[-3:] print(sliced_message2)
このサンプルのように、文字列をスライスする場合は、下図のように 0 から番号をつけた区切り線をいれる とわかりやすいです。

サンプルコードだと、sliced_message1 には、2 番の区切り線から 4 番の区切り線の間の文字が代入されるので、ll になります。
スライスする数字がマイナスの場合は、文字列の最後から 1文字目に -1 の区切り線とします。そうすると、sliced_message2 には、-3番の区切り線からすべての文字が代入されるので、llo になるわけです。
文字列のスライスにおいて、リストのインデックスのように 1 つ 1 つの文字に番号をつけて考えた場合だとどうでしょう? その場合、サンプルでは、H がインデックス 0で、e が インデックス 1となり、[2:4] の指定なら インデックス 2 の l を含んで インデックス 4 の o は含まないことになります。 よって、[2:4] なんだけど、対象になるのは 2 から 4 までではなく 2 から 3 までと覚える必要があります。 それよりも、上図のように番号をつけた区切り線をいれて、その番号で考えたほうがシンプルといえます。
format メソッド
文字列のフォーマット指定に使用できる format メソッドのパターンをメモしておきます。
num1 = 10 num2 = 20 # これは OK print("num1は {0} です。num2は {1} です。".format(num1,num2)) print("num1は {} です。num2は {} です。".format(num1,num2)) print("num1は {val1} です。num2は {val2} です。".format(val1=num1,val2=num2)) print("num1は {num1} です。num2は {num2} です。".format(num1=num1,num2=num2)) # これは NG print("num1は {num1} です。num2は {num2} です。".format(num1,num2))
上記のサンプルコードの 4 行目から 7行目はすべて num1は 10 です。num2は 20 です。 と表示されますが、 9 行目では KeyError になります。
{ } (フォーマットフィールド) には、引数の変数名は、そのまま記述できないということですね。その点は f 文字列を使用したフォーマットとは違うので、ごっちゃにしないように注意したいです。
num1 = 10 num2 = 20 # f 文字列を使ったフォーマット print(f"num1は {num1} です。num2は {num2} です。")
やはり 体系的に学ぶ ことで、これまでは正確に理解できていなかったことを学べてよい刺激になりますね! 今回は基本編でしたが、次回も引き続き Python 3エンジニア認定 基礎試験の勉強記録を書く予定です!
今さらながら GitHub Actions をさわってみる: (AWS SAM のデプロイ編)
前回の記事では、GitHub Actions のワークフローから AWS アカウントへのアクセス方法を確認しました。
その方法を用いて、今回は AWS アカウントへサーバーレスアプリケーションのビルドとデプロイを行ってみます。
アプリケーションは、Amazon API Gateway と AWS Lambda を使用して HelloWorld メッセージを返すだけのシンプルなものです。
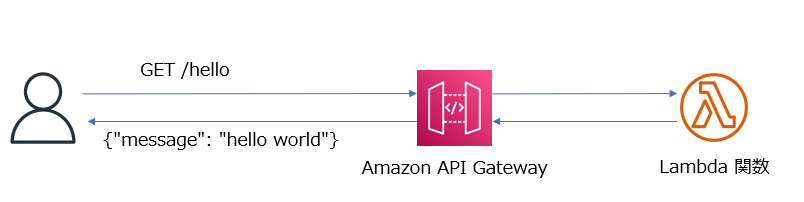
このようなシンプルなものであれば、AWS SAM ( Serverless Application Model ) の事前定義済のアプリケーションテンプレートを用いるとすぐに作成することができます。
この AWS SAM を使用してデプロイを行うワークフローを作成し、実際にデプロイするまでの手順を記載していきます。
なお、この記事の内容は 2023 年 3月時点で検証した内容に基づいています。また記事の中の AWS アカウント IDはすべて 0 で表記しています。
手順の概要
- GitHub でリポジトリを作成する
- デプロイ先の AWS アカウントの IAM で ID プロバイダの設定と IAM ロールの作成を行う
- GitHub でリポジトリで IAM ロールの ARN の値を Secret として保存する
- AWS SAM のリソースを作成する
- GitHub Actions のワークフローの YAML ファイルを作成する
- リポジトリに push してワークフローの実行結果を確認する
1. GitHub でリポジトリを作成する
任意の名前でリポジトリを作成します。
この名前は、次の IAM ロール作成時に必要になります。
2. デプロイ先の AWS アカウントの IAM で ID プロバイダの設定と IAM ロールの作成を行う
ID プロバイダの設定については前回の記事(下記)で説明している手順通りです。一回、設定していれば改めて設定する必要はありません。
IAM ロールの作成では、今回は ワークフローから AWS SAM CLI のコマンドを実行してデプロイを行いますので、そのために必要なポリシーを設定した IAM ロールを作成します。
これも前回の記事の内容を参考に行えます。
ただし、許可ポリシーは下記のように AWS SAM によるデプロイを許可する内容にします。
許可ポリシーの例は、以前に紹介した記事(下記)にありますので、これを利用します。
また、信頼ポリシーは使用するリポジトリに合わせて下記のように設定します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::000000000000:oidc-provider/token.actions.githubusercontent.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "token.actions.githubusercontent.com:aud": "sts.amazonaws.com" }, "StringLike": { "token.actions.githubusercontent.com:sub": "repo:<GitHubユーザーID>/<GitHubリポジトリ名>:*" } } } ] }
IAM ロールを作成したら、ARN の値をメモしておきます。これは次の手順で使用します。
3. GitHub でリポジトリで IAM ロールの ARN の値を Secret として保存する
前の手順でメモしておいた IAM ロールの値を、GitHub リポジトリの Secretとして保存します。
この手順も前回の記事を参考に行えます。
4. AWS SAM のリソースを作成する
AWS SAM CLI をインストールしている環境で、初期化を行います。
利用する AWS SAM CLI のバージョンは、 1.76.0 以降を前提としています。
sam --version SAM CLI, version 1.76.0
今回は、Python 3.8 をラインタイムとして指定します。X-Ray トレースや Amazon CloudWatch Application Insights のモニタリング を無効化する前提です。
--name は、任意の名前を設定します。
sam init --runtime python3.8 \ --app-template hello-world \ --name actions-aws-sam \ --no-tracing \ --no-application-insights
--name で指定したフォルダが作成されるので、そこに移動し、git init と git remote add を実行します。
cd actions-aws-sam git init git remote add origin https://github.com/<GitHubユーザーID>/<GitHubリポジトリ名.git
この段階で、AWS SAM CLI により HelloWorld メッセージを出力する Python の AWS Lambda 関数と、それと統合した Amazon API Gateway の API のリソースは揃っています。
ただ 今回は、GitHub Actions のワークフローからデプロイする際に必要な AWS SAM の細かいパラメータは、ファイルに保存しておくようにしたいと思います。
そのため、--name で指定したフォルダ に、samconfig.toml というファイルを作成し、下記の内容を指定して保存します。
version=0.1 [default.deploy.parameters] stack_name = "<任意のスタック名>" s3_bucket = "<AWS SAM のリソースをアップロードする S3バケット名>" s3_prefix = "<上記 S3 バケットのフォルダ名>" confirm_changeset = false capabilities = "CAPABILITY_IAM"
s3_bucket で指定するバケットはあらかじめ作成しておきましょう。s3_prefix で指定した名前は S3 バケットのフォルダになり、任意の名前を設定できますがあらかじめフォルダを作成しておく必要はありません。
これで AWS SAM のリソースの準備は完了です。
5. GitHub Actions のワークフローの YAML ファイルを作成する
では、AWS SAM リソースをデプロイするワークフローの YAML を 作成します。
--name で指定したフォルダ の下に .github/workflows フォルダ作成して、そこに 任意の名前の YAML ファイルを作成します。
内容については、下記のドキュメントにサンプルがあるので、これを活用します。
ただし、このサンプルでは OIDC を使用せず Secret に AWS アカウントの認証情報を指定していますので、この部分は OIDC を使うように変更します。
また、--no-confirm-changeset オプションは すでに samconfig.toml 内で指定しているので、このオプションの指定も削除します。
on: push: branches: - main env: AWS_REGION : "ap-northeast-1" # permission can be added at job level or workflow level permissions: id-token: write # This is required for requesting the JWT contents: read # This is required for actions/checkout jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - uses: actions/setup-python@v3 - uses: aws-actions/setup-sam@v2 - uses: aws-actions/configure-aws-credentials@v1 with: role-to-assume: ${{ secrets.AWS_ROLE_ARN }} role-session-name: samplerolesession aws-region: ${{ env.AWS_REGION }} - run: sam build --use-container - run: sam deploy --no-fail-on-empty-changeset
ポイントは 17 行目の - uses: aws-actions/setup-sam@v2 ですね。 AWS SAM を使用するためのアクションがあるので、それを使用することで ワークフローから AWS SAM CLI を実行できます。
これでワークフローの準備も完了しました。
6. リポジトリに push してワークフローの実行結果を確認する
では、いよいよ リポジトリに push してワークフローを実行します。
git add. git commit -m "commit sam resource" git push -u origin main
無事に ワークフローが完了していれば、下図の赤枠の Run sam deploy のステップを展開表示してみましょう
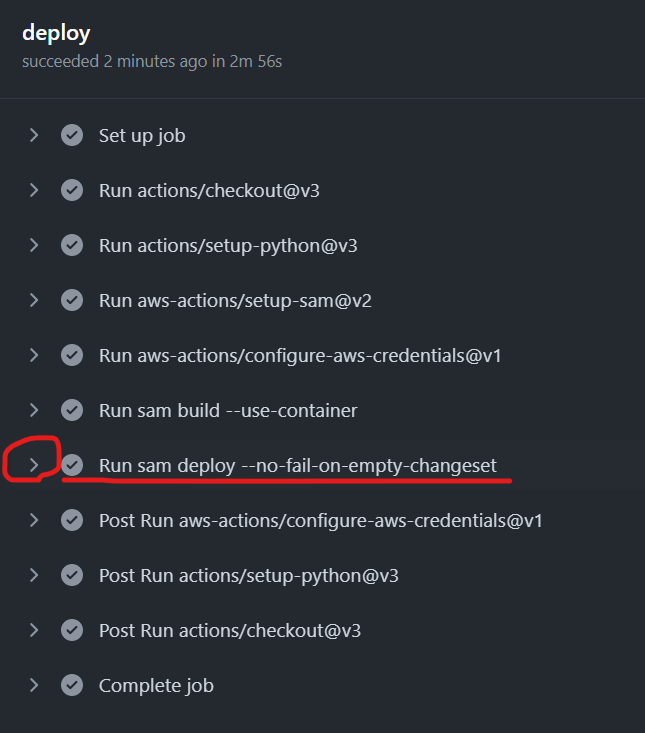
AWS SAM による deploy の結果として、Outputs セクションが表示されています。
CloudFormation outputs from deployed stack ---------------------------------------------------------------------------------- Outputs ---------------------------------------------------------------------------------- Key HelloWorldFunctionIamRole Description Implicit IAM Role created for Hello World function Value arn:aws:iam::***:role/actions-aws-sam-stack- HelloWorldFunctionRole-WCPOUUNE5S2W Key HelloWorldApi Description API Gateway endpoint URL for Prod stage for Hello World function Value https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/
その中の Key が HelloWorldApi の Value のURL の値をコピーして Web ブラウザでアクセスします。
結果、下記のようなメッセージが表示されればアプリケーションが正常にデプロイされています。
{"message": "hello world"}
今回の所感
今回で GitHub Actions のワークフローを使用し、AWS SAM によるアプリケーションのデプロイができました。
知識ゼロのところから、下記の記事を書き連ね、コツコツと学んで積み上げてきた知識を組み合わせて実現できたと感じています。
今回は GitHub Actions 側の視点から AWS SAM を使用する方法を確認しましたが、AWS SAM には、実は GitHub Actions のワークフローを自動生成する機能があります。
これも一応触ってみたので、また別の機会に記事で紹介したいと思います。


今さらながら GitHub Actions をさわってみる: (AWS へのアクセス編)
前回、前々回に引き続き、GitHub Actions のワークフローを触っていきます。
今回は、ワークフローから AWS アカウントへアクセスする方法を整理しつつ、実際にアクセスを試していきます。
最終的には、GitHub Actions を使用して アプリケーションをビルドし、AWS アカウントにデプロイするワークフローを作成しようと思っているので、AWS アカウントへのアクセス方法の理解はその事前準備となります。
なお、この記事は 2023 年 3 月時点で検証した内容に基づいて記載しています。
目次
- AWS アカウントへアクセスする方法の整理
- 方法 1. AWS のアクセスキー ID やシークレットアクセスキー を GitHub の Secret として保存してワークフローから使用する方法
- 方法 2. GitHub の OpenID Connect (OIDC) プロバイダを使用し、AWS アカウントにアクセスできるトークンを使用する方法
- 今回の所感
AWS アカウントへアクセスする方法の整理
まず、GitHub のドキュメントを参照して AWS アカウントへのアクセス方法を整理してみましたが、基本的には下記の 2パターンがあるようです。
- AWS のアクセスキー ID やシークレットアクセスキー を GitHub の Secret として保存してワークフローから使用する方法
- GitHub の OpenID Connect (OIDC) プロバイダを使用し、AWS アカウントにアクセスできるトークンを使用する方法
セキュリティの観点から上記 2 の方法が推奨 のようですが、とりあえず両方の方法を試します。
方法 1. AWS のアクセスキー ID やシークレットアクセスキー を GitHub の Secret として保存してワークフローから使用する方法
GitHub の Secret については、次のドキュメントに記載があります。AWS アカウントのアクセスキーなど、秘匿すべき認証情報を保存する用途に使えそうです。
この Secret を使ったワークフローのイメージ図を描いてみました。
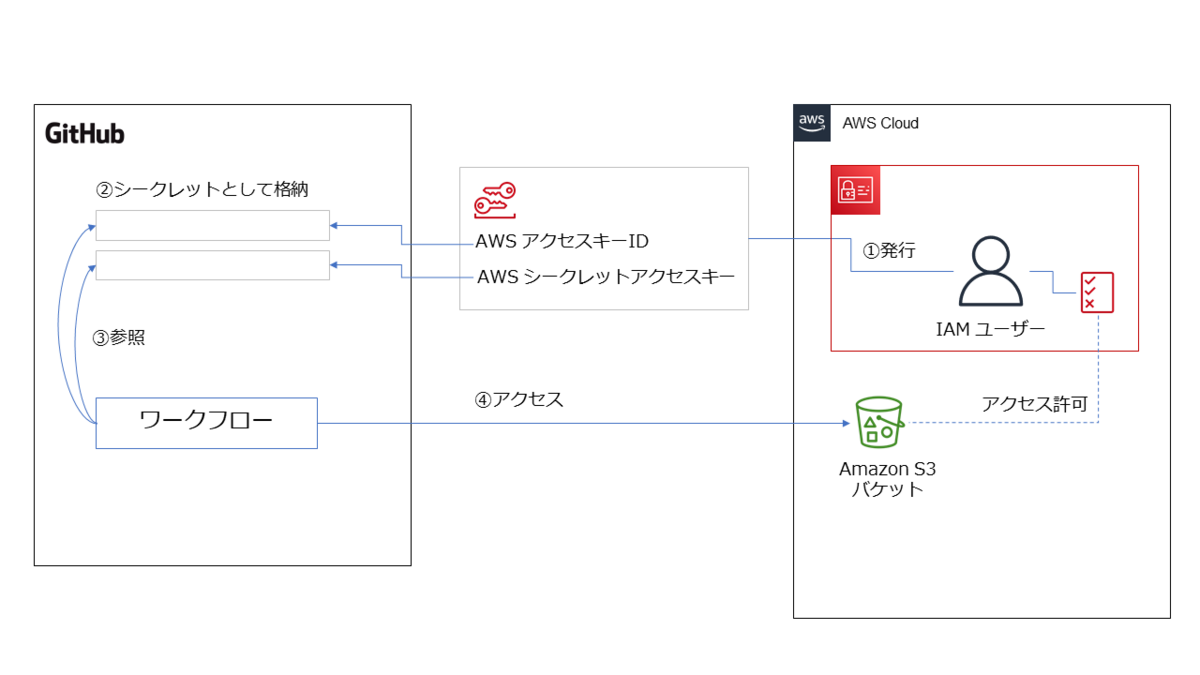
上図のように、仕組みとしてはシンプルでわかりやすいですよね。
ただし、前述のようにこの方法はお薦めできません。
Secret という仕組みはあるにせよ、永続的に使用できるアクセスキー ID を発行してそれを一つの場所にずっと保管することはセキュリティ面での懸念があるからです。
後で説明する 2番目の方法のように、必要なタイミングで一時的に使用できるトークンを発行して使用する 方が望ましいのですが、今回は勉強の一環として試してみました。
まず、AWS アカウントで 下記の IAM ポリシーを作成します。(ここでは便宜上、s3-listAllMyBuckets-policy と名付けます。)
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" } ] }
次に IAM ユーザーを作成して作成した s3-listAllMyBuckets-policy を設定し、アクセスキーID とシークレットアクセスキーを発行します。
そのアクセスキーID とシークレットアクセスキーを GitHub の Secret として設定します。
設定方法は、Web ブラウザからでも GitHub CLI からでも可能です。
Web ブラウザの場合は、対象リポジトリのページから [ Settings ] タブ、左側のメニューで [ Secrets and variables ] - [ Actions ] を選択して、右上の [ New repository secret ] を選択して設定します。設定した Secret の名前は後でワークフローの中で指定します。
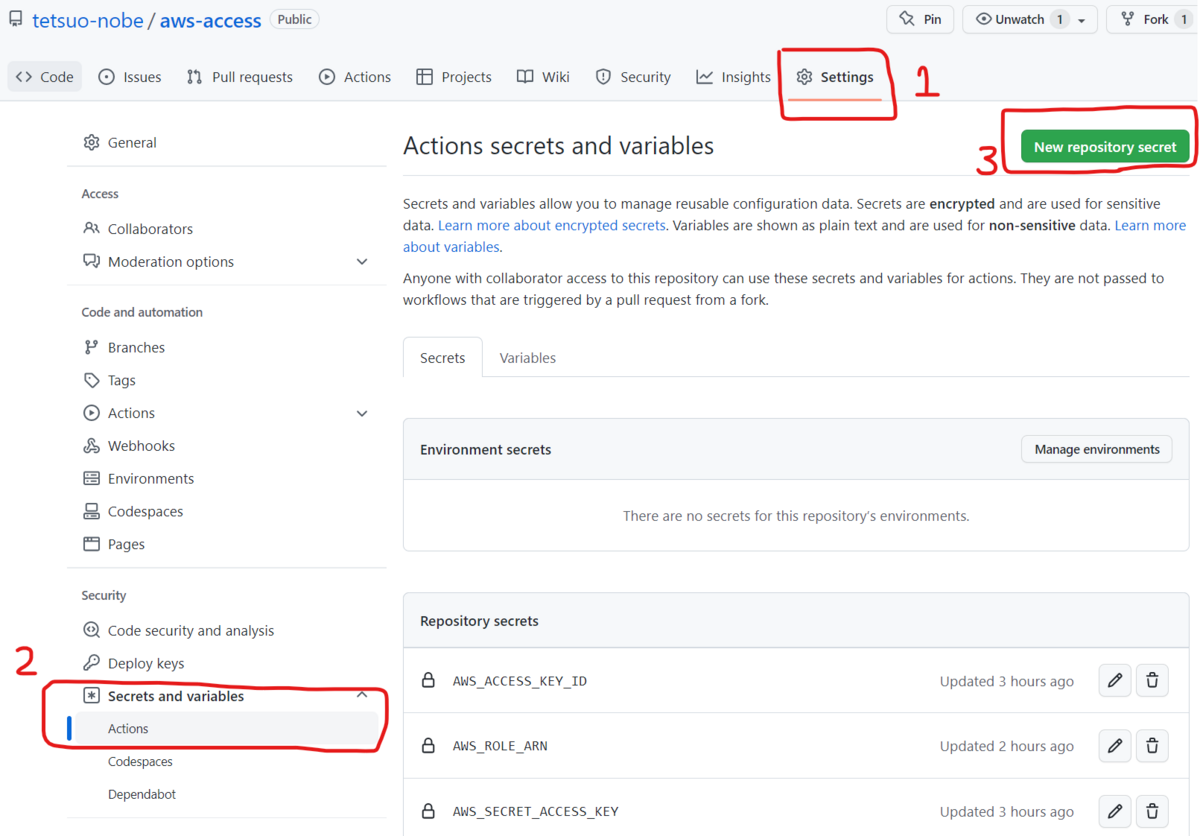
では次にワークフローの YAML ファイルを作ります。
今回は、下記のドキュメントを参考にしました。
ただし、今回は AWS アカウントへのアクセスを試すのが目的なので、 AWS SAM は使用せず、AWS CLI のコマンドを aws s3 ls を発行するだけのシンプルなワークフロー(下記)に変えることにしました。
aws s3 ls が正常に実行され、Amazon S3 バケットの一覧が表示されれば AWS アカウントへアクセスできたという確認になります。
name: AWS access using secrets in GitHub on: push: branches: - main jobs: list-s3-buckets-using-Secret: runs-on: ubuntu-latest steps: - name: configure aws credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: execute AWS CLI run: aws s3 ls
上記の YAML でポイントになるのは、10 行目から 15 行目のステップです。
aws-actions/configure-aws-credentials というアクションを用いることで、AWS アカウントのアクセスするための認証情報をセットして、AWS CLI も利用できるようになります。
そのため、次の 16 行目からのステップでは、すぐに AWS CLI で aws s3 ls を実行しています。
このワークフローを実行すると、正常に Amazon S3 バケットの一覧が表示されました。
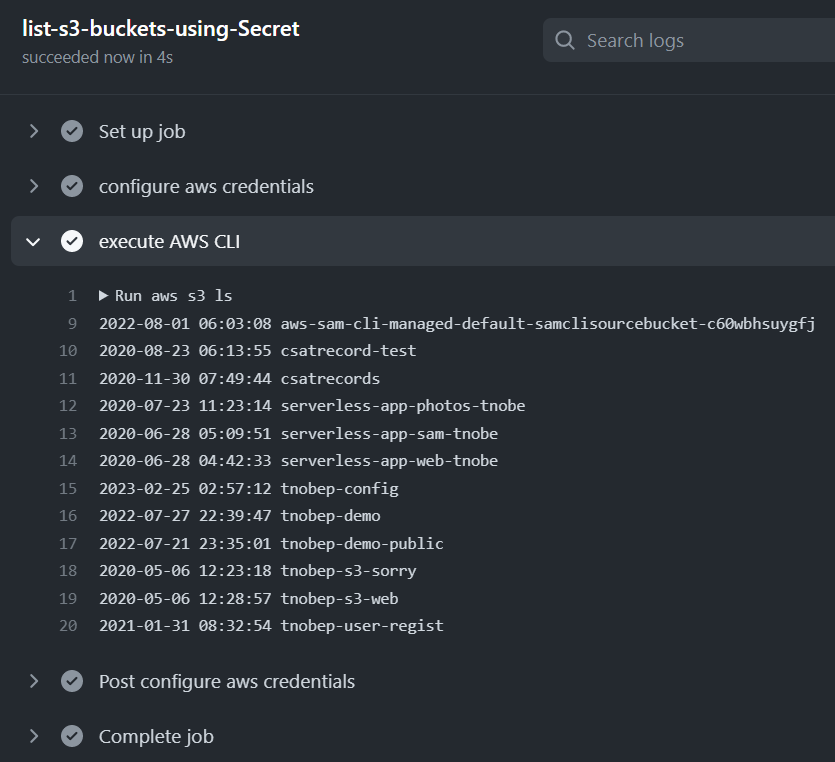
GitHub のワークフローから AWS アカウントへアクセスを確認できたわけです。
方法 2. GitHub の OpenID Connect (OIDC) プロバイダを使用し、AWS アカウントにアクセスできるトークンを使用する方法
ただ、(繰り返しになりますが)前述の方法 1 よりもお薦めなのが この OIDC を使用する方法です。
下図は、この仕組みを図にしてみたものです。
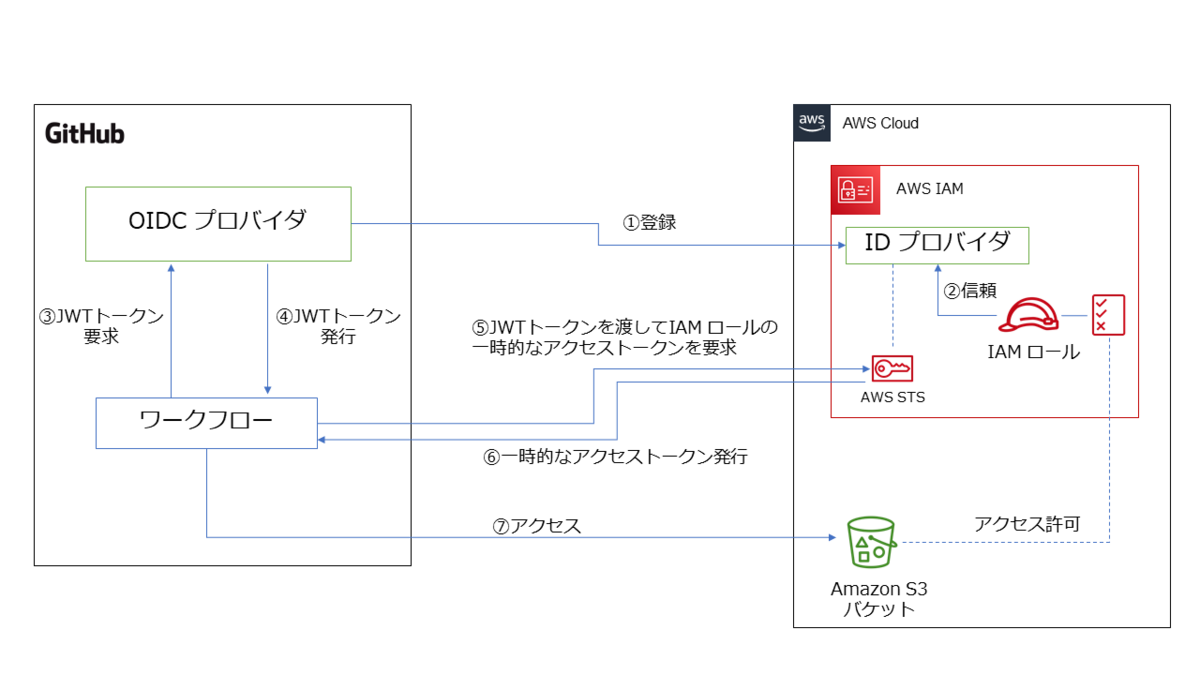
方法 1 よりは複雑に感じるかもしれませんが、要するに AWS アカウントがGitHub の OIDC プロバイダを信頼する ことで、その OIDC プロバイダが発行した JWT (ジョット)トークンがあれば AWS の IAM ロールを使用できるようにする仕組みです。
GitHub の OIDC プロバイダが発行するJWTトークンがあれば、AWS 側からアクセストークンが発行されるので、そのアクセストークンで AWS アカウントにアクセスすれば、事前に設定した IAM ロールに紐づく IAM ポリシーの権限の範囲で AWS リソースを操作できます。
この仕組みを実現するには、まず GitHub の OIDC プロバイダを AWS アカウント側に登録します。
この方法は、GitHub の下記のドキュメントにも記載されています。
この登録ですが、AWS マネジメントコンソールでも AWS CLI でも行えますが、個人的には AWS マネジメントコンソール を使う方が簡単 でお薦めです。
その理由は、OIDC プロバイダ登録時には TLS 証明書のサムプリント ( thumbprint ) の値が必要なのですが、AWS CLI の場合は、事前に様々なコマンドを発行したり編集したりしてそのサムプリントの値を自分で導出したうえでパラメータに指定する必要があるのに対して、AWS マネジメントコンソール ではサムプリントの値は自動的に取得、設定可能なためです。
参考として下記のドキュメントを紹介しますので、興味があれば実施してみて下さい。
ここではシンプルに設定できる AWS マネジメントコンソールを使用する方法を紹介します。
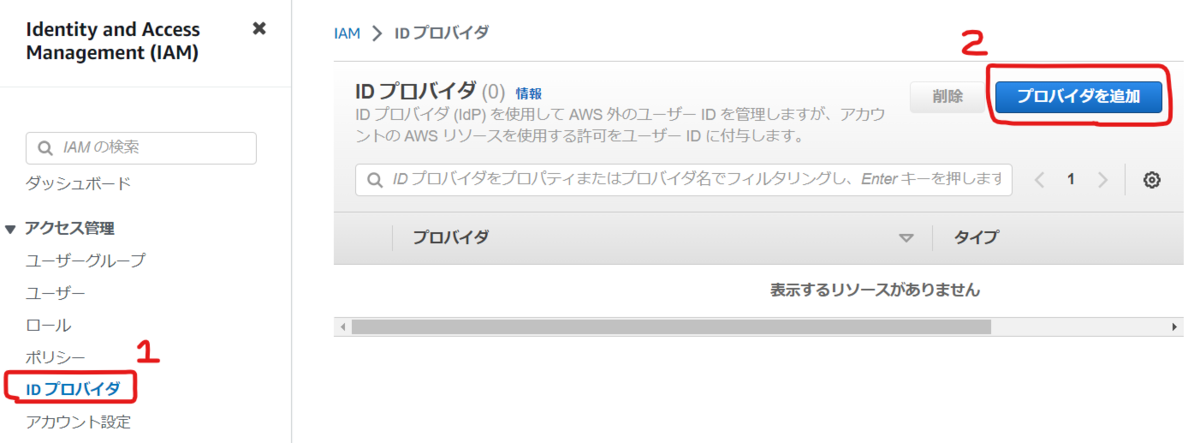
まず IAM のコンソールの左側のメニューから [ アクセス管理 ] - [ ID プロバイダ ] を選択し、右側にある [ プロバイダを追加 ] を選択します。
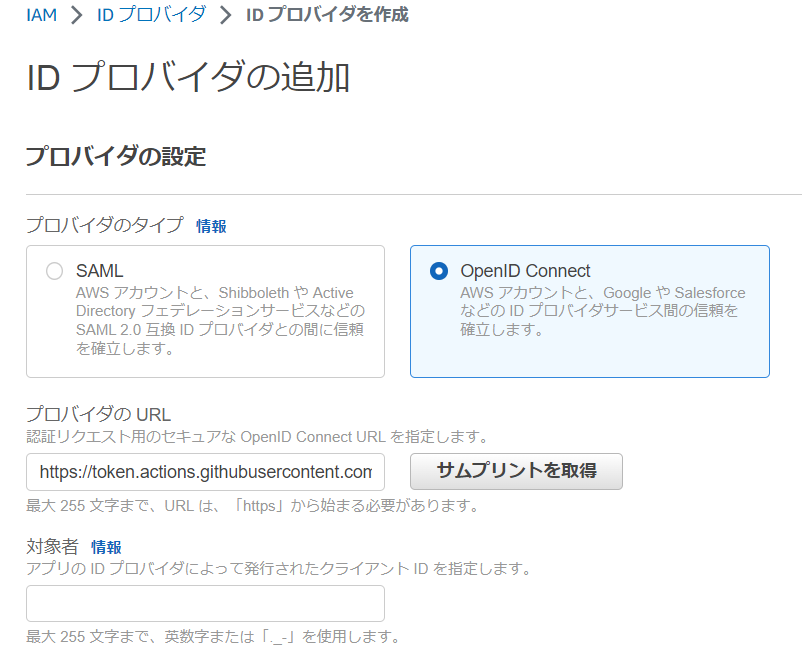
[ プロバイダのタイプ ] に [ OpenID Connect ] を選択します。
[ プロバイダの URL ] に https://token.actions.githubusercontent.com を入力して [ サムプリントを取得 ] を選択します。
その後、その下にある [ 対象者 ] に sts.amazonaws.com と入力して、ページ右下にある [ プロバイダを追加 ] をクリックします。
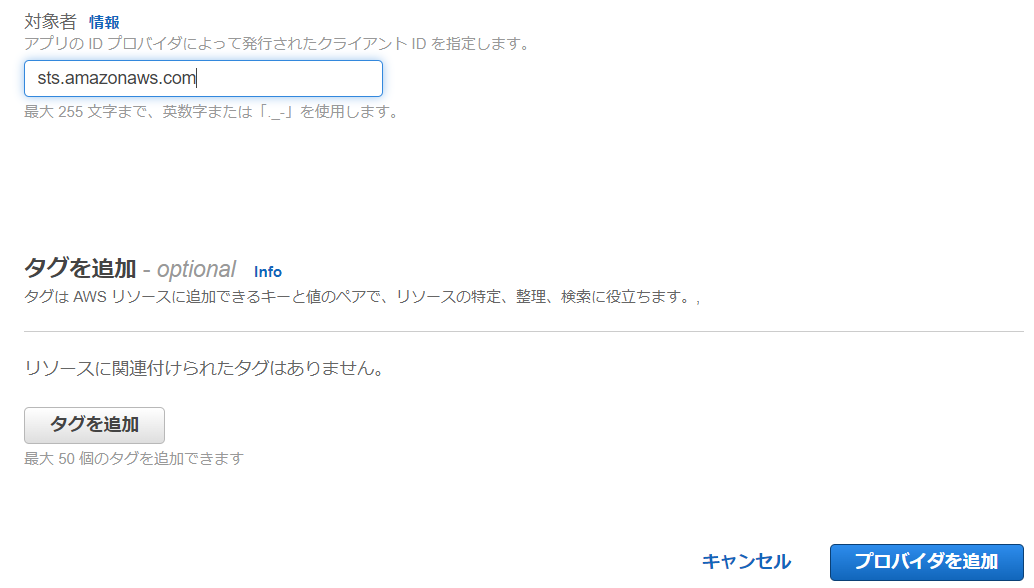
これで OIDC プロバイダの登録は完了です。
次に、この OIDC プロバイダを信頼する IAM ロールを作成します。
AWS マネジメントコンソールで作成する場合は、IAM のページから左側のメニューで[ アクセス管理 ] - [ ロール ] を選択し、右側にある [ ロールを作成 ] を選択します。
[ 信頼されたエンティティを選択 ] のページで [ 信頼されたエンティティタイプ ] に [ ウェブアイデンティティ ] を選択します。
[ アイデンティティプロバイダー ] に [ token.actions.githubusercontent.com ] を選択します。
[ Audience ] に [ sts.amazonaws.com ] を選択して、[ 次へ ] を選択します。

その後は、方法 1 で作成した s3-listAllMyBuckets-policy の IAM ポリシー(下記)を許可ポリシーとして設定します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" } ] }
ロールの名前は任意の値を入力してロールを作成します。今回の例では、s3-listAllMyBuckets-role とします。
これでロールは作成したのですが、ロールの信頼ポリシーで GitHub のリポジトリを限定するように条件を追加しておきましょう。
作成したロールの名前をクリックして、[ 信頼関係 ] タブを選択して、[ 信頼ポリシーを編集 ] を選択します。
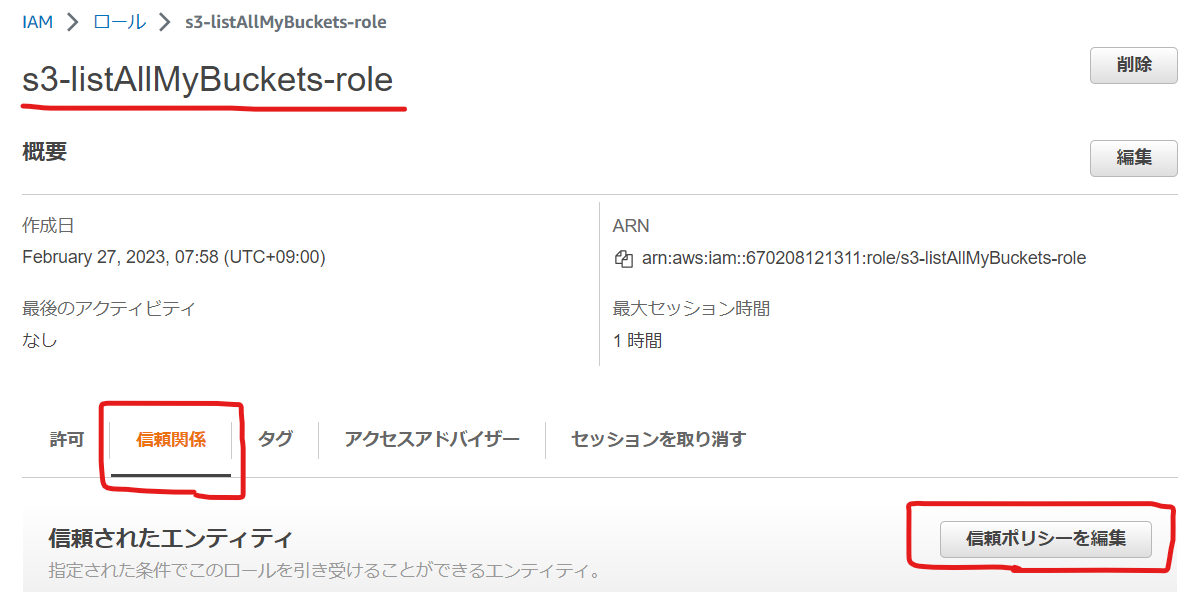
そしてポリシーの Condition に下記を追加します。
これは、GitHub の特定のリポジトリだけを対象に IAM ロールの引き受けを可能にするための条件設定です。
セキュリティの面から IAM ロールを引き受けを認める範囲を限定する必要があるため、必ず設定して下さい。
"StringLike": {
"token.actions.githubusercontent.com:sub": "repo:<GitHubのユーザーID>/<GitHubのリポジトリ名>:*"
}
下記は、条件を追記した信頼ポリシー全体の例です。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::111111111111:oidc-provider/token.actions.githubusercontent.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "token.actions.githubusercontent.com:aud": "sts.amazonaws.com" }, "StringLike": { "token.actions.githubusercontent.com:sub": "repo:tetsuo-nobe/aws-access:*" } } } ] }
これで AWS アカウント側の事前準備は終わったので、GitHub のワークフローを作成していきます。
下記のドキュメントにワークフローの例があるので、これを参考に方法 1 と同じく AWS CLI で aws s3 ls を実行するワークフローを作成します。
ただ、上記のドキュメントの例をみて、おや❓ と感じました。
ワークフローの YAML には、引き受ける IAM ロールの ARN を指定する必要がありますが、この例では、ワークフローが引き受ける IAM ロールの ARN の値を YAML ファイルにそのまま記述しています。
しかし、ARN には AWS アカウント ID の 12桁の数字も含まれるので、YAML ファイルにそのまま記述するのは避けたいですよね。
ということで、IAM ロールの ARN は GitHub の Secret に保存し、それを参照することにしました。
OIDC の方法を用いれば Secret は使わなくてもいいかなと思っていたのですが、やはり AWS アカウントID は秘匿しておきたいですよね。
結果、完成した ワークフローの YAML が下記です。
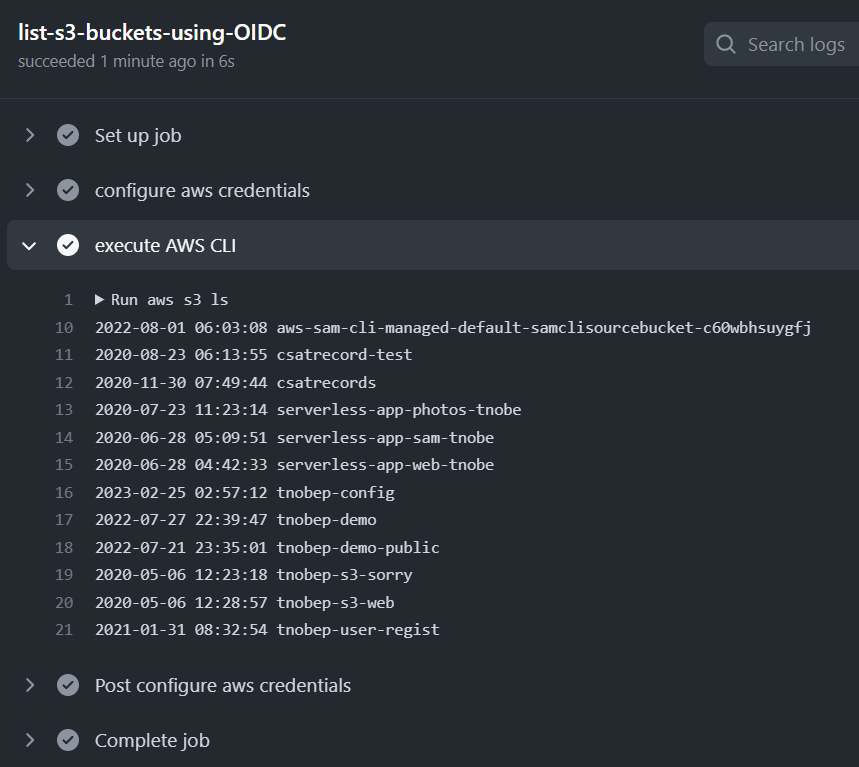
name: AWS access using OIDC provider on: push: branches: - main env: AWS_REGION : "ap-northeast-1" # permission can be added at job level or workflow level permissions: id-token: write # This is required for requesting the JWT contents: read # This is required for actions/checkout jobs: list-s3-buckets-using-OIDC: runs-on: ubuntu-latest steps: - name: configure aws credentials uses: aws-actions/configure-aws-credentials@v1 with: role-to-assume: ${{ secrets.AWS_ROLE_ARN }} role-session-name: samplerolesession aws-region: ${{ env.AWS_REGION }} - name: execute AWS CLI run: aws s3 ls
19 行目では、Secret を使って IAM ロールの ARN を取得するようにしています。
実行してみると、下図のように aws s3 ls が正常に実行されたことを確認できました。
今回の所感
今回の記事の中で紹介した OIDC を使用する方法により、 AWS のアクセスキー ID を発行して GitHub 側に保存しなくても AWS アカウントへアクセスできるが確認できました。
この方法を理解できたことで、GitHub Actions を使用して AWS アカウントへ アプリケーション環境を構築するワークフローの作成方法のイメージが大きく膨らんできました!
次回は、今回の記事の内容をベースにしつつ、AWS アカウントへアプリケーション環境を構築するワークフローを作成したいと思います!
今さらながら GitHub Actions をさわってみる: (Javaのビルド編)
さて前回から GitHub Actions のワークフローいろいろと触っているのですが、今回はその続きとしてシンプルな Java の Webアプリケーションをビルドするワークフローを作成してみます。
とはいえ、GitHub Actions の初心者としては、ワークフローの YAML をどう記述すればいいのか、わかりません。
しかし、下記のドキュメントの内容が参考になりました。
GitHub Actions には スターターワークフロー という事前定義済のワークフローがいくつか用意されており、その中に Maven で Java アプリケーションをビルドするものもあるようです。(他にも、ビルドに Gradle や Ant を使うものもあるようです。)
これを使えば、一から ワークフローの YAML ファイルを自分で作成する必要がないので、初心者としては助かります。
すでに手元で、Maven でビルドする Java の Webアプリケーションのソースが一式あるので、今回はこの Maven でビルドを行うスターターワークフローを使っていきます。
なお、この記事の内容は 2023年 2月時点で確認した内容に基づきます。
スターターワークフローの選択
GitHub のリポジトリのページで Actions タブを選択したとき、まだワークフローを 1つも作成していなければ自動的にスターターワークフローを選択できるページが表示されます。
1 つでもワークフローを作成すると、下図の赤枠にある [New workflow] をクリックすることで、スターターワークフローを選択できるページが表示されます。
下図は、[New workflow] をクリックした後のイメージです。
赤枠のパネルに、Java with Maven とありますね。
このパネル内の Configure をクリックすると、リポジトリに直接ワークフローの YAML を追加するためのページに遷移します。
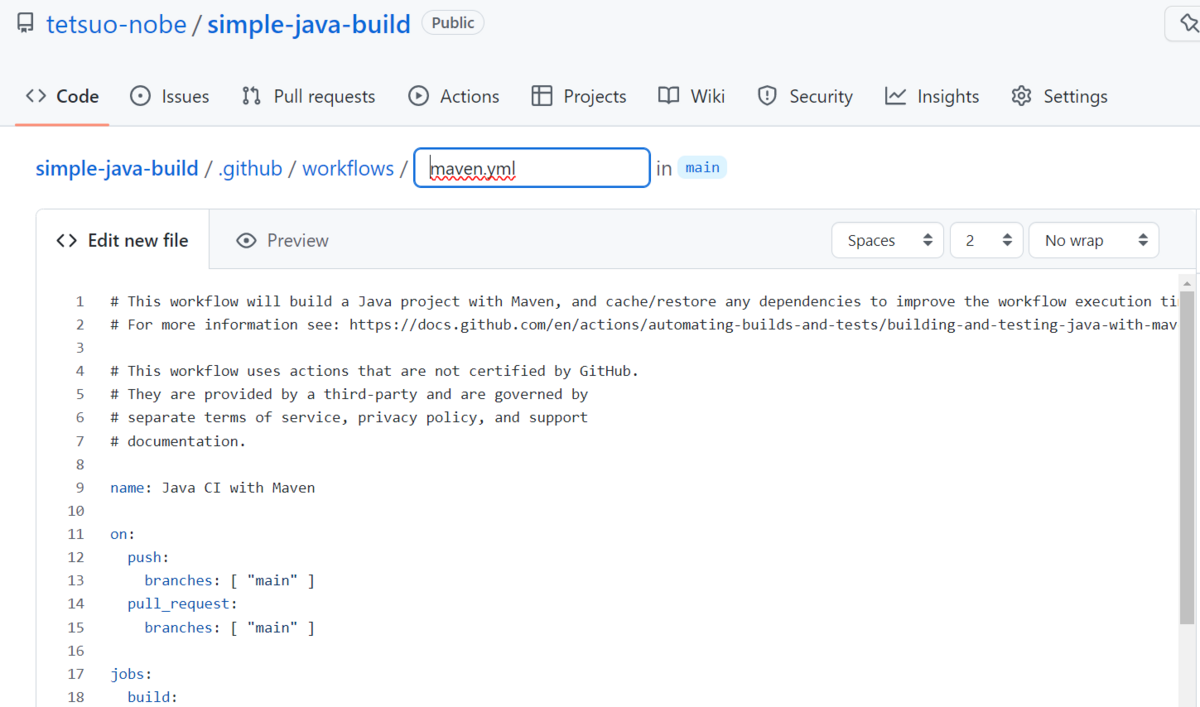
ただ、今回は 手元の PC でローカルのリポジトリで編集して リモートに push するという流れにしていますので、このページでは YAML だけコピーして [Cancel Changes] ボタンを選択します。
スターターワークフローの YAML を少し編集する
リポジトリに ビルド対象の Spring Boot の Java アプリケーションのソースや、Maven でビルドするための pom.xml などを一式用意します。
そして、.github/workflows フォルダにワークフローの YAML ファイルを作成します。
この YAML ファイルに、Java with Maven のスターターワークフローの内容をコピーしました。
ざっと内容をみると、ビルド用の JDK を用意して、Maven のコマンドでビルドしていることがわかりますね。
ただし、29行目以降はコメントアウトしました。
# This workflow will build a Java project with Maven, and cache/restore any dependencies to improve the workflow execution time # For more information see: https://docs.github.com/en/actions/automating-builds-and-tests/building-and-testing-java-with-maven # This workflow uses actions that are not certified by GitHub. # They are provided by a third-party and are governed by # separate terms of service, privacy policy, and support # documentation. name: Java CI with Maven on: push: branches: [ "main" ] pull_request: branches: [ "main" ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - name: Set up JDK 11 uses: actions/setup-java@v3 with: java-version: '11' distribution: 'temurin' cache: maven - name: Build with Maven run: mvn -B package --file pom.xml - name: list artifact run: ls -laR target # Optional: Uploads the full dependency graph to GitHub to improve the quality of Dependabot alerts this repository can receive # - name: Update dependency graph # uses: advanced-security/maven-dependency-submission-action@571e99aab1055c2e71a1e2309b9691de18d6b7d6
29行目以降はコメントアウトした理由は、今回は不要だから です。
29行目以降で実施しているのは、Dependency graph を作成するための処理です。この処理を正常に実行するためには、リポジトリの権限設定を変更しなければならないことがわかりました。
今回の目的はあくまで シンプルな Java のアプリケーションのビルドを行うワークフローを動かすことですので、Dependency graph は不要と判断しコメントアウトにしました。
なお、Dependency graph については下記に説明がありますので、参考にしてください。
また、一番最後に下記のステップを追加しました。
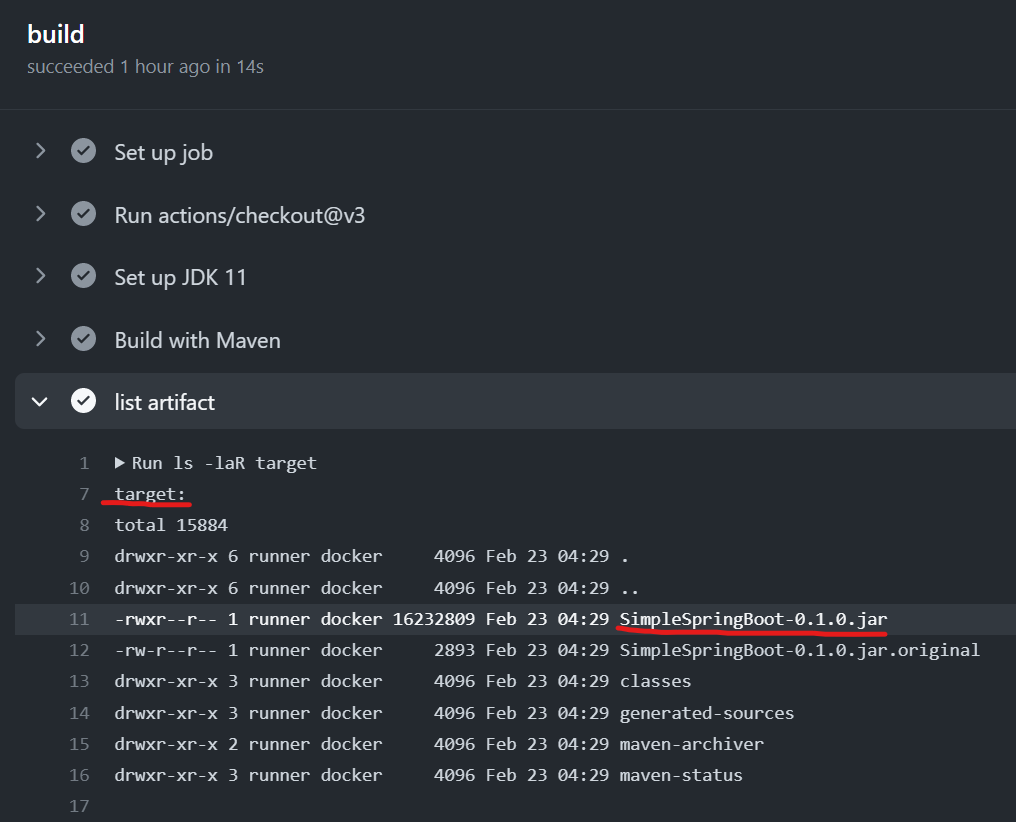
- name: list artifact run: ls -laR target
これは、Maven でビルドした後の生成物として、SpringBoot の Java のアプリケーションの JAR ファイルが生成されているかを確認するために追加したステップです。
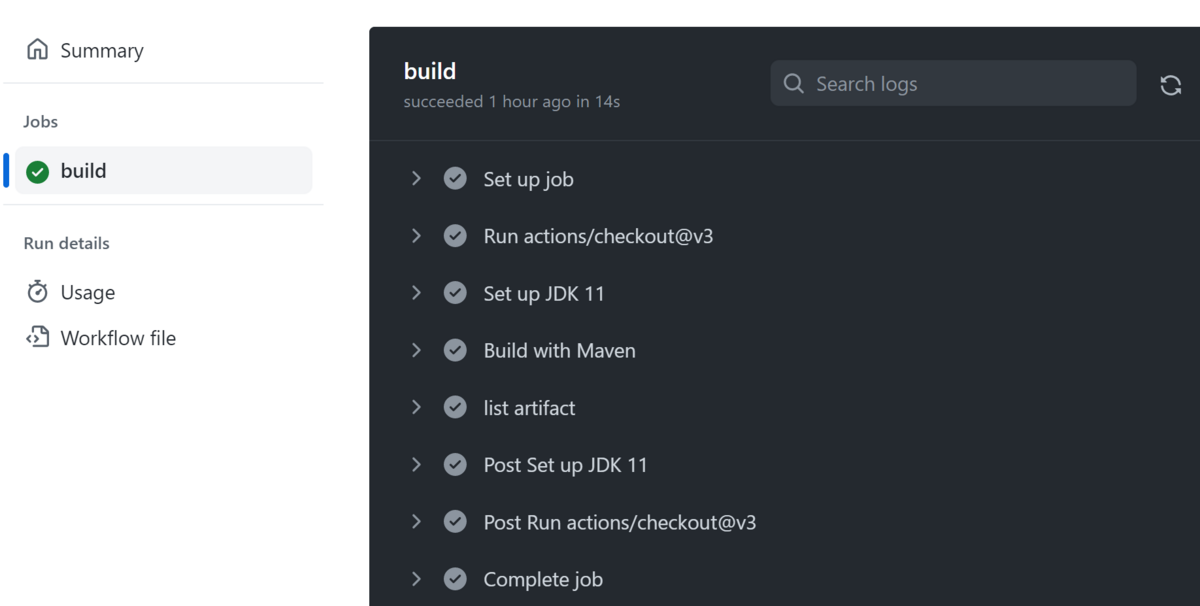
これで準備が整ったので、commit した後、GitHubのリポジトリに push します。
下図のようにビルドが成功しました!
また、アプリケーションの JAR ファイルも Maven により生成されていることも確認できました。
Java の Distribution を Amazon Corretto に変更してみる
スターターワークフローを活用することで、短時間で Java をビルドするワークフローを構築できました。
このワークフローの内容をみてみると、28 行目から 23 行目に下記の記述があります。
- name: Set up JDK 11 uses: actions/setup-java@v3 with: java-version: '11' distribution: 'temurin' cache: maven
ステップの名前から、ビルド用の JDK をセットアップしていることはわかります。
また、JDK のディストリビューションに temurin を指定していることもわかりますね。
このディストリビューションを Amazon Corretto に変更できないだろうか? と思い、調べてみました。
結果、下記の情報をみて可能であることがわかりました!
この情報を参照し、distribution: の指定を corretto に変更して再度ワークフローを実行します。
- name: Set up JDK 11 uses: actions/setup-java@v3 with: java-version: '11' distribution: 'corretto' cache: maven
特に問題なくビルドが完了しました!

なお、今回使用した Java アプリケーションのソースや、Maven の pom.xml 、ワークフローの YAML ファイルは下記になります。
今回の所感
これまで自分が経験したことがないものを一から作るときは、お手本 があると助かりますよね。
スターターワークフローは、まさにその お手本 として利用することができました。
これで、GitHub Actions のワークフローでアプリケーションのビルドを行うための基本的な方法は理解できました。
次回は、AWS の環境へのデプロイを念頭に、どのように AWS アカウントに接続、連携できるのかを調べて記事にしたいと思います!
今さらながら GitHub Actions をさわってみる: (入門編)
これまで GitHub はリポジトリとしてのみ活用することがほとんどでしたが、GitHub Actions のワークフローを触ってみようと思い至りました。
なぜそう思ったかというと、Amazon CodeCatalyst を触ってみたからです。
Amazon CodeCatalyst を触っていくうちに、「これはどうも GitHub の全体的な機能と似ているんじゃないかな」と個人的な感触を得ました。
Amazon CodeCatalyst のさらなる理解を深めるためには、GitHub の様々な機能を理解しておくのがよいのでは、と思ったわけです。
Amazon CodeCatalyst だけを Dive Deep するのではなく、また、GutHub だけを Dive Deep するのではなく、これら 2 つのサービスを理解し、比較していくことでさらなる理解や知見を深めることができそうだと感じています。
ということで、ひとまず GitHub Actions でワークフローを使って CI/CD 関連の機能を試していきたいと思います。
個人的には CI/CD の環境は、これまでほとんど AWS CodeBuild や AWS CodePipeline を使ってきたのですが、GitHub Actions のワークフローではどんなことができるか、AWS のクラウドのリソースと連携できるのか、などを実際に触って確認してみるつもりです。
今回は、全然知識がない中からのスタートなので、入門編 として簡単なワークフローを動かすところまでやって、その時に気づいたこと、思ったことを書いていきたいと思います!
(なお、この記事の内容は 2023 年 2 月時点で触ってみた結果に基づいています。)
クイックスタートを触ってみる
GitHub Actions を入門する上では、まず下記を試してみるのが良さそうです。
このクイックスタートは、「細かいことはさておき、ひとまず動かしてみよう!」という位置づけのようです。
ふむふむ、GutHub のリポジトリで .github/workflows フォルダをつくって、そこに YAML ファイルを作成すればよさそうです。
ただ、このクイックスタートの 手順は、Web ブラウザで GitHub のページからファイルを編集しているようですが、今回は手元の PC のローカルのリポジトリを編集して、リモートに反映させる形で試していきます。
まずは適当な名前で GitHub のリポジトリを作成して、git clone を実行します。
git clone https://github.com/tetsuo-nobe/test.git
そして .github/workflows フォルダ を作成し、クイックスタートに記載されている通りに github-actions-demo.yml というファイルを作成します。ファイル名は任意ですが、今回はクイックスタート通りにしておきました。
内容は下記です。
name: GitHub Actions Demo run-name: ${{ github.actor }} is testing out GitHub Actions 🚀 on: [push] jobs: Explore-GitHub-Actions: runs-on: ubuntu-latest steps: - run: echo "🎉 The job was automatically triggered by a ${{ github.event_name }} event." - run: echo "🐧 This job is now running on a ${{ runner.os }} server hosted by GitHub!" - run: echo "🔎 The name of your branch is ${{ github.ref }} and your repository is ${{ github.repository }}." - name: Check out repository code uses: actions/checkout@v3 - run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner." - run: echo "🖥️ The workflow is now ready to test your code on the runner." - name: List files in the repository run: | ls ${{ github.workspace }} - run: echo "🍏 This job's status is ${{ job.status }}."
上記がワークフローの内容を示すものですね。ざっとみると、どんなことが記述されているかが何となくわかります。
例えば、name や run-name は名前に関する定義だな、とか、時々出てくる ${{ }} は事前定義済の変数の内容を出力するのだろうな、とか...
さらに、steps: 以下に記載されている内容がワークフローとして実行すべき処理なのだろうな、とか...
run: は OS に対するコマンドっぽいけど、use: actions/checkout@v3 は何か違うようだ... でも、その下の echo コマンドをみると、どうもリポジトリから clone するためのもののようだ... などとボンヤリわかります。
ともあれ、クイックスタートでは、ひとまず動かしてみる ことが目的なので、このファイルを保存してリモートに push します。
実際のクイックスタートから少し手順を変えてますが、ブランチに push することにより ワークフローが実行されるはずです。
git add . git commit -m "1st commit" git push
Webブラウザから GitHub のリポジトリのページで Actions タブを選択します。
ページ左側に GitHub Actions Demo と表示されています。 YAML ファイルの冒頭にある name: で指定した名前ですね!
これが ワークフローの名前のようです。
それをクリックすると、右側にこのワークフローが実行された履歴の一覧が表示されます。
履歴の一覧の中で xxxx is testing out GitHub Actions 🚀 のリンクをクリックします。(xxxx は環境に応じて読み替えて下さい。)
緑色のチェックマークのアイコンが表示されているので、ワークフローが成功したようです。ちなみに失敗すると 赤色の × アイコンが表示されます。
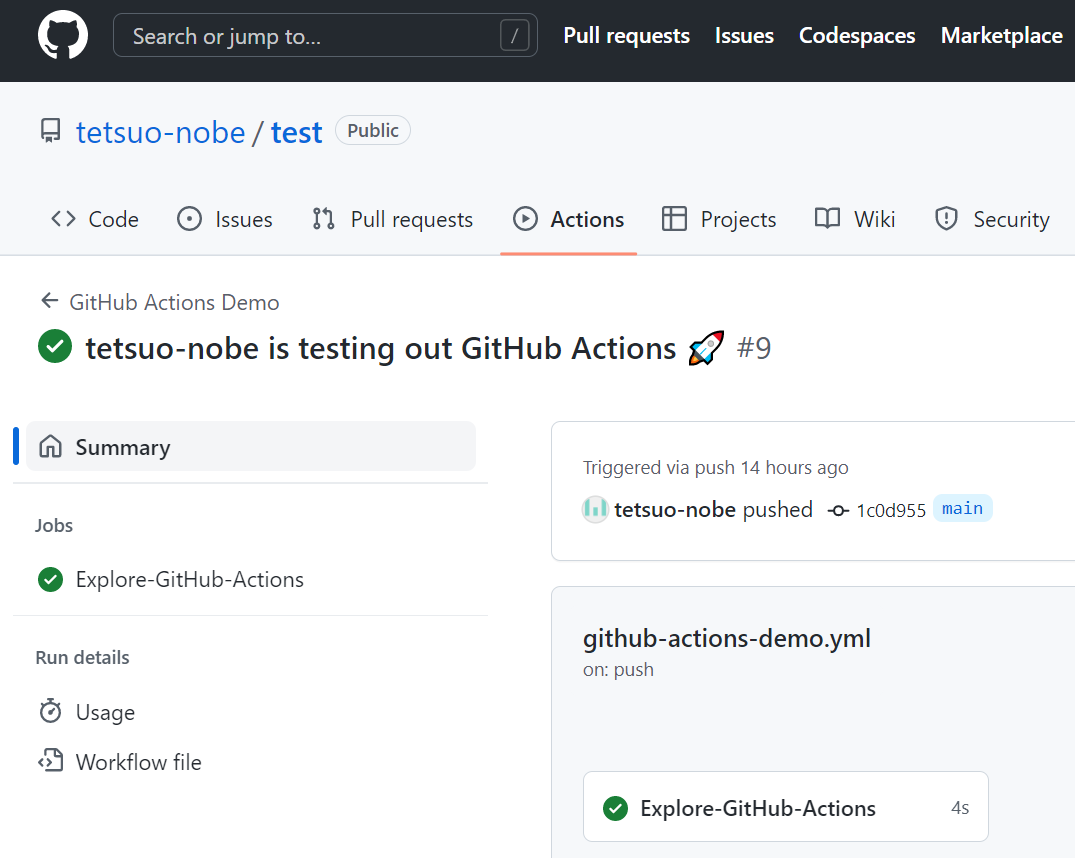
ワークフローのページが表示されるので、その中の Explore-GitHub-Actions をクリックします。
これは、ワークフローの YAML の中の jobs: で指定したジョブ名のようですね。
クリックすると、ワークフローのログが参照できます。
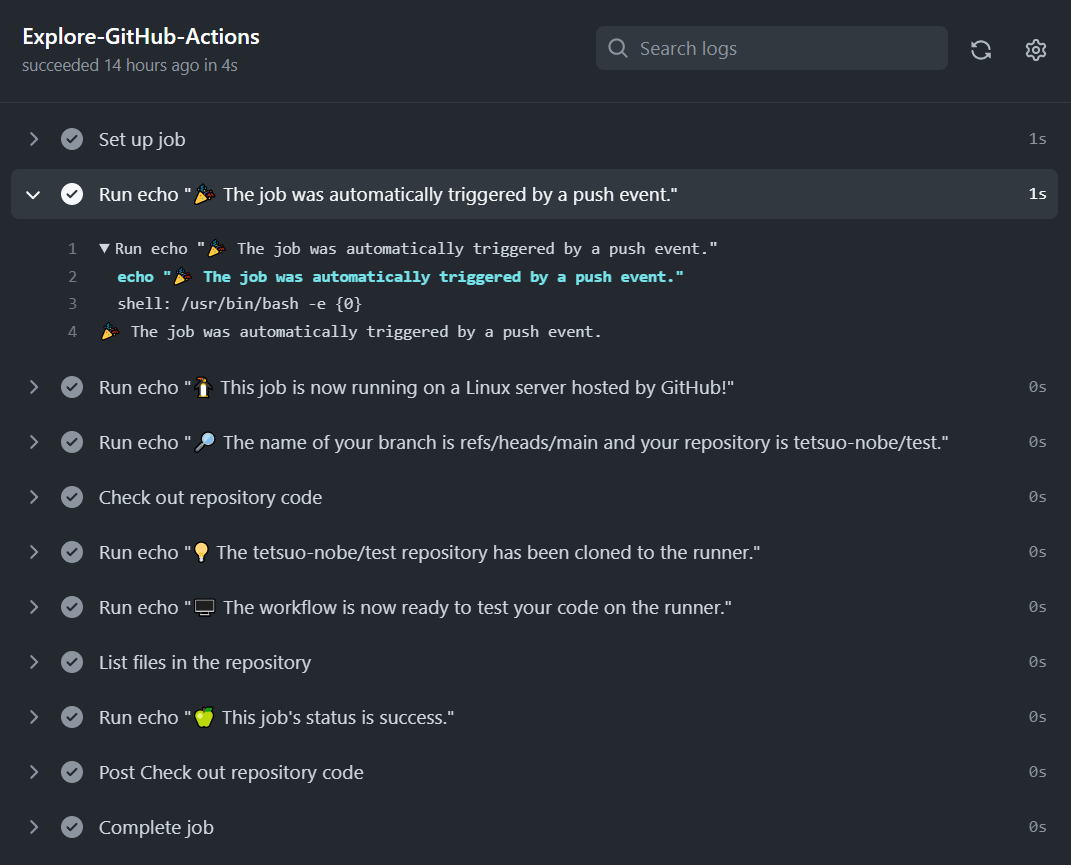
ログを見ると、ワークフローの YAML ファイルの中で steps: として定義した処理が実行されている様子がわかりますね。
ほとんど echo コマンドを実行する内容でしたが、無事にクイックスタートのワークフローは動かせたようです!
ワークフローの基本を理解する。
さて、クイックスタートでは「細かいことはさておき、とりあえず動かしてみよう」という位置づけでワークフローを実行してみましたが、もう少し体系的にワークフローの基本を理解していきたいですよね。
そこで、下記のページを読んで、さらにサンプルのワークフローを動かしてみました。
このページでは、クイックスタートと異なり、サンプルのワークフローを取り上げつつ、基本概念やワークフローの YAML の各構成要素を解説してくれています。
例えば「ワークフロー」、「ジョブ」、「ステップ」、「ランナー」という基本概念も、このページで説明されています。
また、クイックスタートで出てきた uses: actions/checkout@v3 が何だったのかがわかりますね。
actions/checkout は 複雑で頻繁に繰り返されるタスクを実行するための「アクション」であり、@v3 はバージョンの指定、use: はそのアクションをジョブのステップとして実行するキーワードであることがわかりました。
ここで、ふと疑問がわきました。クイックスタートの YAMLファイルを .github/workflows フォルダ に置いたまま、上記ページのサンプルのワークフローの YAML ファイルを追加してもいいのかな?という疑問です。
早速試してみましたが、2つの ワークフローが push をトリガーに正常に動作することを確認できました。
今回は 2つのワークフローは push をトリガーのイベントとしていますが、ワークフローの YAML の中の on: で イベントを変更することもできるようですね。
今回の所感
クイックスタートや、サンプルのワークフローを簡単に、問題なく実行できたのは嬉しいですね。
ワークフローの YAML の書き方を一度に全部覚えるのは無理があるので、色々試しながら、調べながら記憶に定着させていきます。
まだ基本中の基本の「小さな成功」でしかありませんが、この小さいな成功を積み上げていきたいです。
次回は、シンプルなアプリケーションのビルドを行うワークフローを試して記事にするつもりです!