今さらながら GitHub Actions をさわってみる: (AWS SAM のデプロイ編)
前回の記事では、GitHub Actions のワークフローから AWS アカウントへのアクセス方法を確認しました。
その方法を用いて、今回は AWS アカウントへサーバーレスアプリケーションのビルドとデプロイを行ってみます。
アプリケーションは、Amazon API Gateway と AWS Lambda を使用して HelloWorld メッセージを返すだけのシンプルなものです。
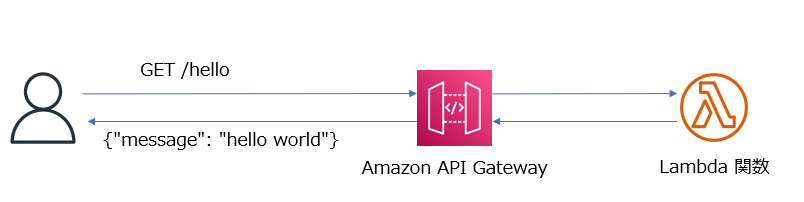
このようなシンプルなものであれば、AWS SAM ( Serverless Application Model ) の事前定義済のアプリケーションテンプレートを用いるとすぐに作成することができます。
この AWS SAM を使用してデプロイを行うワークフローを作成し、実際にデプロイするまでの手順を記載していきます。
なお、この記事の内容は 2023 年 3月時点で検証した内容に基づいています。また記事の中の AWS アカウント IDはすべて 0 で表記しています。
手順の概要
- GitHub でリポジトリを作成する
- デプロイ先の AWS アカウントの IAM で ID プロバイダの設定と IAM ロールの作成を行う
- GitHub でリポジトリで IAM ロールの ARN の値を Secret として保存する
- AWS SAM のリソースを作成する
- GitHub Actions のワークフローの YAML ファイルを作成する
- リポジトリに push してワークフローの実行結果を確認する
1. GitHub でリポジトリを作成する
任意の名前でリポジトリを作成します。
この名前は、次の IAM ロール作成時に必要になります。
2. デプロイ先の AWS アカウントの IAM で ID プロバイダの設定と IAM ロールの作成を行う
ID プロバイダの設定については前回の記事(下記)で説明している手順通りです。一回、設定していれば改めて設定する必要はありません。
IAM ロールの作成では、今回は ワークフローから AWS SAM CLI のコマンドを実行してデプロイを行いますので、そのために必要なポリシーを設定した IAM ロールを作成します。
これも前回の記事の内容を参考に行えます。
ただし、許可ポリシーは下記のように AWS SAM によるデプロイを許可する内容にします。
許可ポリシーの例は、以前に紹介した記事(下記)にありますので、これを利用します。
また、信頼ポリシーは使用するリポジトリに合わせて下記のように設定します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::000000000000:oidc-provider/token.actions.githubusercontent.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "token.actions.githubusercontent.com:aud": "sts.amazonaws.com" }, "StringLike": { "token.actions.githubusercontent.com:sub": "repo:<GitHubユーザーID>/<GitHubリポジトリ名>:*" } } } ] }
IAM ロールを作成したら、ARN の値をメモしておきます。これは次の手順で使用します。
3. GitHub でリポジトリで IAM ロールの ARN の値を Secret として保存する
前の手順でメモしておいた IAM ロールの値を、GitHub リポジトリの Secretとして保存します。
この手順も前回の記事を参考に行えます。
4. AWS SAM のリソースを作成する
AWS SAM CLI をインストールしている環境で、初期化を行います。
利用する AWS SAM CLI のバージョンは、 1.76.0 以降を前提としています。
sam --version SAM CLI, version 1.76.0
今回は、Python 3.8 をラインタイムとして指定します。X-Ray トレースや Amazon CloudWatch Application Insights のモニタリング を無効化する前提です。
--name は、任意の名前を設定します。
sam init --runtime python3.8 \ --app-template hello-world \ --name actions-aws-sam \ --no-tracing \ --no-application-insights
--name で指定したフォルダが作成されるので、そこに移動し、git init と git remote add を実行します。
cd actions-aws-sam git init git remote add origin https://github.com/<GitHubユーザーID>/<GitHubリポジトリ名.git
この段階で、AWS SAM CLI により HelloWorld メッセージを出力する Python の AWS Lambda 関数と、それと統合した Amazon API Gateway の API のリソースは揃っています。
ただ 今回は、GitHub Actions のワークフローからデプロイする際に必要な AWS SAM の細かいパラメータは、ファイルに保存しておくようにしたいと思います。
そのため、--name で指定したフォルダ に、samconfig.toml というファイルを作成し、下記の内容を指定して保存します。
version=0.1 [default.deploy.parameters] stack_name = "<任意のスタック名>" s3_bucket = "<AWS SAM のリソースをアップロードする S3バケット名>" s3_prefix = "<上記 S3 バケットのフォルダ名>" confirm_changeset = false capabilities = "CAPABILITY_IAM"
s3_bucket で指定するバケットはあらかじめ作成しておきましょう。s3_prefix で指定した名前は S3 バケットのフォルダになり、任意の名前を設定できますがあらかじめフォルダを作成しておく必要はありません。
これで AWS SAM のリソースの準備は完了です。
5. GitHub Actions のワークフローの YAML ファイルを作成する
では、AWS SAM リソースをデプロイするワークフローの YAML を 作成します。
--name で指定したフォルダ の下に .github/workflows フォルダ作成して、そこに 任意の名前の YAML ファイルを作成します。
内容については、下記のドキュメントにサンプルがあるので、これを活用します。
ただし、このサンプルでは OIDC を使用せず Secret に AWS アカウントの認証情報を指定していますので、この部分は OIDC を使うように変更します。
また、--no-confirm-changeset オプションは すでに samconfig.toml 内で指定しているので、このオプションの指定も削除します。
on: push: branches: - main env: AWS_REGION : "ap-northeast-1" # permission can be added at job level or workflow level permissions: id-token: write # This is required for requesting the JWT contents: read # This is required for actions/checkout jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - uses: actions/setup-python@v3 - uses: aws-actions/setup-sam@v2 - uses: aws-actions/configure-aws-credentials@v1 with: role-to-assume: ${{ secrets.AWS_ROLE_ARN }} role-session-name: samplerolesession aws-region: ${{ env.AWS_REGION }} - run: sam build --use-container - run: sam deploy --no-fail-on-empty-changeset
ポイントは 17 行目の - uses: aws-actions/setup-sam@v2 ですね。 AWS SAM を使用するためのアクションがあるので、それを使用することで ワークフローから AWS SAM CLI を実行できます。
これでワークフローの準備も完了しました。
6. リポジトリに push してワークフローの実行結果を確認する
では、いよいよ リポジトリに push してワークフローを実行します。
git add. git commit -m "commit sam resource" git push -u origin main
無事に ワークフローが完了していれば、下図の赤枠の Run sam deploy のステップを展開表示してみましょう
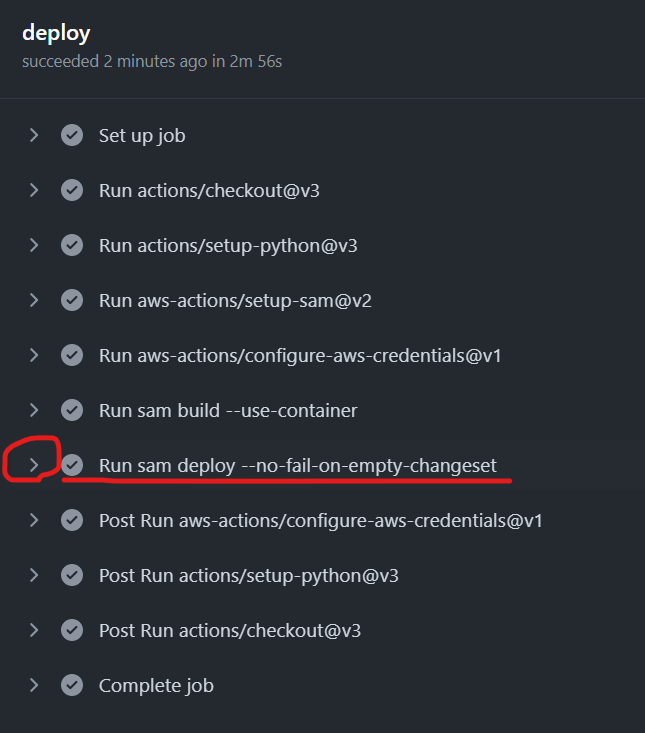
AWS SAM による deploy の結果として、Outputs セクションが表示されています。
CloudFormation outputs from deployed stack ---------------------------------------------------------------------------------- Outputs ---------------------------------------------------------------------------------- Key HelloWorldFunctionIamRole Description Implicit IAM Role created for Hello World function Value arn:aws:iam::***:role/actions-aws-sam-stack- HelloWorldFunctionRole-WCPOUUNE5S2W Key HelloWorldApi Description API Gateway endpoint URL for Prod stage for Hello World function Value https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/
その中の Key が HelloWorldApi の Value のURL の値をコピーして Web ブラウザでアクセスします。
結果、下記のようなメッセージが表示されればアプリケーションが正常にデプロイされています。
{"message": "hello world"}
今回の所感
今回で GitHub Actions のワークフローを使用し、AWS SAM によるアプリケーションのデプロイができました。
知識ゼロのところから、下記の記事を書き連ね、コツコツと学んで積み上げてきた知識を組み合わせて実現できたと感じています。
今回は GitHub Actions 側の視点から AWS SAM を使用する方法を確認しましたが、AWS SAM には、実は GitHub Actions のワークフローを自動生成する機能があります。
これも一応触ってみたので、また別の機会に記事で紹介したいと思います。


今さらながら GitHub Actions をさわってみる: (AWS へのアクセス編)
前回、前々回に引き続き、GitHub Actions のワークフローを触っていきます。
今回は、ワークフローから AWS アカウントへアクセスする方法を整理しつつ、実際にアクセスを試していきます。
最終的には、GitHub Actions を使用して アプリケーションをビルドし、AWS アカウントにデプロイするワークフローを作成しようと思っているので、AWS アカウントへのアクセス方法の理解はその事前準備となります。
なお、この記事は 2023 年 3 月時点で検証した内容に基づいて記載しています。
目次
- AWS アカウントへアクセスする方法の整理
- 方法 1. AWS のアクセスキー ID やシークレットアクセスキー を GitHub の Secret として保存してワークフローから使用する方法
- 方法 2. GitHub の OpenID Connect (OIDC) プロバイダを使用し、AWS アカウントにアクセスできるトークンを使用する方法
- 今回の所感
AWS アカウントへアクセスする方法の整理
まず、GitHub のドキュメントを参照して AWS アカウントへのアクセス方法を整理してみましたが、基本的には下記の 2パターンがあるようです。
- AWS のアクセスキー ID やシークレットアクセスキー を GitHub の Secret として保存してワークフローから使用する方法
- GitHub の OpenID Connect (OIDC) プロバイダを使用し、AWS アカウントにアクセスできるトークンを使用する方法
セキュリティの観点から上記 2 の方法が推奨 のようですが、とりあえず両方の方法を試します。
方法 1. AWS のアクセスキー ID やシークレットアクセスキー を GitHub の Secret として保存してワークフローから使用する方法
GitHub の Secret については、次のドキュメントに記載があります。AWS アカウントのアクセスキーなど、秘匿すべき認証情報を保存する用途に使えそうです。
この Secret を使ったワークフローのイメージ図を描いてみました。
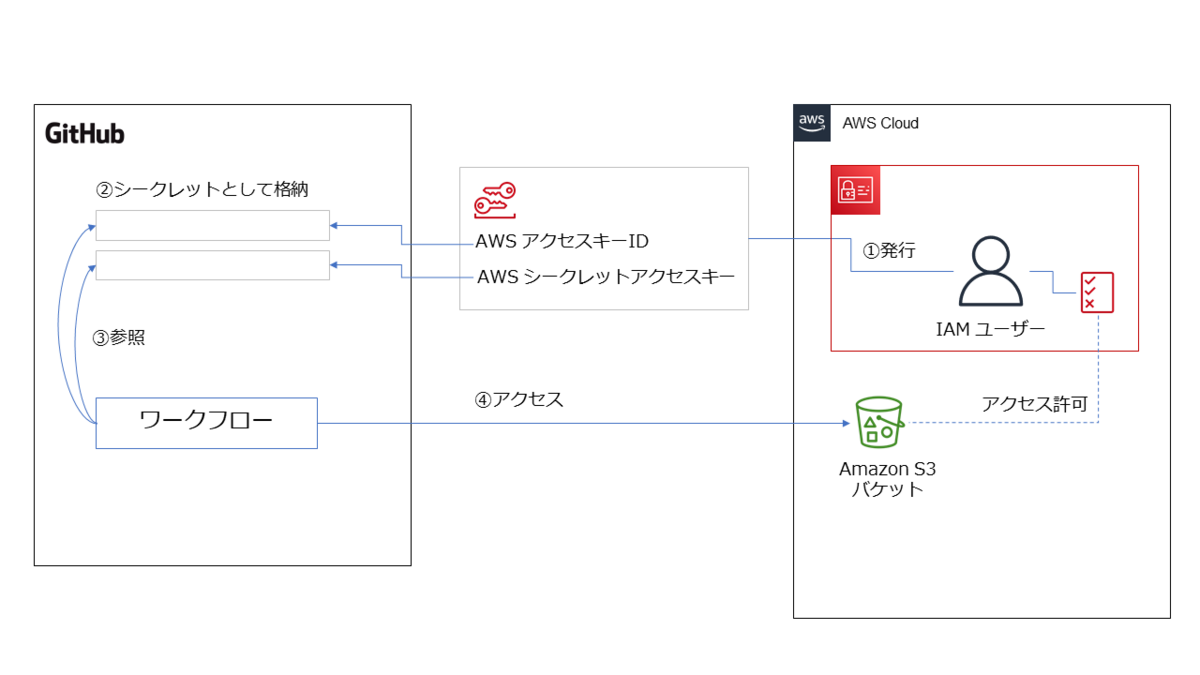
上図のように、仕組みとしてはシンプルでわかりやすいですよね。
ただし、前述のようにこの方法はお薦めできません。
Secret という仕組みはあるにせよ、永続的に使用できるアクセスキー ID を発行してそれを一つの場所にずっと保管することはセキュリティ面での懸念があるからです。
後で説明する 2番目の方法のように、必要なタイミングで一時的に使用できるトークンを発行して使用する 方が望ましいのですが、今回は勉強の一環として試してみました。
まず、AWS アカウントで 下記の IAM ポリシーを作成します。(ここでは便宜上、s3-listAllMyBuckets-policy と名付けます。)
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" } ] }
次に IAM ユーザーを作成して作成した s3-listAllMyBuckets-policy を設定し、アクセスキーID とシークレットアクセスキーを発行します。
そのアクセスキーID とシークレットアクセスキーを GitHub の Secret として設定します。
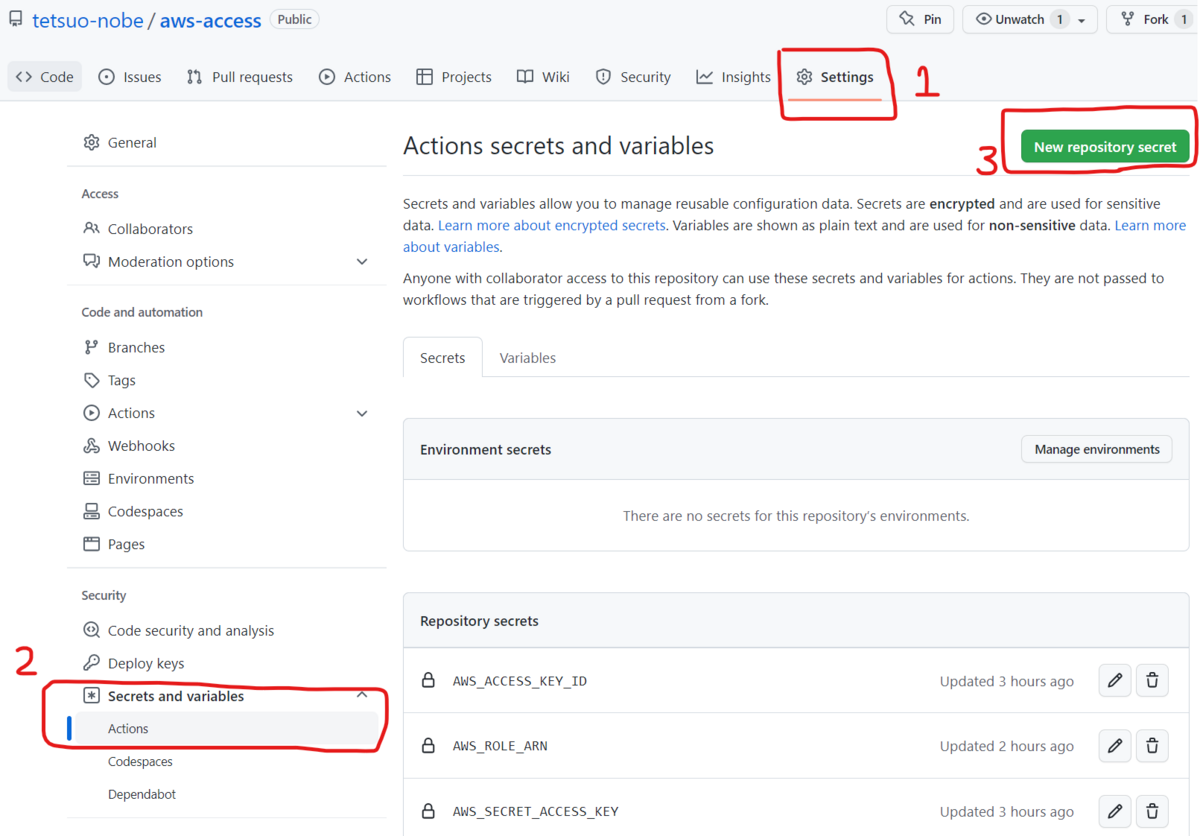
設定方法は、Web ブラウザからでも GitHub CLI からでも可能です。
Web ブラウザの場合は、対象リポジトリのページから [ Settings ] タブ、左側のメニューで [ Secrets and variables ] - [ Actions ] を選択して、右上の [ New repository secret ] を選択して設定します。設定した Secret の名前は後でワークフローの中で指定します。
では次にワークフローの YAML ファイルを作ります。
今回は、下記のドキュメントを参考にしました。
ただし、今回は AWS アカウントへのアクセスを試すのが目的なので、 AWS SAM は使用せず、AWS CLI のコマンドを aws s3 ls を発行するだけのシンプルなワークフロー(下記)に変えることにしました。
aws s3 ls が正常に実行され、Amazon S3 バケットの一覧が表示されれば AWS アカウントへアクセスできたという確認になります。
name: AWS access using secrets in GitHub on: push: branches: - main jobs: list-s3-buckets-using-Secret: runs-on: ubuntu-latest steps: - name: configure aws credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: execute AWS CLI run: aws s3 ls
上記の YAML でポイントになるのは、10 行目から 15 行目のステップです。
aws-actions/configure-aws-credentials というアクションを用いることで、AWS アカウントのアクセスするための認証情報をセットして、AWS CLI も利用できるようになります。
そのため、次の 16 行目からのステップでは、すぐに AWS CLI で aws s3 ls を実行しています。
このワークフローを実行すると、正常に Amazon S3 バケットの一覧が表示されました。
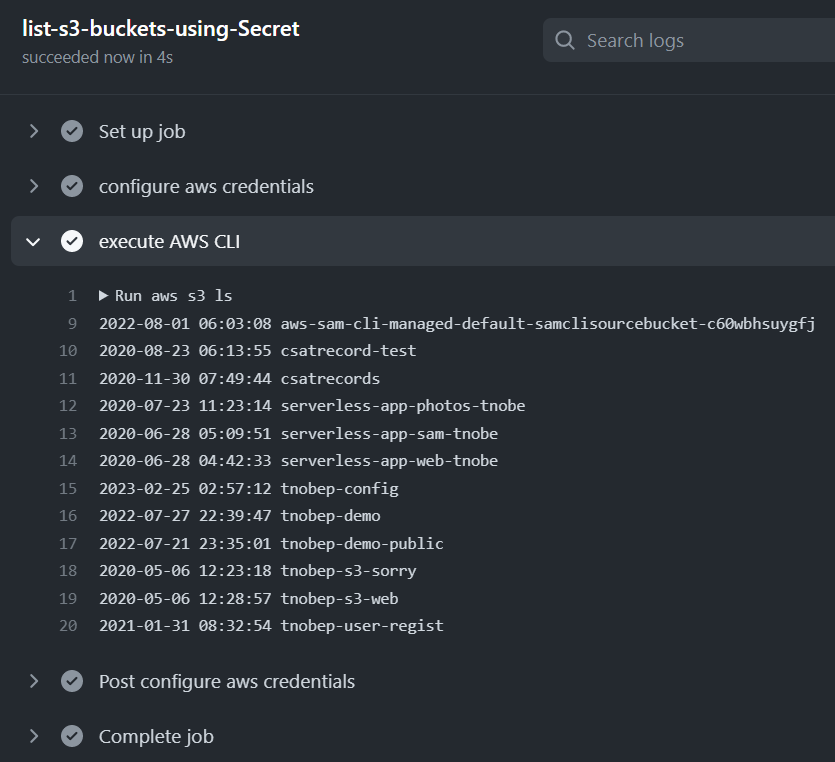
GitHub のワークフローから AWS アカウントへアクセスを確認できたわけです。
方法 2. GitHub の OpenID Connect (OIDC) プロバイダを使用し、AWS アカウントにアクセスできるトークンを使用する方法
ただ、(繰り返しになりますが)前述の方法 1 よりもお薦めなのが この OIDC を使用する方法です。
下図は、この仕組みを図にしてみたものです。
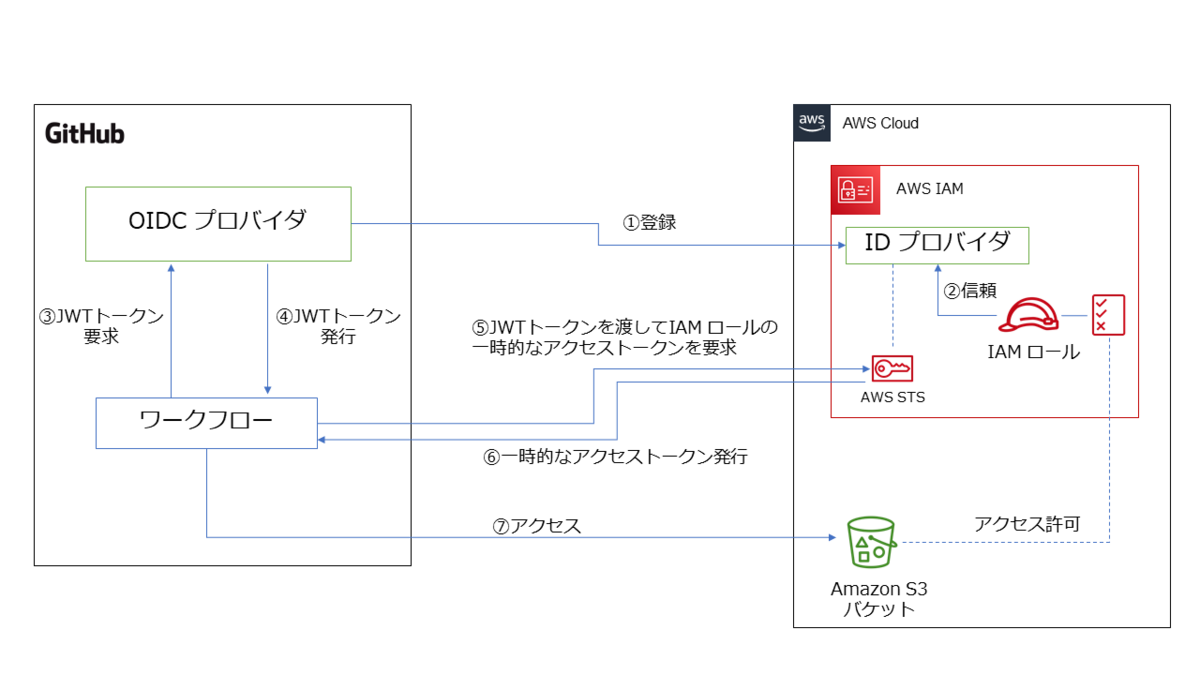
方法 1 よりは複雑に感じるかもしれませんが、要するに AWS アカウントがGitHub の OIDC プロバイダを信頼する ことで、その OIDC プロバイダが発行した JWT (ジョット)トークンがあれば AWS の IAM ロールを使用できるようにする仕組みです。
GitHub の OIDC プロバイダが発行するJWTトークンがあれば、AWS 側からアクセストークンが発行されるので、そのアクセストークンで AWS アカウントにアクセスすれば、事前に設定した IAM ロールに紐づく IAM ポリシーの権限の範囲で AWS リソースを操作できます。
この仕組みを実現するには、まず GitHub の OIDC プロバイダを AWS アカウント側に登録します。
この方法は、GitHub の下記のドキュメントにも記載されています。
この登録ですが、AWS マネジメントコンソールでも AWS CLI でも行えますが、個人的には AWS マネジメントコンソール を使う方が簡単 でお薦めです。
その理由は、OIDC プロバイダ登録時には TLS 証明書のサムプリント ( thumbprint ) の値が必要なのですが、AWS CLI の場合は、事前に様々なコマンドを発行したり編集したりしてそのサムプリントの値を自分で導出したうえでパラメータに指定する必要があるのに対して、AWS マネジメントコンソール ではサムプリントの値は自動的に取得、設定可能なためです。
参考として下記のドキュメントを紹介しますので、興味があれば実施してみて下さい。
ここではシンプルに設定できる AWS マネジメントコンソールを使用する方法を紹介します。
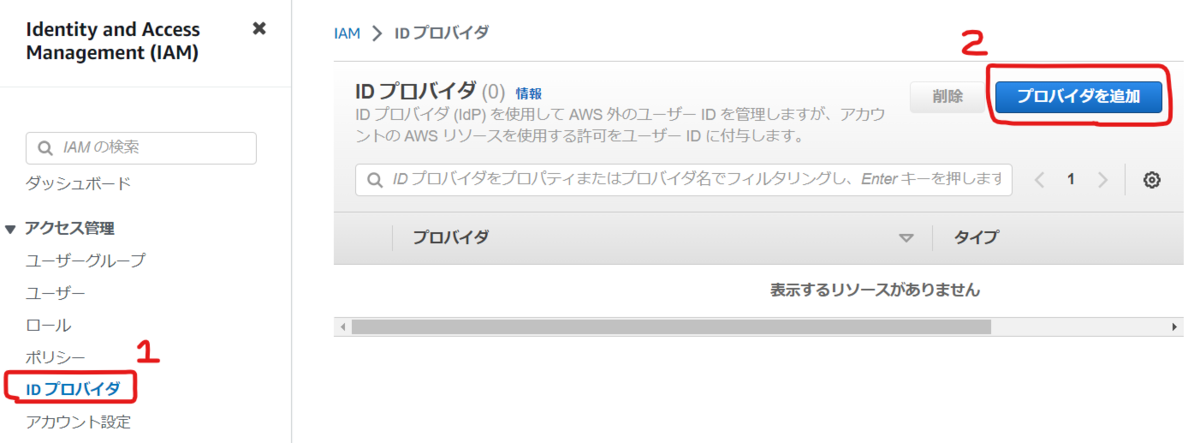
まず IAM のコンソールの左側のメニューから [ アクセス管理 ] - [ ID プロバイダ ] を選択し、右側にある [ プロバイダを追加 ] を選択します。
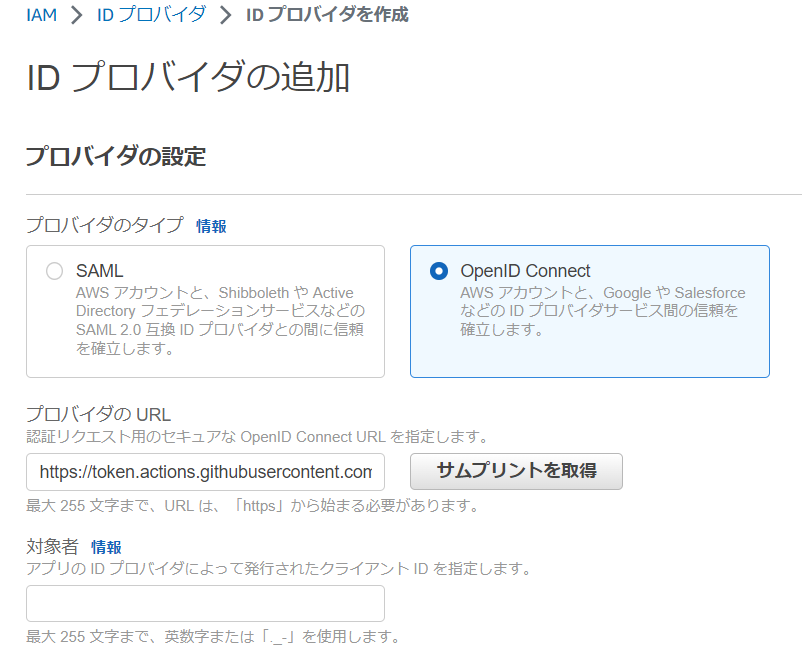
[ プロバイダのタイプ ] に [ OpenID Connect ] を選択します。
[ プロバイダの URL ] に https://token.actions.githubusercontent.com を入力して [ サムプリントを取得 ] を選択します。
その後、その下にある [ 対象者 ] に sts.amazonaws.com と入力して、ページ右下にある [ プロバイダを追加 ] をクリックします。
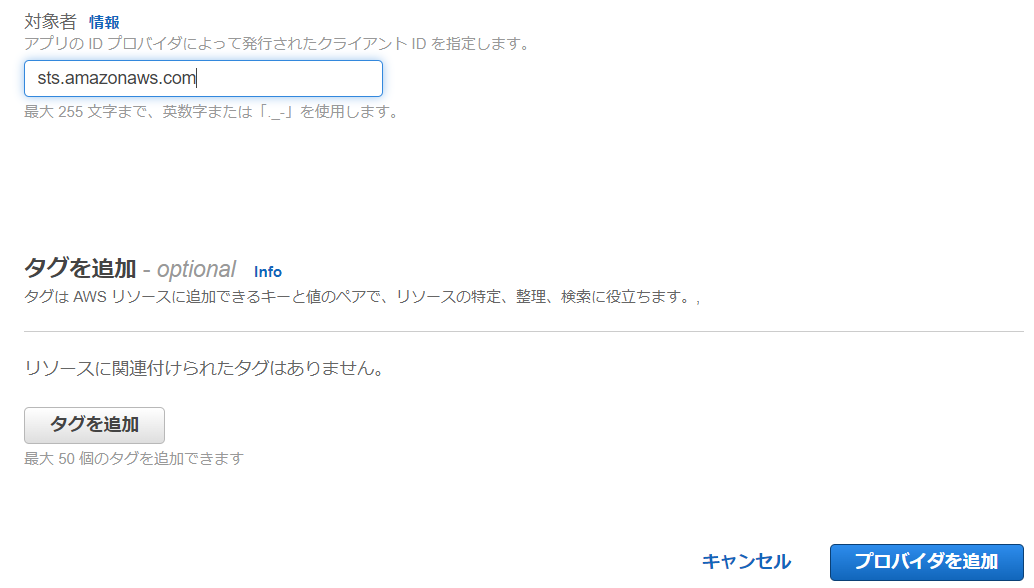
これで OIDC プロバイダの登録は完了です。
次に、この OIDC プロバイダを信頼する IAM ロールを作成します。
AWS マネジメントコンソールで作成する場合は、IAM のページから左側のメニューで[ アクセス管理 ] - [ ロール ] を選択し、右側にある [ ロールを作成 ] を選択します。
[ 信頼されたエンティティを選択 ] のページで [ 信頼されたエンティティタイプ ] に [ ウェブアイデンティティ ] を選択します。
[ アイデンティティプロバイダー ] に [ token.actions.githubusercontent.com ] を選択します。
[ Audience ] に [ sts.amazonaws.com ] を選択して、[ 次へ ] を選択します。

その後は、方法 1 で作成した s3-listAllMyBuckets-policy の IAM ポリシー(下記)を許可ポリシーとして設定します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" } ] }
ロールの名前は任意の値を入力してロールを作成します。今回の例では、s3-listAllMyBuckets-role とします。
これでロールは作成したのですが、ロールの信頼ポリシーで GitHub のリポジトリを限定するように条件を追加しておきましょう。
作成したロールの名前をクリックして、[ 信頼関係 ] タブを選択して、[ 信頼ポリシーを編集 ] を選択します。
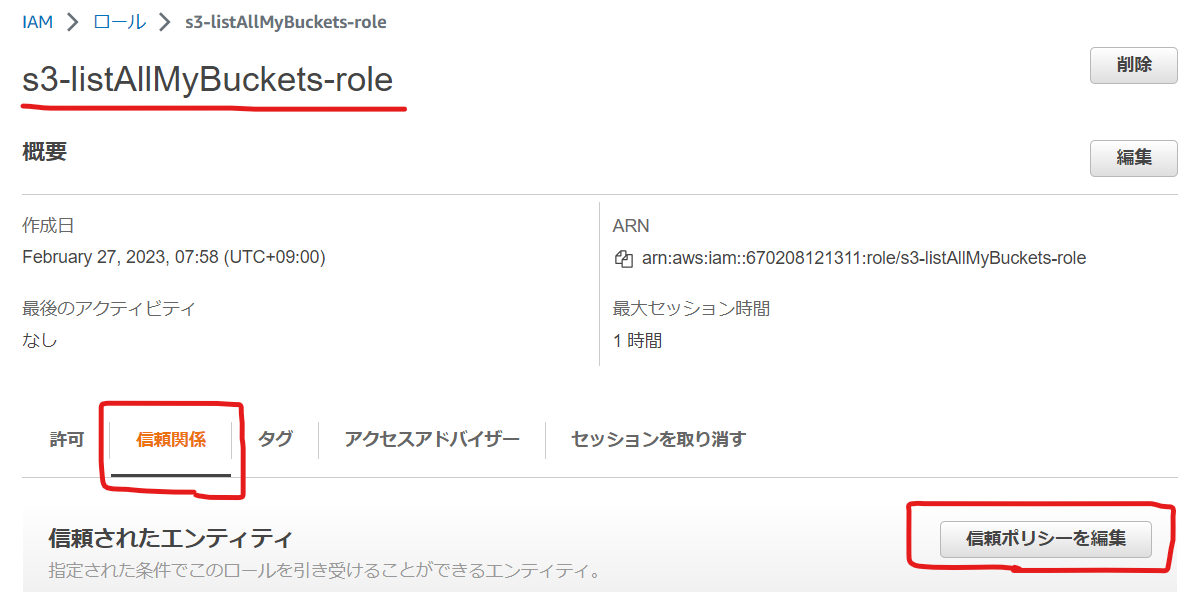
そしてポリシーの Condition に下記を追加します。
これは、GitHub の特定のリポジトリだけを対象に IAM ロールの引き受けを可能にするための条件設定です。
セキュリティの面から IAM ロールを引き受けを認める範囲を限定する必要があるため、必ず設定して下さい。
"StringLike": {
"token.actions.githubusercontent.com:sub": "repo:<GitHubのユーザーID>/<GitHubのリポジトリ名>:*"
}
下記は、条件を追記した信頼ポリシー全体の例です。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::111111111111:oidc-provider/token.actions.githubusercontent.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "token.actions.githubusercontent.com:aud": "sts.amazonaws.com" }, "StringLike": { "token.actions.githubusercontent.com:sub": "repo:tetsuo-nobe/aws-access:*" } } } ] }
これで AWS アカウント側の事前準備は終わったので、GitHub のワークフローを作成していきます。
下記のドキュメントにワークフローの例があるので、これを参考に方法 1 と同じく AWS CLI で aws s3 ls を実行するワークフローを作成します。
ただ、上記のドキュメントの例をみて、おや❓ と感じました。
ワークフローの YAML には、引き受ける IAM ロールの ARN を指定する必要がありますが、この例では、ワークフローが引き受ける IAM ロールの ARN の値を YAML ファイルにそのまま記述しています。
しかし、ARN には AWS アカウント ID の 12桁の数字も含まれるので、YAML ファイルにそのまま記述するのは避けたいですよね。
ということで、IAM ロールの ARN は GitHub の Secret に保存し、それを参照することにしました。
OIDC の方法を用いれば Secret は使わなくてもいいかなと思っていたのですが、やはり AWS アカウントID は秘匿しておきたいですよね。
結果、完成した ワークフローの YAML が下記です。
name: AWS access using OIDC provider on: push: branches: - main env: AWS_REGION : "ap-northeast-1" # permission can be added at job level or workflow level permissions: id-token: write # This is required for requesting the JWT contents: read # This is required for actions/checkout jobs: list-s3-buckets-using-OIDC: runs-on: ubuntu-latest steps: - name: configure aws credentials uses: aws-actions/configure-aws-credentials@v1 with: role-to-assume: ${{ secrets.AWS_ROLE_ARN }} role-session-name: samplerolesession aws-region: ${{ env.AWS_REGION }} - name: execute AWS CLI run: aws s3 ls
19 行目では、Secret を使って IAM ロールの ARN を取得するようにしています。
実行してみると、下図のように aws s3 ls が正常に実行されたことを確認できました。
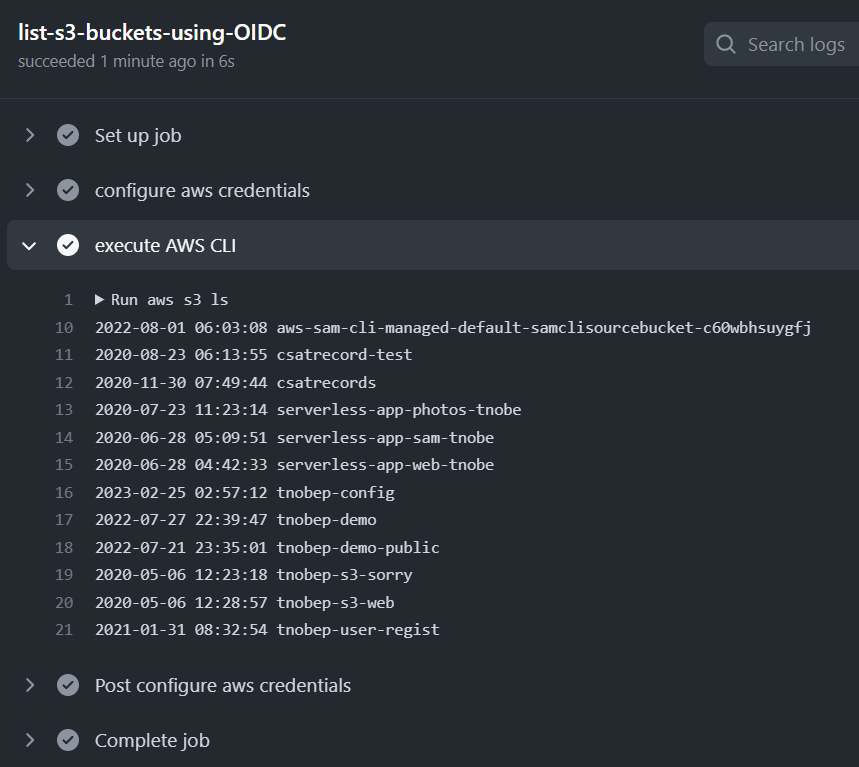
今回の所感
今回の記事の中で紹介した OIDC を使用する方法により、 AWS のアクセスキー ID を発行して GitHub 側に保存しなくても AWS アカウントへアクセスできるが確認できました。
この方法を理解できたことで、GitHub Actions を使用して AWS アカウントへ アプリケーション環境を構築するワークフローの作成方法のイメージが大きく膨らんできました!
次回は、今回の記事の内容をベースにしつつ、AWS アカウントへアプリケーション環境を構築するワークフローを作成したいと思います!
今さらながら GitHub Actions をさわってみる: (Javaのビルド編)
さて前回から GitHub Actions のワークフローいろいろと触っているのですが、今回はその続きとしてシンプルな Java の Webアプリケーションをビルドするワークフローを作成してみます。
とはいえ、GitHub Actions の初心者としては、ワークフローの YAML をどう記述すればいいのか、わかりません。
しかし、下記のドキュメントの内容が参考になりました。
GitHub Actions には スターターワークフロー という事前定義済のワークフローがいくつか用意されており、その中に Maven で Java アプリケーションをビルドするものもあるようです。(他にも、ビルドに Gradle や Ant を使うものもあるようです。)
これを使えば、一から ワークフローの YAML ファイルを自分で作成する必要がないので、初心者としては助かります。
すでに手元で、Maven でビルドする Java の Webアプリケーションのソースが一式あるので、今回はこの Maven でビルドを行うスターターワークフローを使っていきます。
なお、この記事の内容は 2023年 2月時点で確認した内容に基づきます。
スターターワークフローの選択
GitHub のリポジトリのページで Actions タブを選択したとき、まだワークフローを 1つも作成していなければ自動的にスターターワークフローを選択できるページが表示されます。
1 つでもワークフローを作成すると、下図の赤枠にある [New workflow] をクリックすることで、スターターワークフローを選択できるページが表示されます。
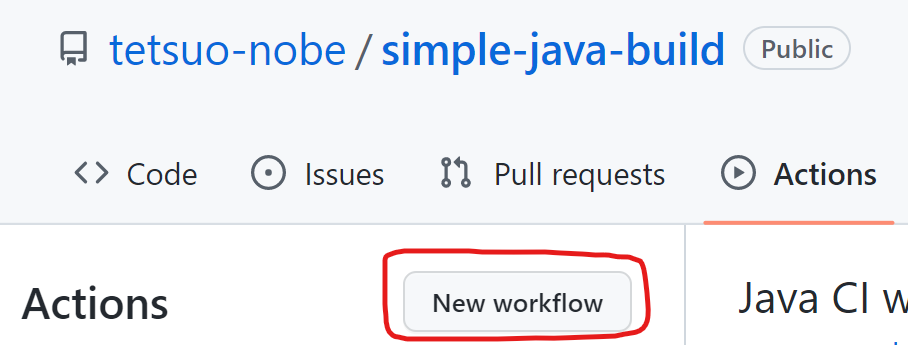
下図は、[New workflow] をクリックした後のイメージです。
赤枠のパネルに、Java with Maven とありますね。
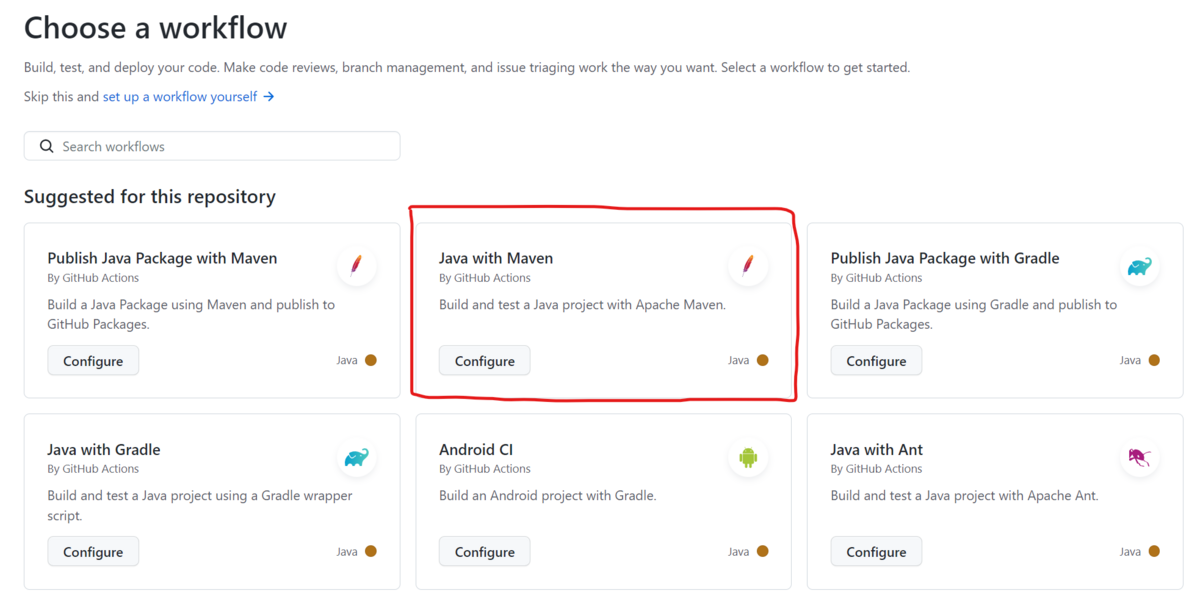
このパネル内の Configure をクリックすると、リポジトリに直接ワークフローの YAML を追加するためのページに遷移します。
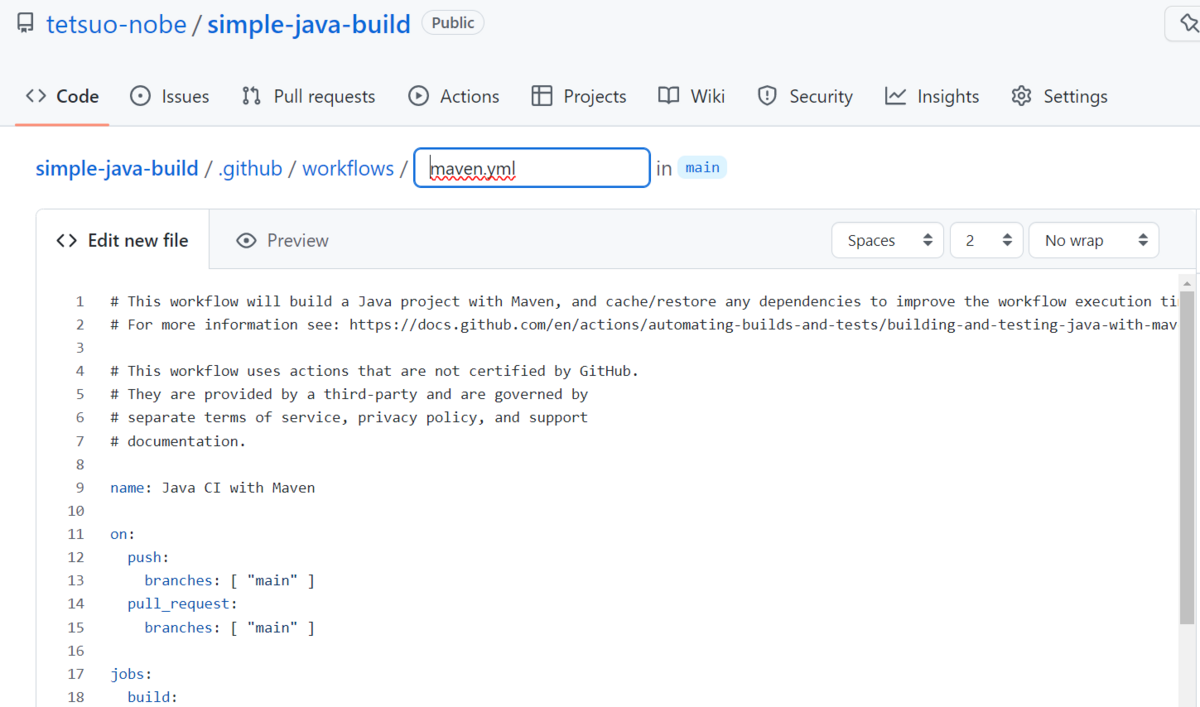
ただ、今回は 手元の PC でローカルのリポジトリで編集して リモートに push するという流れにしていますので、このページでは YAML だけコピーして [Cancel Changes] ボタンを選択します。
スターターワークフローの YAML を少し編集する
リポジトリに ビルド対象の Spring Boot の Java アプリケーションのソースや、Maven でビルドするための pom.xml などを一式用意します。
そして、.github/workflows フォルダにワークフローの YAML ファイルを作成します。
この YAML ファイルに、Java with Maven のスターターワークフローの内容をコピーしました。
ざっと内容をみると、ビルド用の JDK を用意して、Maven のコマンドでビルドしていることがわかりますね。
ただし、29行目以降はコメントアウトしました。
# This workflow will build a Java project with Maven, and cache/restore any dependencies to improve the workflow execution time # For more information see: https://docs.github.com/en/actions/automating-builds-and-tests/building-and-testing-java-with-maven # This workflow uses actions that are not certified by GitHub. # They are provided by a third-party and are governed by # separate terms of service, privacy policy, and support # documentation. name: Java CI with Maven on: push: branches: [ "main" ] pull_request: branches: [ "main" ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - name: Set up JDK 11 uses: actions/setup-java@v3 with: java-version: '11' distribution: 'temurin' cache: maven - name: Build with Maven run: mvn -B package --file pom.xml - name: list artifact run: ls -laR target # Optional: Uploads the full dependency graph to GitHub to improve the quality of Dependabot alerts this repository can receive # - name: Update dependency graph # uses: advanced-security/maven-dependency-submission-action@571e99aab1055c2e71a1e2309b9691de18d6b7d6
29行目以降はコメントアウトした理由は、今回は不要だから です。
29行目以降で実施しているのは、Dependency graph を作成するための処理です。この処理を正常に実行するためには、リポジトリの権限設定を変更しなければならないことがわかりました。
今回の目的はあくまで シンプルな Java のアプリケーションのビルドを行うワークフローを動かすことですので、Dependency graph は不要と判断しコメントアウトにしました。
なお、Dependency graph については下記に説明がありますので、参考にしてください。
また、一番最後に下記のステップを追加しました。
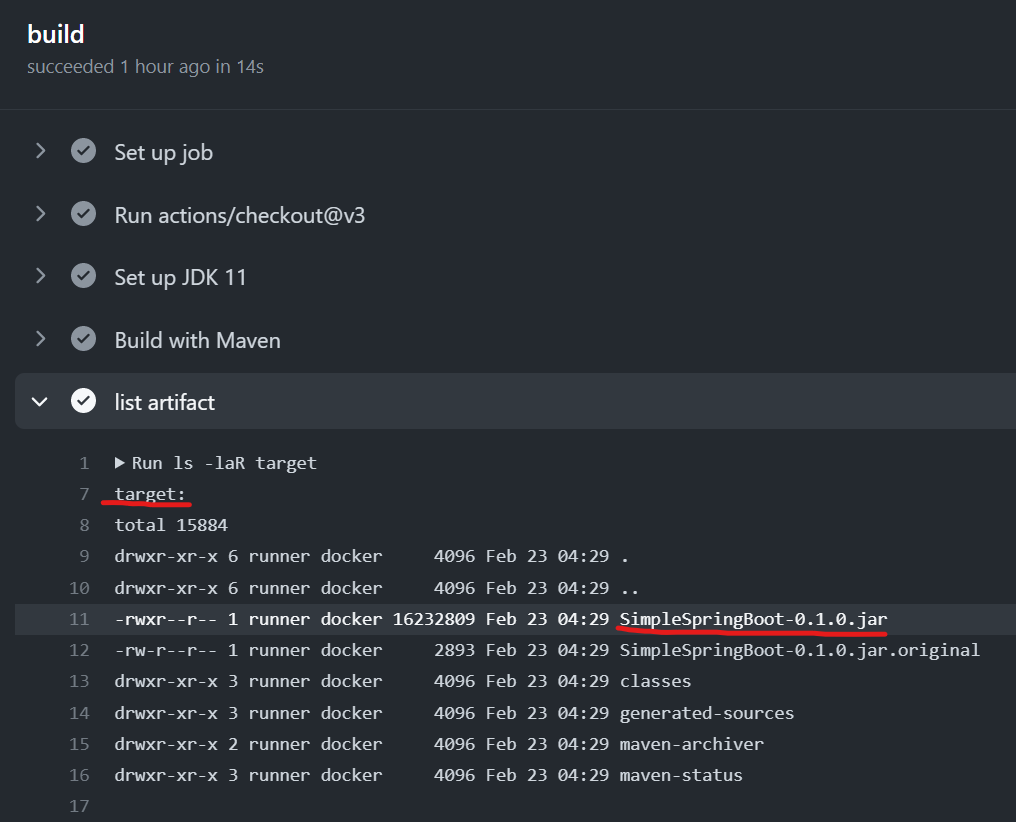
- name: list artifact run: ls -laR target
これは、Maven でビルドした後の生成物として、SpringBoot の Java のアプリケーションの JAR ファイルが生成されているかを確認するために追加したステップです。
これで準備が整ったので、commit した後、GitHubのリポジトリに push します。
下図のようにビルドが成功しました!
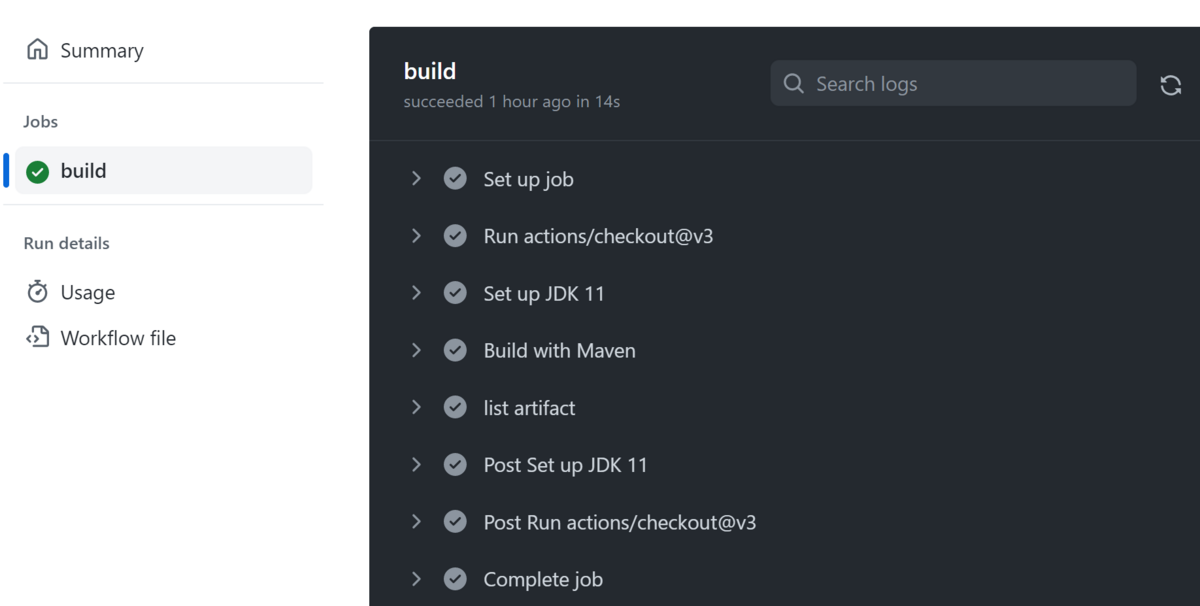
また、アプリケーションの JAR ファイルも Maven により生成されていることも確認できました。
Java の Distribution を Amazon Corretto に変更してみる
スターターワークフローを活用することで、短時間で Java をビルドするワークフローを構築できました。
このワークフローの内容をみてみると、28 行目から 23 行目に下記の記述があります。
- name: Set up JDK 11 uses: actions/setup-java@v3 with: java-version: '11' distribution: 'temurin' cache: maven
ステップの名前から、ビルド用の JDK をセットアップしていることはわかります。
また、JDK のディストリビューションに temurin を指定していることもわかりますね。
このディストリビューションを Amazon Corretto に変更できないだろうか? と思い、調べてみました。
結果、下記の情報をみて可能であることがわかりました!
この情報を参照し、distribution: の指定を corretto に変更して再度ワークフローを実行します。
- name: Set up JDK 11 uses: actions/setup-java@v3 with: java-version: '11' distribution: 'corretto' cache: maven
特に問題なくビルドが完了しました!

なお、今回使用した Java アプリケーションのソースや、Maven の pom.xml 、ワークフローの YAML ファイルは下記になります。
今回の所感
これまで自分が経験したことがないものを一から作るときは、お手本 があると助かりますよね。
スターターワークフローは、まさにその お手本 として利用することができました。
これで、GitHub Actions のワークフローでアプリケーションのビルドを行うための基本的な方法は理解できました。
次回は、AWS の環境へのデプロイを念頭に、どのように AWS アカウントに接続、連携できるのかを調べて記事にしたいと思います!
今さらながら GitHub Actions をさわってみる: (入門編)
これまで GitHub はリポジトリとしてのみ活用することがほとんどでしたが、GitHub Actions のワークフローを触ってみようと思い至りました。
なぜそう思ったかというと、Amazon CodeCatalyst を触ってみたからです。
Amazon CodeCatalyst を触っていくうちに、「これはどうも GitHub の全体的な機能と似ているんじゃないかな」と個人的な感触を得ました。
Amazon CodeCatalyst のさらなる理解を深めるためには、GitHub の様々な機能を理解しておくのがよいのでは、と思ったわけです。
Amazon CodeCatalyst だけを Dive Deep するのではなく、また、GutHub だけを Dive Deep するのではなく、これら 2 つのサービスを理解し、比較していくことでさらなる理解や知見を深めることができそうだと感じています。
ということで、ひとまず GitHub Actions でワークフローを使って CI/CD 関連の機能を試していきたいと思います。
個人的には CI/CD の環境は、これまでほとんど AWS CodeBuild や AWS CodePipeline を使ってきたのですが、GitHub Actions のワークフローではどんなことができるか、AWS のクラウドのリソースと連携できるのか、などを実際に触って確認してみるつもりです。
今回は、全然知識がない中からのスタートなので、入門編 として簡単なワークフローを動かすところまでやって、その時に気づいたこと、思ったことを書いていきたいと思います!
(なお、この記事の内容は 2023 年 2 月時点で触ってみた結果に基づいています。)
クイックスタートを触ってみる
GitHub Actions を入門する上では、まず下記を試してみるのが良さそうです。
このクイックスタートは、「細かいことはさておき、ひとまず動かしてみよう!」という位置づけのようです。
ふむふむ、GutHub のリポジトリで .github/workflows フォルダをつくって、そこに YAML ファイルを作成すればよさそうです。
ただ、このクイックスタートの 手順は、Web ブラウザで GitHub のページからファイルを編集しているようですが、今回は手元の PC のローカルのリポジトリを編集して、リモートに反映させる形で試していきます。
まずは適当な名前で GitHub のリポジトリを作成して、git clone を実行します。
git clone https://github.com/tetsuo-nobe/test.git
そして .github/workflows フォルダ を作成し、クイックスタートに記載されている通りに github-actions-demo.yml というファイルを作成します。ファイル名は任意ですが、今回はクイックスタート通りにしておきました。
内容は下記です。
name: GitHub Actions Demo run-name: ${{ github.actor }} is testing out GitHub Actions 🚀 on: [push] jobs: Explore-GitHub-Actions: runs-on: ubuntu-latest steps: - run: echo "🎉 The job was automatically triggered by a ${{ github.event_name }} event." - run: echo "🐧 This job is now running on a ${{ runner.os }} server hosted by GitHub!" - run: echo "🔎 The name of your branch is ${{ github.ref }} and your repository is ${{ github.repository }}." - name: Check out repository code uses: actions/checkout@v3 - run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner." - run: echo "🖥️ The workflow is now ready to test your code on the runner." - name: List files in the repository run: | ls ${{ github.workspace }} - run: echo "🍏 This job's status is ${{ job.status }}."
上記がワークフローの内容を示すものですね。ざっとみると、どんなことが記述されているかが何となくわかります。
例えば、name や run-name は名前に関する定義だな、とか、時々出てくる ${{ }} は事前定義済の変数の内容を出力するのだろうな、とか...
さらに、steps: 以下に記載されている内容がワークフローとして実行すべき処理なのだろうな、とか...
run: は OS に対するコマンドっぽいけど、use: actions/checkout@v3 は何か違うようだ... でも、その下の echo コマンドをみると、どうもリポジトリから clone するためのもののようだ... などとボンヤリわかります。
ともあれ、クイックスタートでは、ひとまず動かしてみる ことが目的なので、このファイルを保存してリモートに push します。
実際のクイックスタートから少し手順を変えてますが、ブランチに push することにより ワークフローが実行されるはずです。
git add . git commit -m "1st commit" git push
Webブラウザから GitHub のリポジトリのページで Actions タブを選択します。
ページ左側に GitHub Actions Demo と表示されています。 YAML ファイルの冒頭にある name: で指定した名前ですね!
これが ワークフローの名前のようです。
それをクリックすると、右側にこのワークフローが実行された履歴の一覧が表示されます。
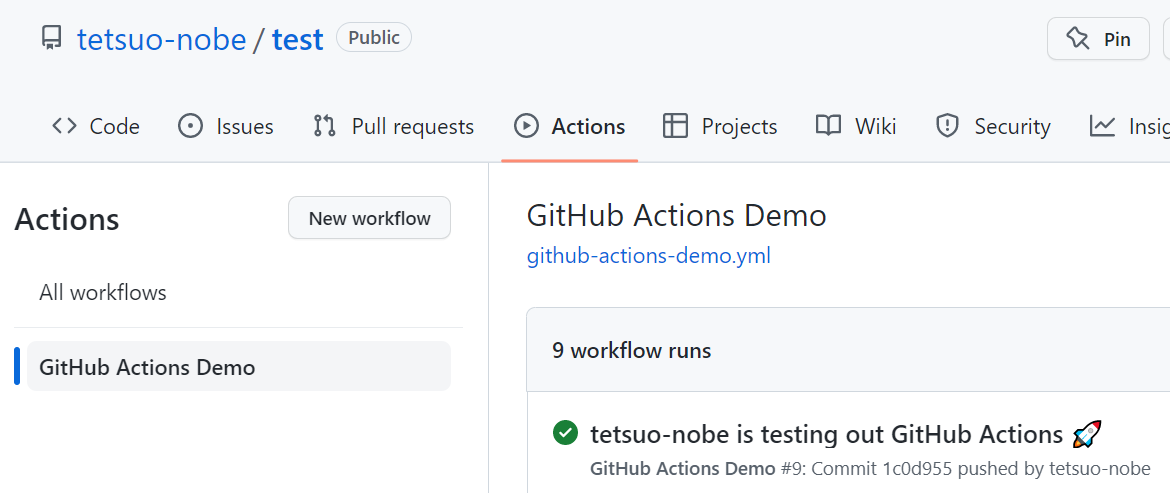
履歴の一覧の中で xxxx is testing out GitHub Actions 🚀 のリンクをクリックします。(xxxx は環境に応じて読み替えて下さい。)
緑色のチェックマークのアイコンが表示されているので、ワークフローが成功したようです。ちなみに失敗すると 赤色の × アイコンが表示されます。
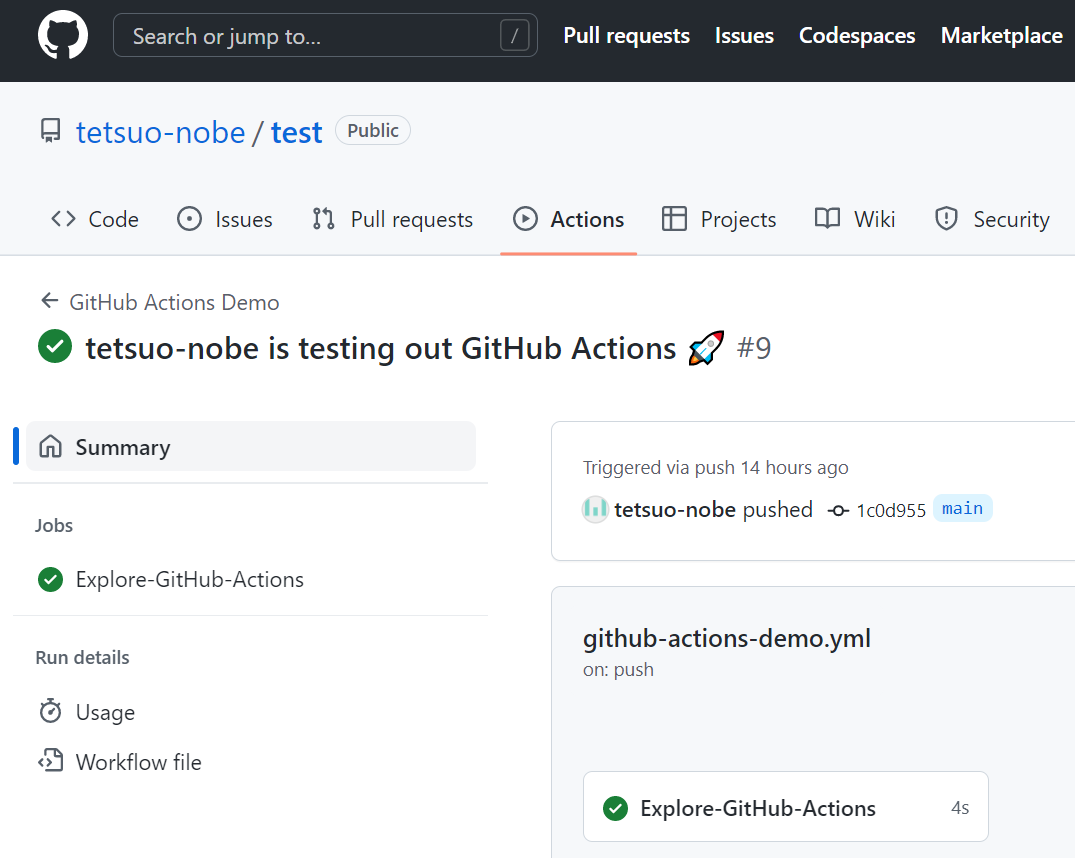
ワークフローのページが表示されるので、その中の Explore-GitHub-Actions をクリックします。
これは、ワークフローの YAML の中の jobs: で指定したジョブ名のようですね。
クリックすると、ワークフローのログが参照できます。
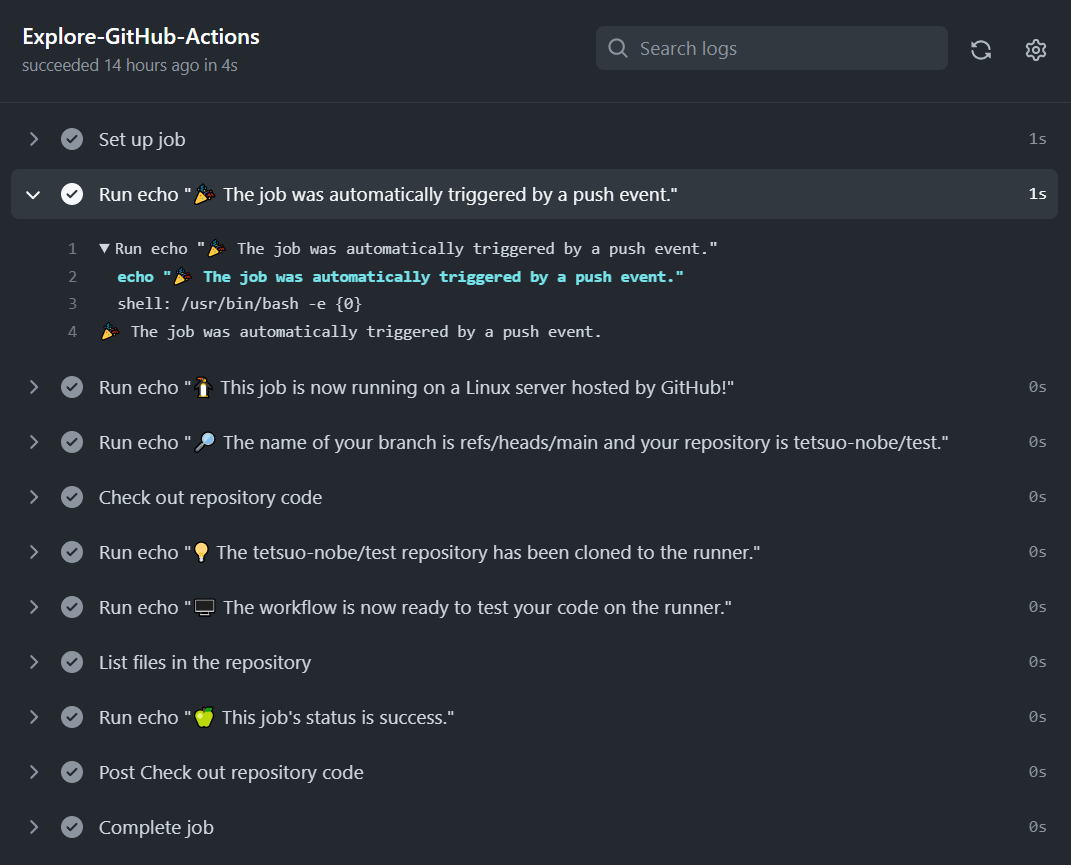
ログを見ると、ワークフローの YAML ファイルの中で steps: として定義した処理が実行されている様子がわかりますね。
ほとんど echo コマンドを実行する内容でしたが、無事にクイックスタートのワークフローは動かせたようです!
ワークフローの基本を理解する。
さて、クイックスタートでは「細かいことはさておき、とりあえず動かしてみよう」という位置づけでワークフローを実行してみましたが、もう少し体系的にワークフローの基本を理解していきたいですよね。
そこで、下記のページを読んで、さらにサンプルのワークフローを動かしてみました。
このページでは、クイックスタートと異なり、サンプルのワークフローを取り上げつつ、基本概念やワークフローの YAML の各構成要素を解説してくれています。
例えば「ワークフロー」、「ジョブ」、「ステップ」、「ランナー」という基本概念も、このページで説明されています。
また、クイックスタートで出てきた uses: actions/checkout@v3 が何だったのかがわかりますね。
actions/checkout は 複雑で頻繁に繰り返されるタスクを実行するための「アクション」であり、@v3 はバージョンの指定、use: はそのアクションをジョブのステップとして実行するキーワードであることがわかりました。
ここで、ふと疑問がわきました。クイックスタートの YAMLファイルを .github/workflows フォルダ に置いたまま、上記ページのサンプルのワークフローの YAML ファイルを追加してもいいのかな?という疑問です。
早速試してみましたが、2つの ワークフローが push をトリガーに正常に動作することを確認できました。
今回は 2つのワークフローは push をトリガーのイベントとしていますが、ワークフローの YAML の中の on: で イベントを変更することもできるようですね。
今回の所感
クイックスタートや、サンプルのワークフローを簡単に、問題なく実行できたのは嬉しいですね。
ワークフローの YAML の書き方を一度に全部覚えるのは無理があるので、色々試しながら、調べながら記憶に定着させていきます。
まだ基本中の基本の「小さな成功」でしかありませんが、この小さいな成功を積み上げていきたいです。
次回は、シンプルなアプリケーションのビルドを行うワークフローを試して記事にするつもりです!
Amazon SNS でサポートされた AWS X-Ray のアクティブトレースを試してみる
今回は、つい先日にアナウンスがあった Amazon SNS の下記の新しい機能を試してみます。
なお、この記事の内容は 2023 年 2 月 12 日時点の検証結果に基づいて記載しています。
何ができるようになったのか
これまでも、Amazon SNS トピックは、呼び出し先が AWS Lambda 関数または HTTP/HTTPS のエンドポイントの場合は、AWS X-Ray のトレースを取得するために必要なコンテキストを伝播することはできました。
そのため、下図のようにトピックを経由して AWS Lambda 関数を呼び出すまでの一連のフローを AWS X-Ray で可視化することはできました。
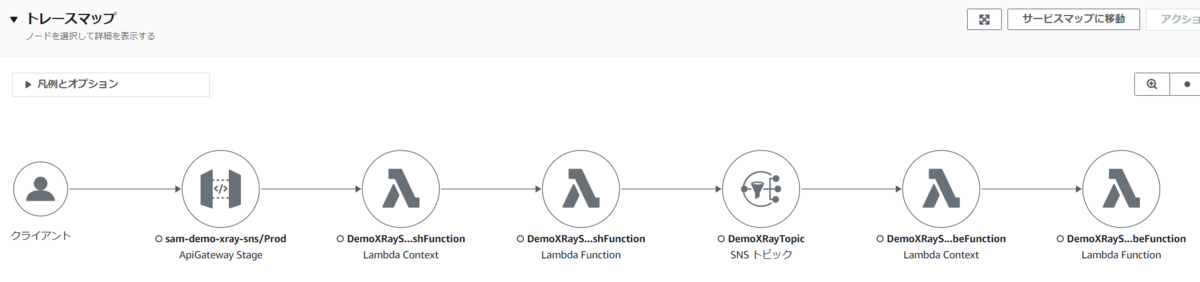
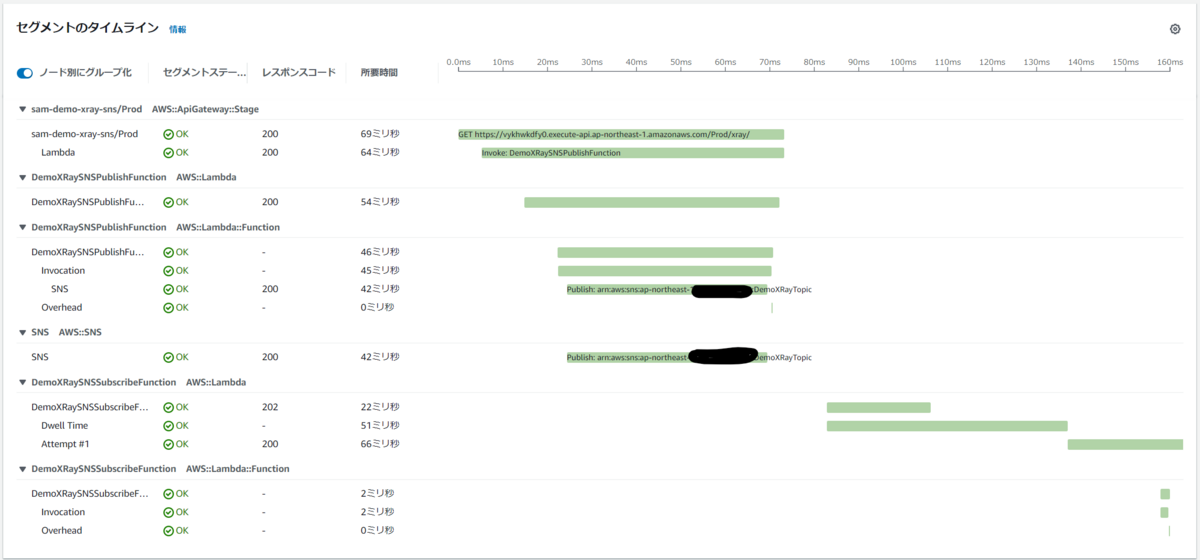
ただし、この場合、Amazon SNS のトピックは トレースのコンテキストを AWS Lambda 関数や HTTP/S のエンドポイントに伝播しているだけで、Amazon SNS のトピック自体は AWS X-Ray のトレースを出力することはできませんでした。
そのため、例えば トピックのサブスクライバーが Amazon SQS のキューの場合は、トピックからキューに対してメッセージを送信したときのトレースは取得できませんでした。
今回の Update で Amazon SNS トピックとしてどのような動作を行ったかを AWS X-Ray のトレースとして出力できるようになりました。
この機能を適用できるのは標準トピック だけで、FIFO トピックには適用できません。
また、トレース取得の対象にできるのは、サブスクライバーが 下記の場合のみです。
上記以外のEmail や SMS ( Short Message Service ) には適用できないことは留意しておきましょう。
それでは試してみましょう!
サブスクライバーが AWS Lambda 関数や Amazon SQS キュー、Email の構成で試してみる
Amazon SNS のトピックで X-Ray トレースの取得を有効化して、下図のような構成でトピックにメッセージを発行してみます。

AWS マネジメントコンソール での設定
X-Ray トレースの有効化は、AWS マネジメントコンソールの場合は トピックの設定ページの [編集] ボタンから行えます。
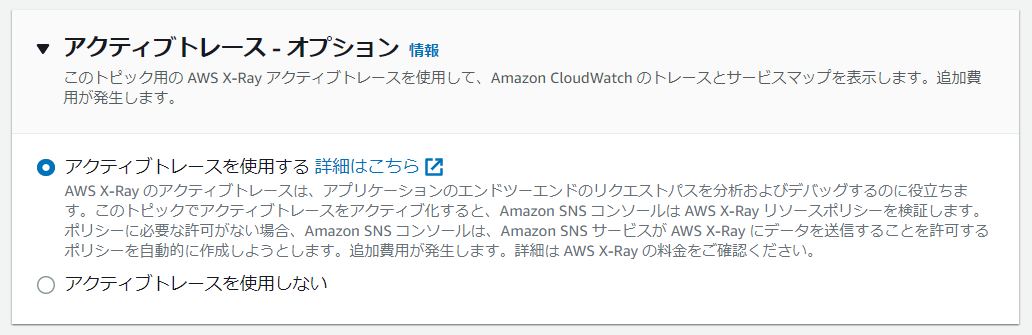
また、トピックの設定ページの 下部にある [統合] タブから有効化を確認できます。

取得したトレース
AWS マネジメントコンソールからトピックに対してメッセージを発行してトレースを取得して表示してみましょう。
今回は、Amazon CloudWatch のコンソールの左側のメニューで [ X-Ray トレース ] - [ トレース ] を選択して表示してみます。

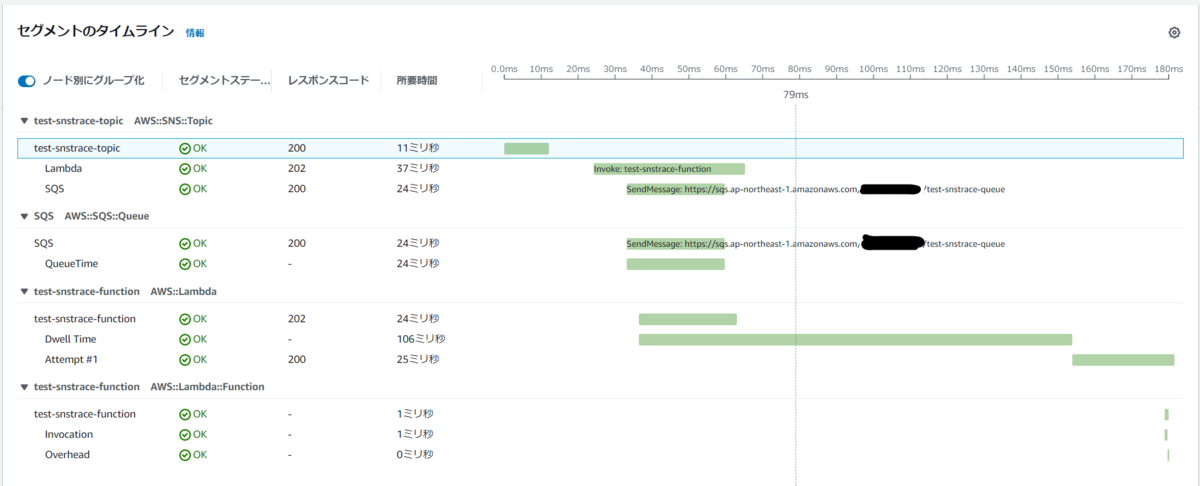
トレースマップでは、Amazon SNS トピックと サブスクライバーである Amazon SQS キューや、AWS Lambda 関数が表示されています。
セグメントのタイムラインでは、Amazon SNS が Amazon SQS キューに SendMessage API を発行、また AWS Lambda 関数を invoke する API を発行したことも表示され、その処理にかかった時間も表示されています。
実際はサブスクライバーとして Email も設定しメールも送信されているのですが、トレースには含まれていません。ただ Email はもともとトレース取得の対象外なので、これは想定通りですね。
次に、敢えて サブスクライバーとして設定している AWS Lambda 関数を削除してから トピックにメッセージを送信したときのトレースをみてみましょう。
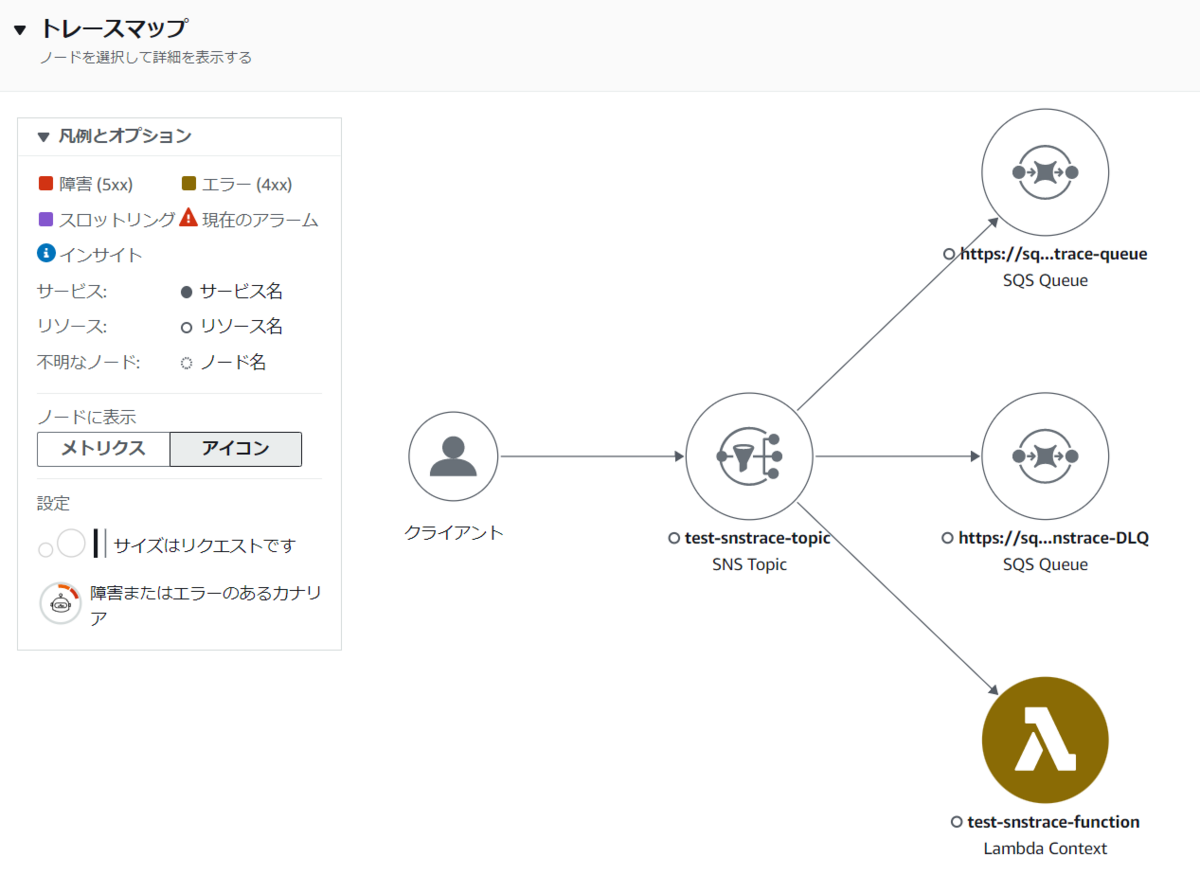
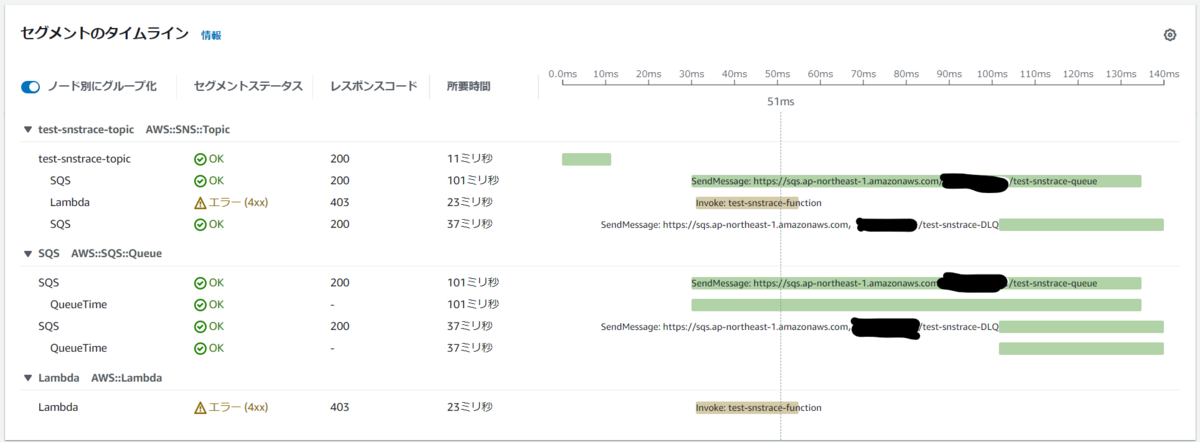
AWS Lambda 関数の invoke が エラーコード 403 で失敗していることがわかりますね。またそのため、サブスクリプションに設定した デッドレターキューに メッセージが送信されたこともわかります。
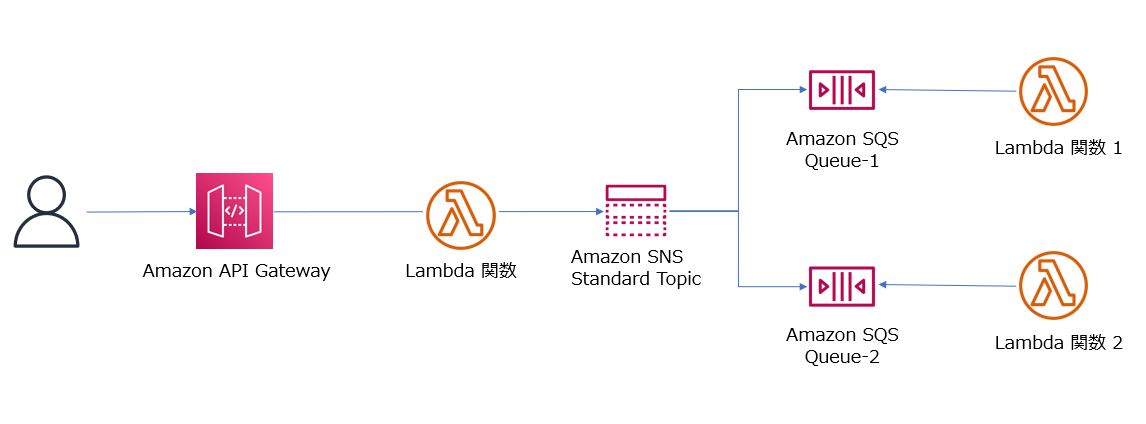
シンプルなファンアウトの構成で試してみる
次に、Amazon SNS と Amazon SQS、AWS Lambda を組み合わせて下図のようなシンプルなファンアウトを実装した場合、AWS X-Ray ではどのようにトレースを可視化できるのかを試してみます。
使用する AWS Lambda 関数のコード
今回は、Python の Lambda 関数を使用します。下記は、Amazon SNS の標準トピックにメッセージを発行する Lambda関数です。
メッセージとして、ハンドラ関数の引数であるイベントオブジェクトを文字列化したものを送信する前提とします。
import json import boto3 import datetime import os from botocore.config import Config from aws_xray_sdk.core import patch patch(['boto3']) sns = boto3.client('sns') def lambda_handler(event, context): topic_arn = os.getenv('SNS_TOPIC_ARN') dt = datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S %Z') # Topicへメッセージ送信 response = sns.publish( TopicArn=topic_arn, Message=json.dumps(event), Subject='Message from Lambda Function ' + dt ) # return { "statusCode": 200, "body": json.dumps({ "message": "Done:"+ dt }), }
次は、トピックをサブスクライブしている Amazon SQS のキューからメッセージを取得する Lambda 関数です。
関数名とイベントオブジェクトをそのまま print 関数で出力するだけのシンプルな内容です。
ファンアウトではありますが、今回はキューからメッセージを取得する 2 つの Lambda 関数は同じコードを使用します。
import json import boto3 import datetime import os from botocore.config import Config from aws_xray_sdk.core import patch patch(['boto3']) def lambda_handler(event, context): print("Lambda function name:", context.function_name) print("-----") print(event) # return { "statusCode": 200, "body": json.dumps({ "message": "Done" }), }
なお、AWS X-Ray の SDK を使用していますが、AWS X-Ray SDK のパッケージは AWS Lambda レイヤーとして用意し、今回使用する全てのLambda 関数から共用する前提にしています。
シンプルなファンアウトを構築するための AWS SAM テンプレート
もちろん、AWS マネジメントコンソールから構築しても良かったんですが、再利用性を考え 今回は AWS SAM テンプレートで構築することにしました。
Amazon API Gateway のAPI 、AWS Lambda 関数、そして今回のテーマである Amazon SNS トピックと全て AWS X-Ray のトレース取得を有効化する前提です。
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > sam-demo-xray-fanout Sample SAM Template for sam-demo-xray-fanout Parameters: SNSTOPIC: Type: String Default: 'DemoXRayFanoutTopic' SQSQUEUE1: Type: String Default: 'DemoXRayFanoutQueue1' SQSQUEUE2: Type: String Default: 'DemoXRayFanoutQueue2' Globals: Function: Timeout: 15 Tracing: Active Layers: - !Ref DemoXRayLambdaLayer Api: TracingEnabled: True Resources: DemoXRayFanoutSNSPublishFunction: Type: AWS::Serverless::Function Properties: FunctionName: 'DemoXRayFanoutSNSPublishFunction' CodeUri: demo_xray_fanout_sns_publish_function/ Handler: app.lambda_handler Runtime: python3.8 Role: !GetAtt DemoXRayFunctionRole.Arn Environment: Variables: SNS_TOPIC_ARN: !GetAtt DemoXRayTopic.TopicArn Events: DemoXRayEvent: Type: Api Properties: Path: /xray Method: get DemoXRayFanoutSQSReceiveFunction1: Type: AWS::Serverless::Function Properties: FunctionName: 'DemoXRayFanoutSQSReceiveFunction1' CodeUri: demo_xray_fanout_sqs_receive_function/ Handler: app.lambda_handler Runtime: python3.8 Role: !GetAtt DemoXRayFunctionRole.Arn Events: DemoSQSEvent: Type: SQS Properties: Queue: !GetAtt DemoXRayQueue1.Arn BatchSize: 1 DemoXRayFanoutSQSReceiveFunction2: Type: AWS::Serverless::Function Properties: FunctionName: 'DemoXRayFanoutSQSReceiveFunction2' CodeUri: demo_xray_fanout_sqs_receive_function/ Handler: app.lambda_handler Runtime: python3.8 Role: !GetAtt DemoXRayFunctionRole.Arn Events: DemoSQSEvent: Type: SQS Properties: Queue: !GetAtt DemoXRayQueue2.Arn BatchSize: 1 DemoXRayLambdaLayer: Type: AWS::Serverless::LayerVersion Properties: LayerName: 'DemoXRayLambdaLayer' CompatibleRuntimes: - python3.8 ContentUri: demo_xray_layer/xray-python.zip DemoXRayFunctionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: "sts:AssumeRole" Principal: Service: "lambda.amazonaws.com" Policies: - PolicyName: "my-demo-xray-policy" PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: - "logs:*" - "sns:*" - "sqs:*" - "xray:PutTraceSegments" - "xray:PutTelemetryRecords" Resource: "*" DemoXRayTopic: Type: AWS::SNS::Topic Properties: TopicName: !Ref SNSTOPIC TracingConfig: Active DemoXRayQueue1: Type: AWS::SQS::Queue Properties: QueueName: !Ref SQSQUEUE1 DemoXRayQueue2: Type: AWS::SQS::Queue Properties: QueueName: !Ref SQSQUEUE2 DemoXRayTopicSubscription1: Type: 'AWS::SNS::Subscription' Properties: TopicArn: !Ref DemoXRayTopic Endpoint: !GetAtt - DemoXRayQueue1 - Arn Protocol: sqs RawMessageDelivery: 'true' DemoXRayTopicSubscription2: Type: 'AWS::SNS::Subscription' Properties: TopicArn: !Ref DemoXRayTopic Endpoint: !GetAtt - DemoXRayQueue2 - Arn Protocol: sqs RawMessageDelivery: 'true' DemoXRayQueuePolicy: Type: AWS::SQS::QueuePolicy Properties: Queues: - !Ref DemoXRayQueue1 - !Ref DemoXRayQueue2 PolicyDocument: Statement: - Action: - "SQS:SendMessage" Effect: "Allow" Resource: - !GetAtt DemoXRayQueue1.Arn - !GetAtt DemoXRayQueue2.Arn Principal: Service: - "sns.amazonaws.com" Condition: ArnLike: aws:SourceArn: - !GetAtt DemoXRayTopic.TopicArn DemoXRayResoucePolicy: Type: AWS::XRay::ResourcePolicy Properties: BypassPolicyLockoutCheck: True PolicyName: "PolicyforDemoXRayFanoutTopic" PolicyDocument: !Sub | { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "sns.amazonaws.com" }, "Action": [ "xray:PutTraceSegments", "xray:GetSamplingRules", "xray:GetSamplingTargets" ], "Resource": "*", "Condition": { "StringEquals": { "aws:SourceAccount": "${AWS::AccountId}" }, "StringLike": { "aws:SourceArn": "${DemoXRayTopic.TopicArn}" } } } ] } Outputs: DemoXRayFunctionApi: Description: "API Gateway endpoint URL for Prod stage " Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/xray/"
この AWS SAM テンプレートでポイントになる部分は 2つです。
1 つ目は、104 行目 (下記)です。
TracingConfig: Active
この Amazon SNS トピックの TracingConfig プロパティで Active を指定することで、AWS X-Ray トレースの取得を有効化します。
2 つ目は、153 行目から 183 行目で、AWS X-Ray のリソースベースのポリシーを作成している部分です。
AWS マネジメントコンソールから Amazon SNS トピックに対して トレースを有効化したときには自動的に AWS X-Ray のリソースベースのポリシーも設定してくれたのですが、AWS SAM などを使用する場合は、明示的に作成する必要があります。
また、このポリシーの内容については 158行目からの PolicyDocument で指定するのですが、このプロパティは Type (型)が String になっています。
そのため、例えば 89 行目にある IAM ロールのポリシードキュメントの記述方法が異なるので注意が必要です。
89行目からの IAM ロールのポリシードキュメントは、Type が Json なので、下記のように記述できます。
PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: - "logs:*" - "sns:*" - "sqs:*" - "xray:PutTraceSegments" - "xray:PutTelemetryRecords" Resource: "*"
しかし 153行目からの AWS X-Ray の リソースポリシーのポリシードキュメントは、Type が String なので、下記のように記述する必要があります。
PolicyDocument: !Sub | { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "sns.amazonaws.com" }, "Action": [ "xray:PutTraceSegments", "xray:GetSamplingRules", "xray:GetSamplingTargets" ], "Resource": "*", "Condition": { "StringEquals": { "aws:SourceAccount": "${AWS::AccountId}" }, "StringLike": { "aws:SourceArn": "${DemoXRayTopic.TopicArn}" } } } ] }
この SAM テンプレートをデプロイしてスタックを作成し、Amazon API Gateway の API のエンドポイント URL に GET リクエストを発行することで、今回のアプリケーションが実行され、AWS X-Ray トレースも取得されます。
取得したトレース
では、取得された AWS X-Ray トレースを AWS マネジメントコンソールからみてみましょう。
まずは、Amazon CloudWatch のページから表示した サービスマップ です。
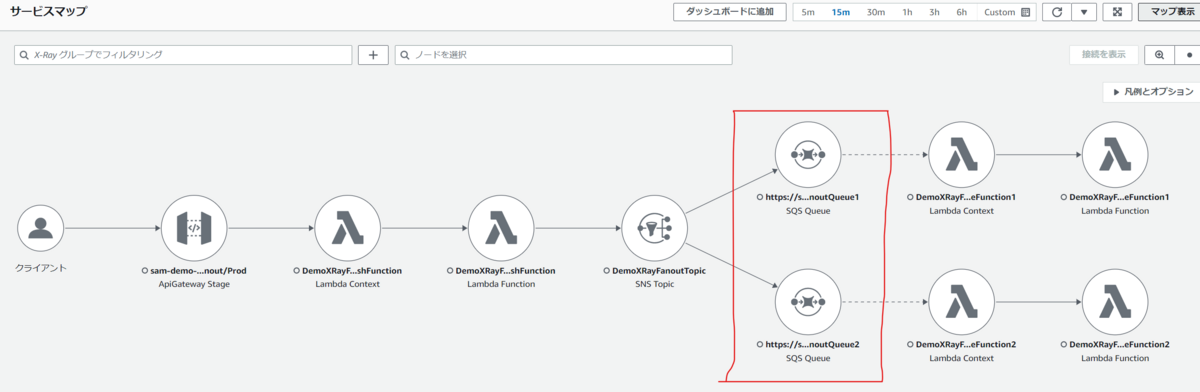
赤枠部分で、ファンアウトで Amazon SQS のキューが表示されていますね。そのキューから、さらに AWS Lambda コンテキストや AWS Lambda 関数が表示されていることがわかりますね。
これは、Amazon SNS トピックがサブスクライバーである Amazon SQS の 2 つのキューにメッセージを送信していることを示しており、そのキューをイベントソースにしている AWS Lambda 関数が実行されたこともわかります。
Amazon SQS のキューにいったんメッセージは入りますが、トレースはそこで途切れずに AWS Lambda 関数が実行されたところまでが1つのマップとして表示されています。これについては以前、ブログで記事にしたので下記を参考にしてみて下さい。
次に Amazon CloudWatch のページからトレースを選択して、トレースマップ をみてみます。
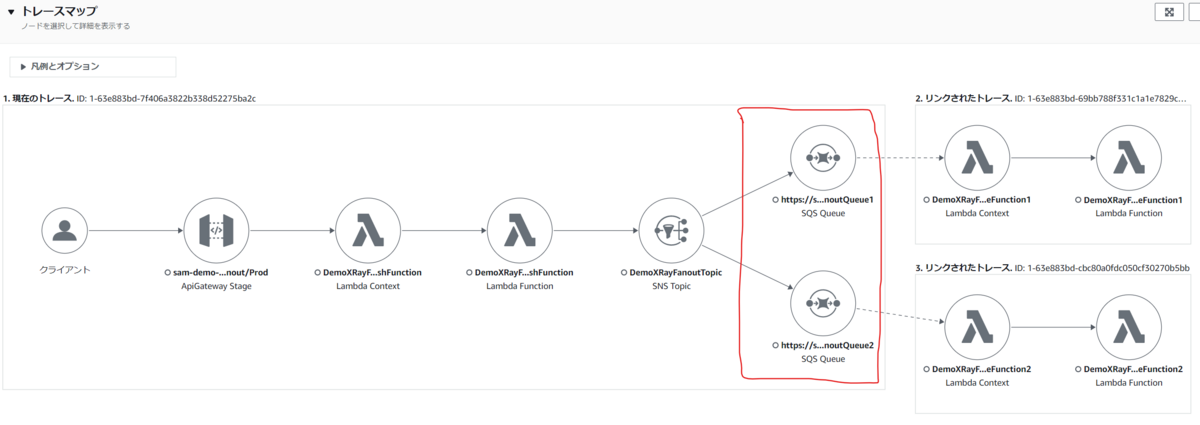
サービスマップと似ていますが、明示的に「現在のトレース」と「リンクされたトレース」を枠で分けて表示してくれていますね。
その下に表示される セグメントのタイムライン をみてみます。
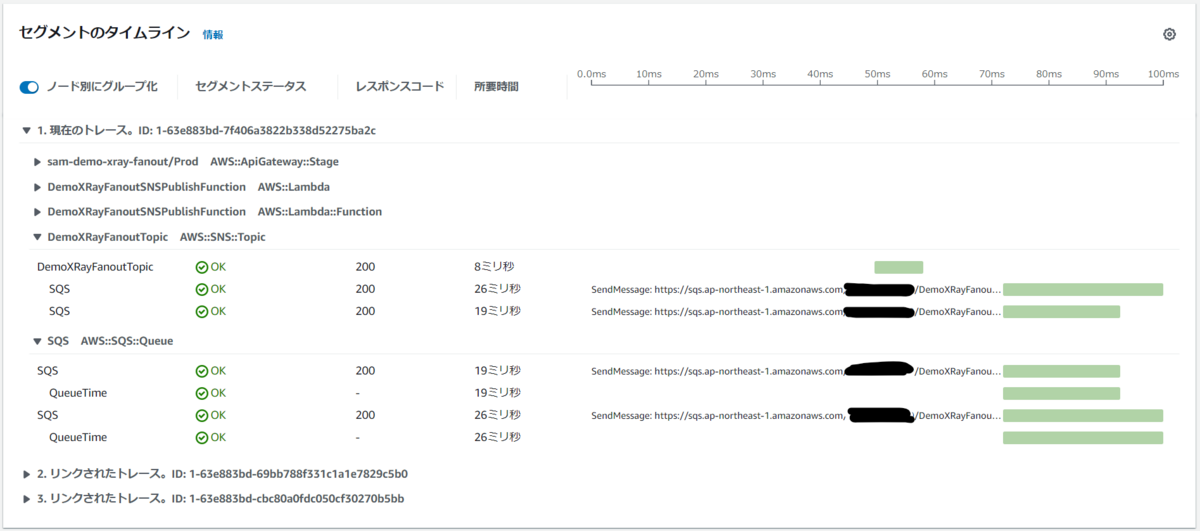
こちらも、明示的に「現在のトレース」と「リンクされたトレース」をわけて表示してくれていますね。
また、Amazon SNS のトピックをサブスクライブしている Amazon SQS の Queue について表示されており、トピックから SendMessage され、それが成功したこと、それらにかかった時間も確認できます。
最後に
これまでの Amazon SNS では AWS X-Ray については、正直、部分的な機能しかサポートされていないと感じていたのですが、今回の Update で Amazon SNS を使用したファンアウトのような構成を全体的に可視化できるようになったのは、とても便利だと感じました。
また、今回の検証を通じて、AWS X-Ray のリソースポリシーを AWS SAM ( AWS CloudFormation )で作成する方法も確認できたのも収穫でした!
Amazon Athena を AWS SDK for Python ( boto3 ) から使用してみる
前回の記事では、Amazon Athena を AWS CLI から操作してみましたが、今回は AWS SDK for Python 、つまり boto3 を使って Python のコードから Amazon Athena を操作してみます。
操作する内容は、前回の記事のAWS CLI で行った操作と同じことをやってみようと思います。
なお、この記事の内容は 2023年 1月時点で検証した結果に基づきます。
boto3 で Amazon Athena を操作するにあたって、参考にしたドキュメントは、もちろん boto3 の API リファレンスです。
boto3 の client オブジェクトを使用するので、前回の AWS CLI で使用したコマンドと一致するメソッドを見つけてコードを書けばよさそうです。
まずは、完成形を掲載します。
import boto3 import pprint workgroup_name = "my-workgroup-with-boto3" result_location = "s3://tnobe-datalake-athena-result/my-workgroup-with-boto3/" catalog_name = "AwsDataCatalog" database_name = "mydatabaseboto3" sql_create_database = "CREATE SCHEMA " + database_name sql_create_table = '''\ CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs ( \ LogDate DATE, \ Time STRING, \ Location STRING, \ Bytes INT, \ RequestIP STRING, \ Method STRING, \ Host STRING, \ Uri STRING, \ Status INT, \ Referrer STRING, \ ClientInfo STRING \ ) \ ROW FORMAT DELIMITED \ FIELDS TERMINATED BY '\t' \ LINES TERMINATED BY '\n' \ LOCATION 's3://athena-examples-ap-northeast-1/cloudfront/plaintext/' \ ''' sql_query = '''\ SELECT logdate, location, uri, status \ FROM cloudfront_logs \ WHERE method = 'GET' and status = 200 and location like 'SFO%' limit 10 \ ''' sql_drop_database = "DROP SCHEMA " + database_name client = boto3.client('athena') try: # ワークグループの作成 response = client.create_work_group( Name=workgroup_name, Configuration={ 'ResultConfiguration': { 'OutputLocation': result_location } }, Description='demo workgroup with boto3' ) # ワークグループの一覧表示 response = client.list_work_groups() print("--- Workgroup ---") pprint.pprint(response) # データベースの作成 response = client.start_query_execution( QueryString=sql_create_database, WorkGroup=workgroup_name ) # データベースの一覧表示 response = client.list_databases( CatalogName=catalog_name ) print("--- Database ---") pprint.pprint(response) # テーブルの作成 response = client.start_query_execution( QueryString=sql_create_table, QueryExecutionContext={ 'Database': database_name, 'Catalog': catalog_name }, WorkGroup=workgroup_name ) # クエリーの発行 response = client.start_query_execution( QueryString=sql_query, QueryExecutionContext={ 'Database': database_name, 'Catalog': catalog_name }, WorkGroup=workgroup_name ) # QueryExecutionId の取得 query_exec_id = response["QueryExecutionId"] # クエリーが終了するまで待機 status = "" while status != "SUCCEEDED": response = client.get_query_execution( QueryExecutionId=query_exec_id ) status = response["QueryExecution"]["Status"]["State"] print(status) # クエリーの結果取得 response = client.get_query_results( QueryExecutionId=query_exec_id ) print("--- Query Result ---") pprint.pprint(response) except Exception as e: print(e) finally: print("--- Drop Database ---") response = client.start_query_execution( QueryString=sql_drop_database, WorkGroup=workgroup_name ) print("--- Delete Workgroup ---") response = client.delete_work_group( WorkGroup=workgroup_name, RecursiveDeleteOption=True ) print("--- END ---")
このコードのポイント部分をみていきます。
最初は、6 行目と 7行目(下記)です。
database_name = "mydatabaseboto3" sql_create_database = "CREATE SCHEMA " + database_name
上記のように、AWS CLI 使用時と同じくデータベース作成時に CREATE DATABASE ではなく、CREATE SCHEMA を使用しなければエラーになります。、
これは、データベース削除時も同じで DROP DATABASE ではなく DROP SCHEMA にする必要があります。
また、データベース名に ハイフン (-) を含めることができません。
次に、86 行目から 93 行目(下記)に注目して下さい。
# クエリーが終了するまで待機
status = ""
while status != "SUCCEEDED":
response = client.get_query_execution(
QueryExecutionId=query_exec_id
)
status = response["QueryExecution"]["Status"]["State"]
print(status)
AWS CLI を使用する時は 1 つ 1 つのコマンドの実行の間に時間があったので問題なかったのですが、Python のコードでクエリー発行から結果取得まで一気に行うと、まだクエリーが完了していない状態で結果を取得しようとしてしまうこともあり、下記のエラーが発生します。
An error occurred (InvalidRequestException) when calling the GetQueryResults operation: Query has not yet finished. Current state: QUEUED
よって、get_query_execution メソッドを使用してクエリーのステータスが SUCCEEDED になるまで待機してから結果を取得するようなコードにしています。
ループで待機せず、Waiter のような自動的に待機してくれる方法があればいいのですが、見当たらなかったため、致し方なく while ループを使いました。
ちなみに、ステータスとしては、クエリー発行後は QUEUED 、クエリー実行中は RUNNING、クエリーが成功したら SUCCEEDED となります。
この Python のコードを実行すると、Amazon Athena のワークグループの一覧、データベースの一覧、クエリ結果が表示されます。
下記は、クエリ結果部分を抜粋した内容です。
--- Query Result --- {'ResponseMetadata': {'HTTPHeaders': {'connection': 'keep-alive', 'content-length': '2183', 'content-type': 'application/x-amz-json-1.1', 'date': 'Sun, 22 Jan 2023 08:18:03 GMT', 'x-amzn-requestid': '216f5ef6-8e7c-479a-976a-1c5dcb43bedd'}, 'HTTPStatusCode': 200, 'RequestId': '216f5ef6-8e7c-479a-976a-1c5dcb43bedd', 'RetryAttempts': 0}, 'ResultSet': {'ResultSetMetadata': {'ColumnInfo': [{'CaseSensitive': False, 'CatalogName': 'hive', 'Label': 'logdate', 'Name': 'logdate', 'Nullable': 'UNKNOWN', 'Precision': 0, 'Scale': 0, 'SchemaName': '', 'TableName': '', 'Type': 'date'}, {'CaseSensitive': True, 'CatalogName': 'hive', 'Label': 'location', 'Name': 'location', 'Nullable': 'UNKNOWN', 'Precision': 2147483647, 'Scale': 0, 'SchemaName': '', 'TableName': '', 'Type': 'varchar'}, {'CaseSensitive': True, 'CatalogName': 'hive', 'Label': 'uri', 'Name': 'uri', 'Nullable': 'UNKNOWN', 'Precision': 2147483647, 'Scale': 0, 'SchemaName': '', 'TableName': '', 'Type': 'varchar'}, {'CaseSensitive': False, 'CatalogName': 'hive', 'Label': 'status', 'Name': 'status', 'Nullable': 'UNKNOWN', 'Precision': 10, 'Scale': 0, 'SchemaName': '', 'TableName': '', 'Type': 'integer'}]}, 'Rows': [{'Data': [{'VarCharValue': 'logdate'}, {'VarCharValue': 'location'}, {'VarCharValue': 'uri'}, {'VarCharValue': 'status'}]}, {'Data': [{'VarCharValue': '2014-08-05'}, {'VarCharValue': 'SFO4'}, {'VarCharValue': '/test-image-3.jpeg'}, {'VarCharValue': '200'}]}, (・・・中略・・・) {'Data': [{'VarCharValue': '2014-08-05'}, {'VarCharValue': 'SFO4'}, {'VarCharValue': '/test-image-2.jpeg'}, {'VarCharValue': '200'}]}]}, 'UpdateCount': 0}
上記結果の 50 行目以降で、クエリー結果のデータを表示することができていますね。
なお、このサンプルのコードでは、finally 句を使用して最後に Amazon Athena で作成したデータベースやワークグループを削除していますが、これは単に環境をクリアしておきたいという意図があるだけです。
最後に:
Amazon Athena を AWS CLI から使用してみる
今回は、AWS CLI を使って Amazon Athena のデータベースとテーブル、ワークグループを作成し、クエリーを発行してみます。
標準 SQL を使用して Amazon S3のバケット内のデータに対して直接クエリーを発行して集計や分析が行えるインタラクティブなサービスです。
AWS マネジメントコンソールを使用して容易に操作することもできますが、AWS CLI だとどのようなコマンドになるのか試してみます。
なお、この記事の内容は 下記のドキュメントを参考に、2023年 1月に検証した内容に基づいています。Linux で AWS CLI v2 を使用する前提とします。
Amazon Athena には ワークグループ というグルーピングの概念があり、ワークグループ単位で処理できるデータ量や Amazon CloudWatch のメトリクスの設定などを行えます。
デフォルトでも primary というワークグループがあり、それを使用できますが今回は新たにワークグループ my-workgroup を作成する前提とします。
まず、ワークグループで発行したクエリ結果を保存するための Amazon S3 のバケットとフォルダをあらかじめ作成しておきます。
ここでは、バケット tnobe-datalake-athena-result のフォルダ my-workgroup とします。
次に AWS CLI でワークグループ my-workgroup を作成します。
# ワークグループの作成 aws athena create-work-group \ --name my-workgroup \ --configuration ResultConfiguration={OutputLocation="s3://tnobe-datalake-athena-result/my-workgroup/"} \ --description "demo workgroup"
今回は、クエリーの結果の保存先以外の設定はデフォルトのままにしています。
ワークグループの作成を確認するため、次の AWS CLI コマンドを発行します。
# ワークグループの一覧表示
aws athena list-work-groups
下記のように、primary の他に my-workgroup が表示されていれば OK です。
{
"WorkGroups": [
{
"Name": "my-workgroup",
"State": "ENABLED",
"Description": "demo workgroup",
"CreationTime": "2023-01-09T03:12:47.798000+00:00",
"EngineVersion": {
"SelectedEngineVersion": "AUTO",
"EffectiveEngineVersion": "Athena engine version 2"
}
},
{
"Name": "primary",
"State": "ENABLED",
"Description": "",
"CreationTime": "2022-12-22T23:20:09.520000+00:00",
"EngineVersion": {
"SelectedEngineVersion": "AUTO",
"EffectiveEngineVersion": "Athena engine version 2"
}
}
]
}
では次に データベースを作成します。今回は mydatabase という名前にします。
# データベースの作成 aws athena start-query-execution \ --query-string "CREATE SCHEMA mydatabase" \ --work-group "my-workgroup"
作成したデータベースを確認します。
# データベースの一覧表示 aws athena list-databases --catalog-name AwsDataCatalog
環境によっては複数のデータベースが表示されますが、下記のように mydatabase が表示されれば OK です。
{
"Name": "mydatabase"
}
ここであることに気づきました。
AWS マネジメントコンソールにて、Amazon Athena のクエリエディタからデータベースを作成する場合は、次のコマンドで作成できます。
CREATE DATABASE mydatabase
しかし、AWS CLI の start-query-execution コマンドを使用して上記データベースを作成する SQL を発行すると、次のようなエラーが発生します。
An error occurred (InvalidRequestException) when calling the StartQueryExecution operation: line 1:8: mismatched input 'database'. Expecting: 'OR', 'SCHEMA', 'TABLE', 'VIEW'
つまり、CREATE DATABASE が使えないという事ですね。
しかし、次のドキュメントに、CREATE DATABASE は CREATE SCHEMA と同じでどちらでも使用できると記載されています。
よって今回は CREATE SCHEMA を使用しました。
また、データベースの名前を my-database のように ハイフン (-) を含んだ名前にすると次のようなエラーになります。
An error occurred (InvalidRequestException) when calling the StartQueryExecution operation: line 1:17: mismatched input '-'. Expecting: '.', 'WITH', <EOF>
これも AWS マネジメントコンソールでは発生しないエラーなので、少しハマってしまいました。
このように、AWS CLI ならではの書き方が必要なケースがあるので、注意が必要です。
データベースが作成できたら、次はテーブルを作成します。
今回は、Amazon Athena のチュートリアル用として公開されている CloudFrontへのアクセスログデータを使用します。
# テーブルの作成 aws athena start-query-execution \ --query-string \ "CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs ( \ LogDate DATE, \ Time STRING, \ Location STRING, \ Bytes INT, \ RequestIP STRING, \ Method STRING, \ Host STRING, \ Uri STRING, \ Status INT, \ Referrer STRING, \ ClientInfo STRING \ ) \ ROW FORMAT DELIMITED \ FIELDS TERMINATED BY '\t' \ LINES TERMINATED BY '\n' \ LOCATION 's3://athena-examples-ap-northeast-1/cloudfront/plaintext/'" \ --query-execution-context Database=mydatabase
テーブルを作成したら、さっそくクエリーを発行してみます。
aws athena start-query-execution \ --query-string "select logdate, location, uri, status from cloudfront_logs where method = 'GET' and status = 200 and location like 'SFO%' limit 10" \ --work-group "my-workgroup" \ --query-execution-context Database=mydatabase
クエリーを発行すると次のような ID 値が返されるので、メモしておきます。
{
"QueryExecutionId": "0df4e7c9-b9f7-46cf-92f0-42344cdfce23"
}
この ID 値を指定して、クエリーの結果を取得します。
aws athena get-query-results \ --query-execution-id 0df4e7c9-b9f7-46cf-92f0-42344cdfce23
次のように、カラム名とクエリーの結果が表示されれば OK です。
{
"ResultSet": {
"Rows": [
{
"Data": [
{
"VarCharValue": "logdate"
},
{
"VarCharValue": "location"
},
{
"VarCharValue": "uri"
},
{
"VarCharValue": "status"
}
]
},
{
"Data": [
{
"VarCharValue": "2014-07-05"
},
{
"VarCharValue": "SFO4"
},
{
"VarCharValue": "/test-image-2.jpeg"
},
{
"VarCharValue": "200"
}
]
},
{
"Data": [
{
"VarCharValue": "2014-07-05"
},
{
"VarCharValue": "SFO4"
},
{
"VarCharValue": "/test-image-2.jpeg"
},
{
"VarCharValue": "200"
}
]
},
・・・(以下略)・・・
最後に
AWS CLI ならではの書き方のところは要注意ですが、コマンドの種類もそんなに多くなく、パラメータの書き方もさほど複雑ではないので思いのほかシンプルに記述できた、というのが感想です!