AWS Compute Optimizer で Lambda 関数の推奨事項を提示させてみた!

本記事は「AWS LambdaとServerless Advent Calendar 2023」3 日目の記事です。
今回は、AWS Compute Optimizer を使って Lambda 関数のメモリ設定に関する推奨事項を確認してみます!
目次
AWS Lambda 関数のメモリ設定の最適値導出について
AWS Lambda の Lambda 関数には使用するメモリ容量を設定できますが、この設定されたメモリ容量に比例して CPU パワーも割り当てられます。
また、メモリ容量の設定は、Lambda 関数のコストにも影響します。
よって、Lambda 関数のメモリ容量を設定する場合は、パフォーマンスとコストの両面から最適値を導き出すことが重要となります。
そんな時には、下記のサービスやツールの使用を検討してみて下さい。
AWS Compute Optimizer
AWS Compute Optimizer は、Lambda 関数や、EC2 インスタンス、EC2 AutoScaling Group、EBS ボリュームなどの最適化について推奨事項を提示してくれるサービスです。
AWS Lambda Power Tuning
AWS Lambda Power Tuning は、Lambda 関数を対象にさまざまなメモリ割り当てを選択し、実行時間とコストを測定することで最適値の分析を支援してくれるツールです。 具体的には、AWS Step Functions のステートマシンを使用し、測定対象の Lambda 関数を実行して分析用のデータを収集します。
AWS Lambda Power Tuning は、筆者も AWS のサーバーレスのトレーニング登壇時によくデモを実施しているのですが、この記事では、AWS Compute Optimizer に着目していきたいと思います!
AWS Compute Optimizer における Lambda 関数の要件
以下のドキュメントにも記載がありますが、AWS Compute Optimizer で Lambda 関数の推奨を提示させるにはいくつか要件があります。
要件
Lambda 関数に設定されているメモリは 1,792 MB 以下であること
Lambda 関数は過去 14 日間に少なくとも 50 回呼び出されていること
2023 年 12 月現在、Lambda 関数には最大 10,240 MB のメモリを設定できるので、「1,782 MB 以下であること」という要件には少し疑問が残りましたが、今回はこの要件にマッチする Lambda 関数を用意して、推奨事項を提示してくれるか確認してみることにしました。
この要件をみると、AWS Compute Optimizer は、AWS Lambda Power Tuning のように、その場で Lambda 関数を実行してすぐに結果を出すのではなく、ある程度の期間、実行された Lambda 関数の情報から推奨事項を出してくれるので、現在、運用中の本番環境のワークロードを対象にしやすいというメリットがありますね。(本番環境で推奨事項を出すために AWS Lambda Power Tuning で実際に Lambda 関数を実行するのは、一般的には避けたいですよね。)
測定対象の Lambda 関数
今回は、測定対象として以下の Lambda 関数を Python で実装しました。
| 名前 | 設定メモリ(MB) | 処理内容 |
|---|---|---|
| demo-memory-under-provisioned | 128 | 設定値である 128 MB ギリギリまでメモリを使用する(メモリ割り当てが十分でない状況にする) |
| demo-OOM | 128 | メモリ不足でエラーが発生する処理をする(関数エラーが発生する状況にする) |
| My-CPU-eater-function | 128 | 1 回の呼出しで CPU を 5 秒間使用し続ける |
上の表のうち、demo-memory-under-provisioned は、Lambda 関数で使用するメモリが設定値ギリギリまで使用するコードになっていることは、ログで確認できています。 下記はこの Lambda 関数実行時の REPORT ログですが、Memory Size の値と Max Memory Used の値が同じ になっていますね。ただ、メモリ不足エラーが起こらないように、あくまでギリギリにしています。
REPORT RequestId: xxx Duration: 2229.80 ms Billed Duration: 2230 ms Memory Size: 128 MB Max Memory Used: 128 MB
これらの Lambda 関数を Amazon Event Bridge のスケジューラを使用して定期的に実行して、14 日以上経過した後に AWS Compute Optimizer で推奨事項が表示されるか確認してみます。
(追記:メモリ割り当てが過剰な Lambda 関数についてもテストしようとしたのですが、なぜか今回の検証では Compute Optimizer でうまく検知させることができませんでしたので、これはあらためて調査したいと思います!mm)
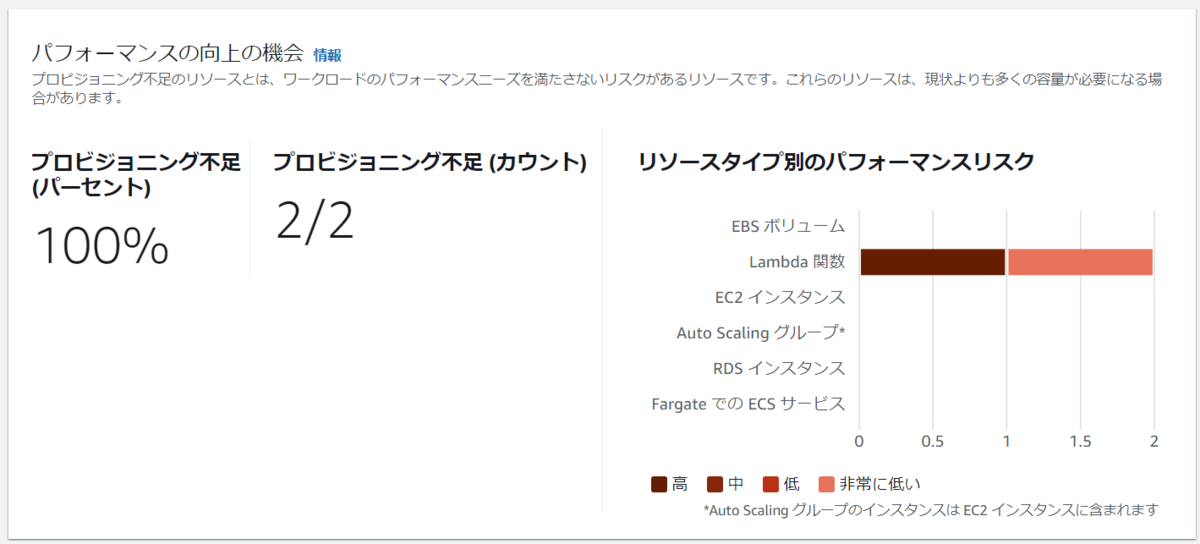
結果
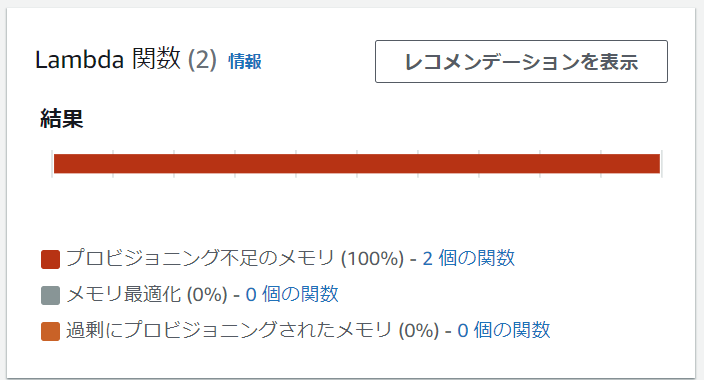
結論からすると、メモリ割り当てが不十分なもの、CPU を 5 秒間消費するものについては、推奨事項が表示されました。 ただ、メモリ不足でエラーが発生したものについては、推奨事項は表示されませんでした。
AWS マネジメントコンソールで AWS Compute Optimizer のダッシュボードでは、次のように表示されました。
レコメンデーションの表示
上の図のダッシュボードで、「レコメンデーションを表示」をクリックすると、次のように各関数毎の情報が表示されます。(下記は抜粋です。)
Lambda 関数のバージョンや検出理由
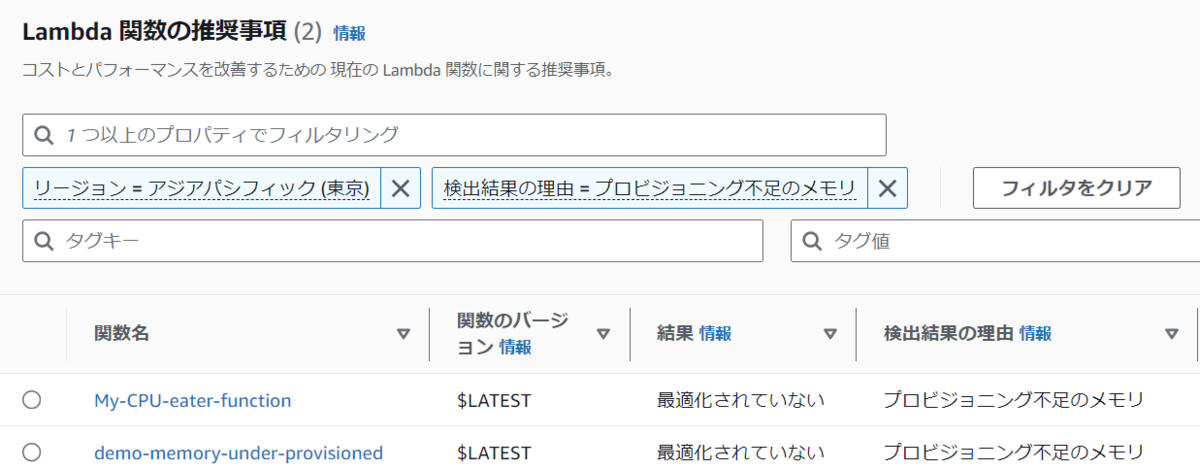
Lambda 関数の現在設定されているメモリと推奨設定メモリ
推奨値を出してくれるのは、ありがたいですね!

- Lambda 関数の現在のコストと推奨コストや、そのコスト差
推奨値を適用した場合のコスト予測も出してくれるので、パフォーマンスだけでなくコストも含めて分析できます。

まとめ
AWS Compute Optimizer が、以下のような Lambda 関数について推奨事項を提示してくれることを確認できました。
- メモリの割り当てが不十分な Lambda 関数
- CPUを多く消費している Lambda 関数
ただ、今回のテストケースでは、メモリ不足で関数エラーが発生した Lambda 関数については推奨事項が提示されることはありませんでした。ただこのケースでは、関数エラーが発生しているのですぐにログで問題を検出できるため、Compute Optimizer で検出させるまでもない、と考えることもできますね。
所感
普段は、デモの実施のしやすさから AWS Lambda Power Tuning を説明する機会が多いのですが、今回、AWS Compute Optimizer について検証し、新たな気づきを得ることができたので、AWS Compute Optimizer についても積極的に情報発信していこうと思います!
Amazon API Gateway のリクエスト本文検証時のエラーメッセージを変更してみる

Amazon API Gateway のリクエスト検証機能は広く知られているかもしれませんが、今回はリクエスト本文検証時のエラーメッセージを変更して詳細な情報を表示する方法を紹介します。
これは、数ヵ月前に私が登壇したトレーニングの受講者の質問から気づけた Tips です。(整理してブログで紹介しようと思っていながら遅れに遅れてしまいました 🙇♂️)
なお、この記事の内容は 2023 年 5 月に検証した内容に基づきます。
目次
- Amazon API Gateway のリクエスト検証
- PetStore API の作成
- リクエストのクエリ文字列パラメータの検証
- リクエストの本文の検証
- リクエストの本文の検証時のエラーメッセージの変更
- 今回の所感
Amazon API Gateway のリクエスト検証
Amazon API Gateway の REST API では、API のリクエスト内容を検証できます。
例えば、特定のクエリ文字列パラメータや HTTP ヘッダ を必須とした場合、それがリクエストに含まれているかを検証したり、リクエスト本文が特定のフォーマットになっているかを検証できます。
今回は Amazon API Gateway の API のサンプルとして使用できる PetStore API を使用して、リクエスト検証の機能についてみていきましょう。その後、リクエスト本文の検証時のエラーメッセージを変更していきます!
PetStore API の作成
AWS マネジメントコンソールから Amazon API Gateway のコンソールを表示し、API の作成を開始します。その際、API タイプとして [ REST API ] を選択して作成します。( [ REST API プライベート] ではないのでご注意ください。)

その後、下図のように [ API の例 ] を選択して ページ右下の[インポート] を選択します。
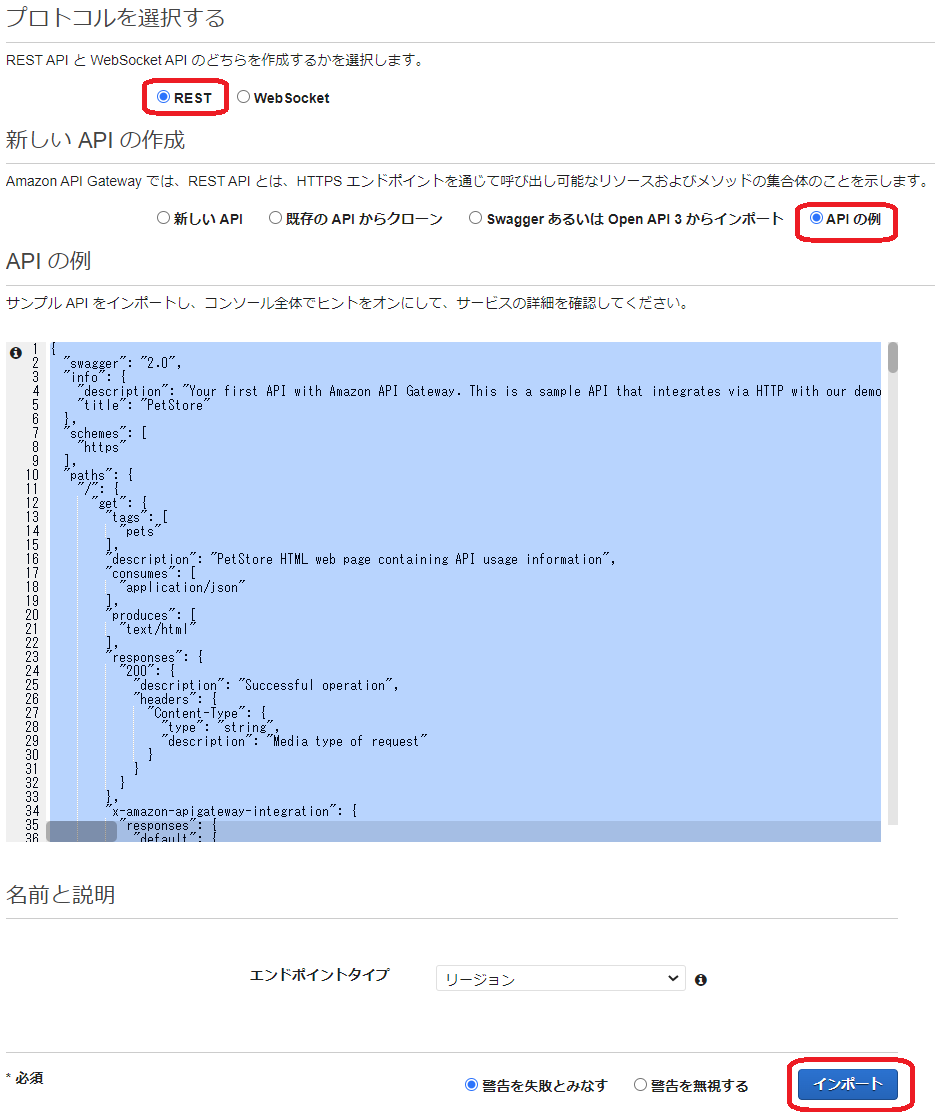
これで、サンプルである PetStore API が作成できました。
リクエストのクエリ文字列パラメータの検証
この PetStore API に必須のクエリ文字列を設定してみます。(もちろん、これはリクエストの検証機能を試すための設定で、PetStore API としては本来は必要ないものです。)
下図のように、[リソース] 、/pets の POST メソッド、[メソッドリクエスト] の順で選択します。

そして、[リクエストの検証] で鉛筆アイコンをクリックして、 [本文、クエリ文字列パラメータ、およびヘッダーの検証] を選択し、右横のチェックマークをクリックします。これを選択したのは、あとで本文の検証も確認するためです。

[URL クエリ文字列パラメータ ] を展開表示して、[クエリ文字列の追加] を選択します。
鉛筆アイコンをクリックした後に表示される入力エリアに、クエリ文字列パラメータ名を入力します。今回はテスト用なのでどんな名前でもいいのですが、ここでは プレースホルダーに表示されている通り myQueryStringにしておきます。その後チェックマークをクリックして、[必須] にチェックをしておきましょう。
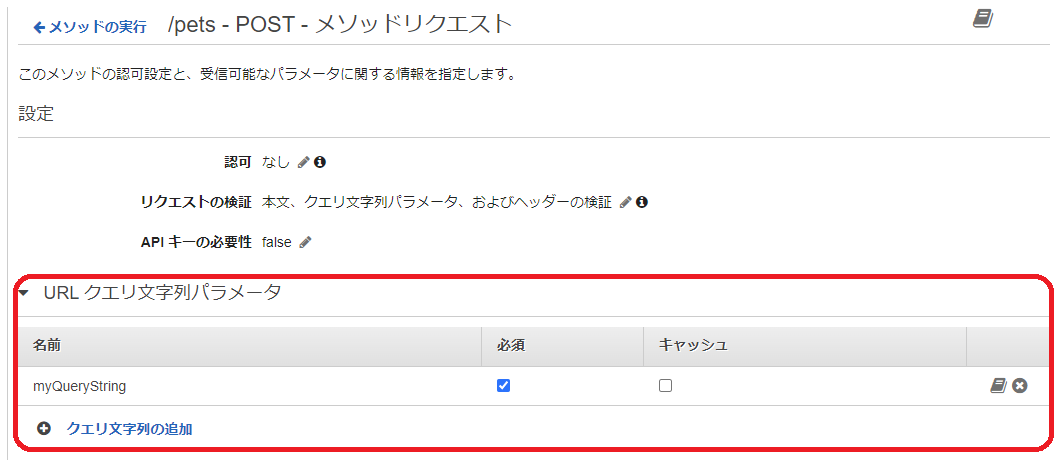
この設定により、PetStore API で /pets のパスで POST メソッドの API を発行する時は、クエリ文字列パラメータ名 として myQueryString が必須になりました。リクエストは検証され、もしこのパラメータが無い場合は、エラーとなるように設定できました。
この後、[アクション] から [API のデプロイ] を選択して、[デプロイされるステージ] として [新しいステージ] を選択します。[ステージ名] は任意ですがここでは [dev] と指定して [デプロイ] を選択します。
その後表示される [ URL の呼び出し:] の URL をメモしておきます。東京リージョンを使用している場合は、下記のような URL になっているはずです。
https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev
では curl コマンドを使用して API を実行してみます。
まず、myQueryString クエリ文字列パラメータを含めたリクエストを発行してみます。
curl -X POST "<メモしておいたAmazon API Gateway のURL>/pets/?myQueryString=dummy" -H "Content-Type: application/json" -d '{ "type": "dog", "price": 50000 }'
リクエストは正常に処理され、下記のようなレスポンスが表示されます。
"pet": {
"type": "dog",
"price": 50000
},
"message": "success"
}
次にmyQueryString クエリ文字列パラメータなしでリクエストを発行してみます。
curl -X POST "<メモしておいたAmazon API Gateway のURL>/pets" -H "Content-Type: application/json" -d '{ "type": "dog", "price": 50000 }'
下記のようなレスポンスが表示されます。メッセージをみると、必須パラメータが指定されていないということがわかります。
message": "Missing required request parameters: [myQueryString]"}
Amazon API Gateway のリクエスト検証が期待通りに動作していることが確認できました。
リクエストの本文の検証
次はリクエスト本文の検証を試しますが、PetStore API は、下図のようにすでに本文の検証が設定されています。

上図では [モデル名] として [NewPet] が指定されており、この NewPet モデルで定義されたスキーマに基づき本文の内容が検証されます。
このモデルの定義は、Amazon API Gateway のコンソールの左側のメニューから [モデル] を選択することで確認できます。
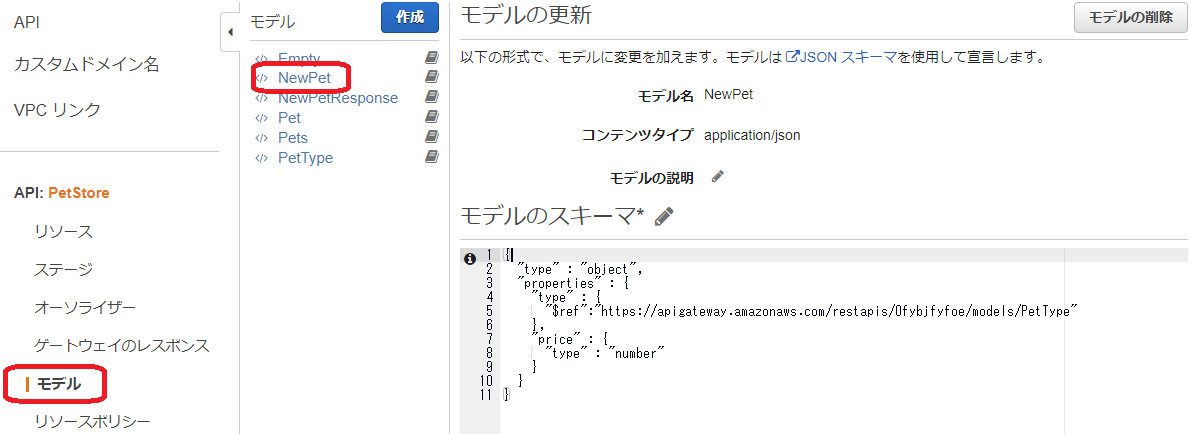
このモデルが参照している Type として PetType がありますが、これもコンソールから参照できます。
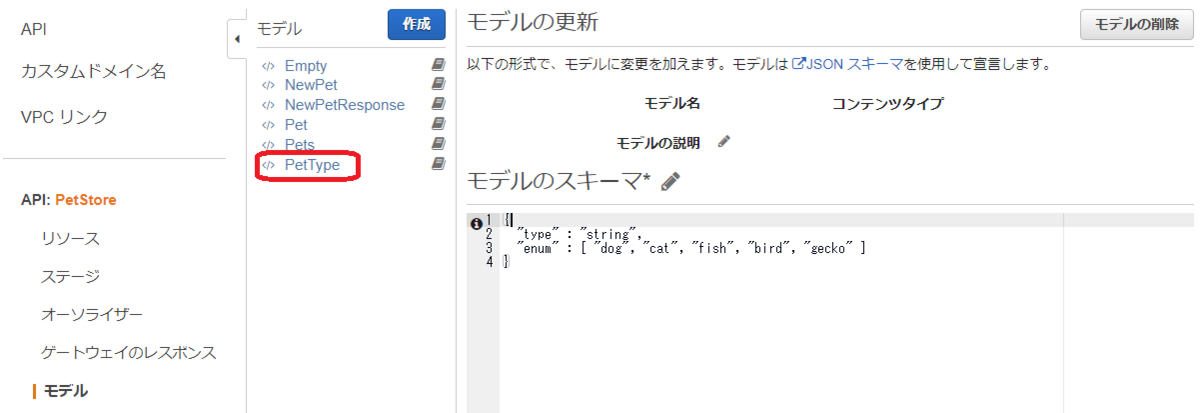
つまり、リクエスト本文のコンテンツタイプは application/json で、type キーと price キーが必要、また type の値は 文字列で "dog", "cat", "fish", "bird", "gecko" のいずれかでなくてはいけません。さらに price は数値でなくてはいけない、ということになります。
では、curl コマンドで確認します。正常処理はさきほどのクエリ文字列パラメータのテストで確認できているので、ここではスキーマに合致しない本文データを指定してみます。
curl -X POST "<メモしておいたAmazon API Gateway のURL>/pets/?myQueryString=dummy" -H "Content-Type: application/json" -d '{ "type": "tiger" ,"price": 50000 }'
リクエストは検証され、スキーマに合致しないのでエラーになりました。
{"message": "Invalid request body"}
ただし、なぜエラーになったのか知りたい場合はどうすればいいでしょうか?この Invalid request body というエラーメッセージだけでは、本文のどこが正しくないのか判別できません。 もちろん、要件的にそれで問題ない場合もありますが、開発やテストフェーズでは検証エラーの理由を確認できた方が便利な場合もあります。
そこで、このデフォルトのエラーメッセージを変更してみます!
リクエストの本文の検証時のエラーメッセージの変更
下図のように、Amazon API Gateway のコンソールの左側のメニューで [ゲートウェイのレスポンス] 、[リクエスト本文が不正です] をクリックして、ページ右上の [編集] をクリックします。
[レスポンステンプレート] で [application/json] を選択して、[レスポンステンプレートの本文] を {"message":$context.error.validationErrorString} に変更して [保存] します。
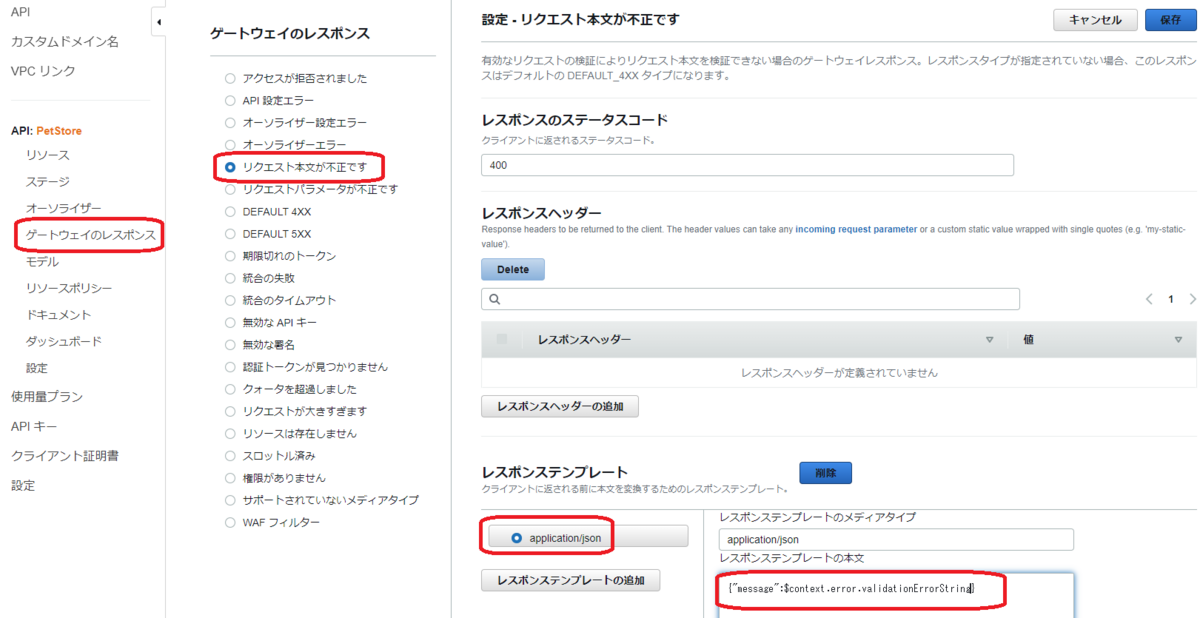
$context.error.validationErrorString は、$context 変数とよばれるものの一種で、これを使用することで詳細な検証エラーメッセージを表示できます。
この変更後、Amazon API Gateway のコンソールの左側のメニューで [リソース] を選択して、もう一度 dev ステージを指定して API のデプロイを行ってください。
では、さきほどと同じスキーマに合致しないリクエストを発行してみます。
curl -X POST "<メモしておいたAmazon API Gateway のURL>/dev/pets/?myQueryString=dummy" -H "Content-Type: application/json" -d '{ "type": "tiger" ,"price": 50000 }'
今回は下記のように、詳細なエラーメッセージを確認することができました。
message":[instance value (\"tiger\") not found in enum (possible values: [\"dog\",\"cat\",\"fish\",\"bird\",\"gecko\"])]}
その他、下記のようなパターンでリクエスト検証を試してみましたが、スキーマに合致しないリクエストはすべて詳細なエラーメッセージを表示することができました。
price に数値以外を指定した場合
curl -X POST "<メモしておいたAmazon API Gateway のURL>/pets/?myQueryString=dummy" -H "Content-Type: application/json" -d '{ "type": "dog", "price": "a" }'
message":[instance type (string) does not match any allowed primitive type (allowed: [\"integer\",\"number\"])]}
必要なキー( この例では price )がない場合
curl -X POST "<メモしておいたAmazon API Gateway のURL>/pets/?myQueryString=dummy" -H "Content-Type: application/json" -d '{ "type": "dog" }'
"errors": [
{
"key": "Pet2.price",
"message": "Missing required field"
}
]
}
今回の所感
これまで Amazon API Gateway のリクエスト検証の機能は触ったことがありましたが、ゲートウェイのレスポンス や $ コンテキスト変数 についてはあまり触ったことがないため、よい気づきを得ることができました。 シンプルに Amazon API Gateway のリクエスト検証を使うだけでなく、さらに一歩進んだ Tips として活用していきたいと思います!
Amazon EKS に Container Insights を導入する手順をまとめてみた
Amazon EKS には、Amazon CloudWatch Container Insights (以降、Container Insights )を導入できます。 Container Insights を導入すると、Amazon EKS クラスターやノード、Pod などといった単位でメトリクスを収集し、Amazon CloudWatch アラームを設定できます。またログを収集して Amazon CloudWatch Logs で参照・分析することもできるので、AWS に慣れた人には Amazon EKS のモニタリングやロギングを行う仕組みとして取り組みやすいのではないでしょうか。
Amazon EKS クラスターに Container Insights を導入する手順は下記の AWS のドキュメントに記載されています。
ただこのドキュメントに目を通していて、個人的に「おや?」と思いました。 というのも、メトリクスやログを収集する Agent に Amazon CloudWatch へのアクセスを許可するという重要な部分の設定については他のドキュメントを読んで実施してね、という流れになっているからです。
個人的には、何かを操作する手順をドキュメントに記載するときには、そのページに必要な説明や手順をすべて掲載し、読者は 1つのページを上から下に読めば必要な手順を理解・実行できるようにすべきと思っています。 なので、自分のメモ用に、もしくは他の人への説明用に、具体的な手順をまとめておこうと思い立ちました。
なお、今回まとめた手順は、2023年4月時点の検証に基づいています。 Amazon EKS クラスターと、Amazon EC2 インスタンスを使用するマネージドノードグループも作成済です。また、メトリクスやログを収集する Agent として CloudWatch Agent と Fluent Bit の Agent を使用する前提とします。
目次
- Agent への Amazon CloudWatch へのアクセスの許可について
- 手順 1. クイックスタートセットアップの実施
- 手順 2. IRSA(IAM Roles for Service Accounts)による既存の Service Accountのオーバーライド
- 手順 3. 動作確認
- 今回の所感
Agent への Amazon CloudWatch へのアクセスの許可について
Amazon EKS では、 CloudWatch Agent と Fluent Bit の Agent は Kubernetes の DaemonSet で管理される Pod として実行されます。これらの Agentに Amazon CloudWatch へのアクセスを許可する方法は 2種類です。 どちらも AWS IAM の管理ポリシーである CloudWatchAgentServerPolicy を設定した IAM ロールを使用しますが、その IAM ロールの適用方法が異なります。
1. ノードである EC2 インスタンスに IAM のロールを設定する。
この方法は設定自体はシンプルですが、Agent 以外の Pod にも Amazon CloudWatch へのアクセスを許可してしまうことになります。これは最小権限の原則の観点から望ましくありません。
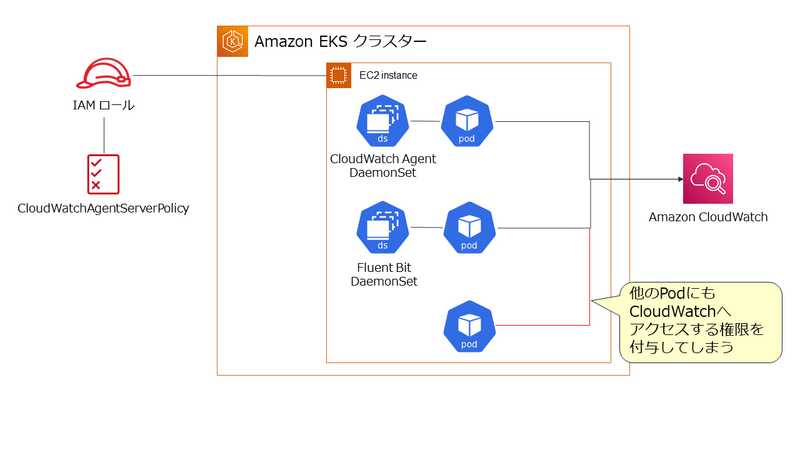
2. Agent の Pod に IAM ロール と関連付けた Service Account を設定する。
この方法の場合、Service Account を設定した Pod だけに Amazon CloudWatch へのアクセスを許可できます。よって今回は、こちらの方法を使用する前提とします。

手順 1. クイックスタートセットアップの実施
この手順は、次のドキュメント通りに実施することで完了できます。
下記は、クラスター名が test-cluster という東京リージョンの Amazon EKS クラスターにクイックスタートセットアップを実施する例です。
ClusterName=test-cluster RegionName=ap-northeast-1 FluentBitHttpPort='2020' FluentBitReadFromHead='Off' [[ ${FluentBitReadFromHead} = 'On' ]] && FluentBitReadFromTail='Off'|| FluentBitReadFromTail='On' [[ -z ${FluentBitHttpPort} ]] && FluentBitHttpServer='Off' || FluentBitHttpServer='On' curl https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml | sed 's/{{cluster_name}}/'${ClusterName}'/;s/{{region_name}}/'${RegionName}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl apply -f -
この手順により amazon-cloudwatch という名前の Namespace が作成され、主要なオブジェクトが作成されます。
Agent となる Pod の起動を次のコマンドで確認します。
kubectl get pods -n amazon-cloudwatch
Pod は DaemonSet で管理されているので、ノード数分の Pod が表示されれば OK です。
NAME READY STATUS RESTARTS AGE cloudwatch-agent-5b4hb 1/1 Running 0 2m22s cloudwatch-agent-6n5qc 1/1 Running 0 2m22s fluent-bit-d2gfh 1/1 Running 0 2m22s fluent-bit-hncw9 1/1 Running 0 2m22s
手順 2. IRSA(IAM Roles for Service Accounts)による既存の Service Accountのオーバーライド
次に Agent の Pod に Amazon CloudWatch へのアクセスを許可します。
手順 1. が完了した段階で、CloudWatch Agent の Pod には、cloudwatch-agent という Service Accountが、Fluent Bit の Agent には fluent-bit という Service Account が設定されています。
これらの Service Account に、AWS IAM のロールを関連付ける必要があります。 これは、Amazon EKS でサポートされている IRSA(IAM Roles for Service Accounts) という仕組みを使用することで実現できます。
IRSA を使用するには、まず Amazon EKS クラスターの OpenID Connect プロバイダ (OIDC プロバイダ)を AWS IAM に登録します。 これは次のコマンドにて行えますが、クラスター毎に 1 回実施すれば OK です。
eksctl utils associate-iam-oidc-provider --cluster ${ClusterName} --approve
次に Service Account cloudwatch-agent に CloudWatchAgentServerPolicy を設定した IAM ロールを設定します。
eksctl create iamserviceaccount \ --name cloudwatch-agent \ --namespace amazon-cloudwatch \ --role-name ${ClusterName}-cloudwatch-agent-role \ --cluster ${ClusterName} \ --attach-policy-arn arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy \ --override-existing-serviceaccounts \ --approve
Service Account fluent-bit にも同じように CloudWatchAgentServerPolicy を設定した IAM ロールを設定します。
eksctl create iamserviceaccount \ --name fluent-bit \ --namespace amazon-cloudwatch \ --role-name ${ClusterName}-fluent-bit-role \ --cluster ${ClusterName} \ --attach-policy-arn arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy \ --override-existing-serviceaccounts \ --approve
ここで ポイント になるのは、7 行目の --override-existing-serviceaccounts オプションです。
手順 1. のクイックスタートセットアップですでに Service Account は作成されています。--override-existing-serviceaccounts オプションを付けることで作成済の Service Account に AWS IAM のロールを設定できます。
この後、Agent の Pod の再起動が必要になるので、DaemonSet をリスタートしておきましょう。
kubectl rollout restart ds cloudwatch-agent -n amazon-cloudwatch kubectl rollout restart ds fluent-bit -n amazon-cloudwatch
手順 3. 動作確認
この後 1~2分ほど待って、Container Insights が使用できるか確認してみます。
AWS マネジメントコンソール で Amazon CloudWatch のページ左側のメニューから [ インサイト ] - [ Container Insights ] を選択します。 下図では、[ パフォーマンスのモニタリング ] で test-cluster のメトリクスの表示を確認しています。

他にも、様々な切り口でメトリクスを確認してみて下さい。
また、ログの収集も確認してみます。Amazon CloudWatch のページ左側のメニューから [ ログ ] - [ ロググループ ] を選択します。 下図では、test-cluster のロググループが作成されていることを確認しています。

今回の所感
今回紹介した手順でポイントになるのは、手順 2. です。手順 2. については、AWS の Container Insights のドキュメントには具体的な記載がありません。ただ、手順 2.の実施においては、Kubernetes の RBAC や Service Account、Amazon EKS の IRSA の仕組みの理解が必要になるので、AWS のドキュメントのように他のページで確認して下さい、という記述になるのは、仕方がない部分もあるのかもしれません。
とはいうものの、Container Insights を導入する具体的な手順は明確に示しておくことは必要かと思いますので、この記事でそれをまとめることができてよかったと思ってます!
kubesec で AWS KMS のキーを使って Secret を暗号化・復号してみる
Kubernetes の Secret リソースでマニフェストで作成するとき、Secret として秘匿したいデータを Base 64 でエンコードして指定します。
ただ、Base 64は単なるエンコードなので、そのままでマニフェストを保存することは、セキュリティ上避けたいですよね。そのため、Secret のデータの暗号化や復号を行う kubesec や SealedSecrets などのツールが提供されています。
これまで「kubesecとか使えば暗号化や復号はできるよね」と頭でしか理解してなかったんですが、kubesec を実際に触ってみようと思い立ったので、そのときのメモをここに書いておきたいと思います。
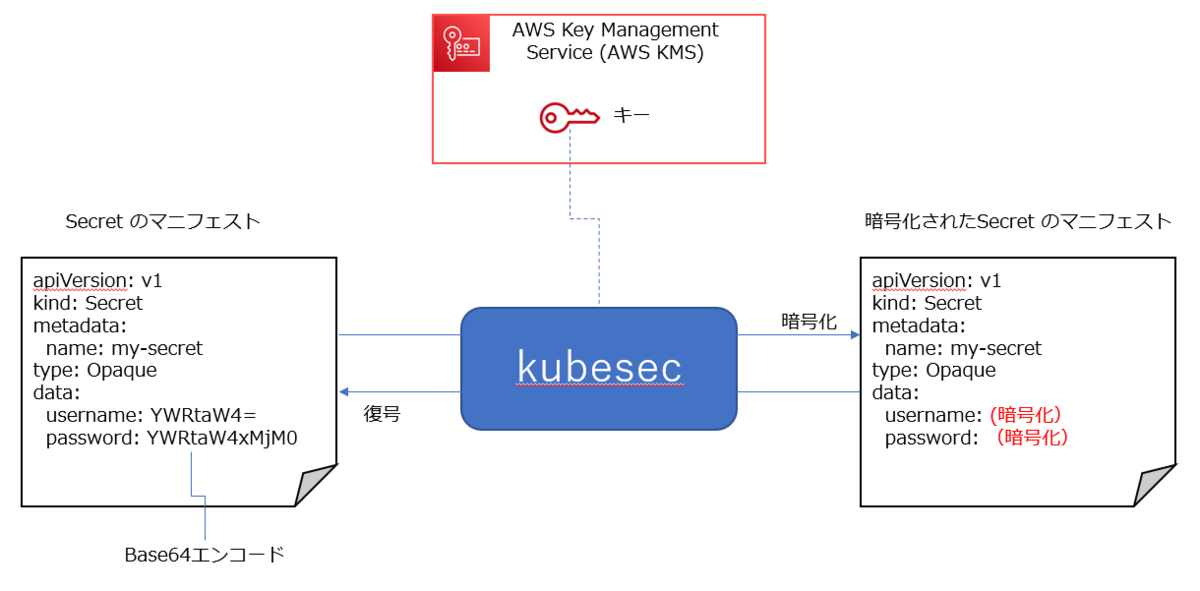
なお、今回は 下図のように AWS KMS のキーを使用して暗号化・復号する前提とします。
目次
1. AWS KMS のキーの作成
今回、暗号化や復号に必要なキーを AWS KMS を使用して生成しますので、AWS KMSにアクセスできるようにする必要があります。そのため、使用しているAWS IAM のユーザーまたはロールに、AWS IAM のポリシーを設定します。
今回は、使用している AWS IAM のユーザーに AWSKeyManagementServicePowerUser という管理ポリシーを設定する前提としますが、実際に使用する際は最小権限の原則に基づいて設定して下さい。
AWS KMS を操作する上での AWS IAM のポリシーについては次のドキュメントに例があるので参考にしましょう。
AWS KMS キーの作成は AWS マネジメントコンソールからでも行えますが、今回は AWS CLI のコマンドで作成してみます。
aws kms create-key --description "demo for kubesec"
--description オプションで指定する文字列の値は任意です。
キー作成が完了すると、次のような 出力が表示されるので、この中の Arn の値をメモしておきましょう。
{ "KeyMetadata": { "AWSAccountId": "000000000000", "KeyId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "Arn": "arn:aws:kms:ap-northeast-1:000000000000:key/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "CreationDate": "2023-03-25T09:31:57.061000+00:00", "Enabled": true, "Description": "demo for kubesec", "KeyUsage": "ENCRYPT_DECRYPT", "KeyState": "Enabled", "Origin": "AWS_KMS", "KeyManager": "CUSTOMER", "CustomerMasterKeySpec": "SYMMETRIC_DEFAULT", "KeySpec": "SYMMETRIC_DEFAULT", "EncryptionAlgorithms": [ "SYMMETRIC_DEFAULT" ], "MultiRegion": false } }
2. kubesec のインストール
kubesec のインストール方法などについては、下記を参考にしました。
今回は Linux の環境にインストールしますので、次のコマンドを実行します。
curl -sSL https://github.com/shyiko/kubesec/releases/download/0.9.2/kubesec-0.9.2-linux-amd64 \ -o kubesec && chmod a+x kubesec && sudo mv kubesec /usr/local/bin/
その後、確認のため次のコマンドを実行します。
kubesec --version
0.9.2 のようにバージョン ID が出力されれば OK です。
3. Secret のマニフェストの暗号化
ではいよいよ、Secret のマニフェストを暗号化してみます。
今回は、次の内容を secret.yaml として保存して使用します。
apiVersion: v1 kind: Secret metadata: name: my-secret type: Opaque data: username: YWRtaW4= password: YWRtaW4xMjM0
kubesec で AWS KMS のキーを使用して暗号化するときは、--key オプションに キーの ARN を指定します。
次の例では、secret.yaml を暗号化したマニフェストを 標準出力 に表示します。
kubesec encrypt --key=aws:<ARN of AWS KMS key> secret.yaml
実行すると次のような内容が表示されます。
apiVersion: v1 data: password: (暗号化された値) username: (暗号化された値) kind: Secret metadata: name: my-secret type: Opaque # kubesec:v:3 # kubesec:aws:arn:aws:kms:ap-northeast-1:0000000000001:key/xxxxx # kubesec:mac:xxxxx
data: 以下の username や password の値が暗号化されていることを確認できました。
また、-i オプションを付けると、指定したマニフェストファイルに暗号化した値を直接変更します。
kubesec encrypt -i --key=aws:<ARN of AWS KMS key> secret.yaml
上記を実行すると、secret.yaml の data: 以下の username や password の値が直接変更されたことが確認できます。
4. Secret のマニフェストの復号
暗号化されたマニフェストを復号する場合は、decrypt を使用します。
次の例では、暗号化されている secret.yaml を復号して標準出力に表示します。
kubesec decrypt secret.yaml
実行すると次のような内容が表示されます。
apiVersion: v1 data: password: YWRtaW4xMjM0 username: YWRtaW4= kind: Secret metadata: name: my-secret type: Opaque
また、暗号化と同じように -i オプションを付けると、暗号化されたファイルに復号した値を直接変更します。
kubesec decrypt -i secret.yaml
上記を実行すると、暗号化された secret.yaml の data: 以下の username や password の値が直接変更されたことが確認できます。
5.今回の所感
kubesec と AWS KMS のキーを使用して Secret の値を暗号化・復号する仕組み自体は、とてもシンプルです。
GitOps のように Kubernetes のマニフェストを Git リポジトリに保存・管理してデプロイする場合は、Secret は kubesec のようなツールを使い、暗号化して保存し、Kubernetes クラスタに適用する際に自動的に復号するような仕組みを考えたいと思いました。
一方で、AWS KMS のキーの権限の管理は厳格に行う必要があります。キーを作成できる権限、キーを使用して暗号化・復号できる権限などは IAMのユーザーまたはロールごとに最小権限の原則に基づいて設定する必要があるので、その管理や運用を漏れなく実施する必要性を強く感じました。
今回は 暗号化・復号のツールとして kubesec を使ってみましたが、他にも SealedSecrets といった便利なツールもあるので、また別の機会に触ってみたいです!
今さらながら GitHub Actions をさわってみる: (AWS SAM のデプロイ編)
前回の記事では、GitHub Actions のワークフローから AWS アカウントへのアクセス方法を確認しました。
その方法を用いて、今回は AWS アカウントへサーバーレスアプリケーションのビルドとデプロイを行ってみます。
アプリケーションは、Amazon API Gateway と AWS Lambda を使用して HelloWorld メッセージを返すだけのシンプルなものです。
このようなシンプルなものであれば、AWS SAM ( Serverless Application Model ) の事前定義済のアプリケーションテンプレートを用いるとすぐに作成することができます。
この AWS SAM を使用してデプロイを行うワークフローを作成し、実際にデプロイするまでの手順を記載していきます。
なお、この記事の内容は 2023 年 3月時点で検証した内容に基づいています。また記事の中の AWS アカウント IDはすべて 0 で表記しています。
手順の概要
- GitHub でリポジトリを作成する
- デプロイ先の AWS アカウントの IAM で ID プロバイダの設定と IAM ロールの作成を行う
- GitHub でリポジトリで IAM ロールの ARN の値を Secret として保存する
- AWS SAM のリソースを作成する
- GitHub Actions のワークフローの YAML ファイルを作成する
- リポジトリに push してワークフローの実行結果を確認する
1. GitHub でリポジトリを作成する
任意の名前でリポジトリを作成します。
この名前は、次の IAM ロール作成時に必要になります。
2. デプロイ先の AWS アカウントの IAM で ID プロバイダの設定と IAM ロールの作成を行う
ID プロバイダの設定については前回の記事(下記)で説明している手順通りです。一回、設定していれば改めて設定する必要はありません。
IAM ロールの作成では、今回は ワークフローから AWS SAM CLI のコマンドを実行してデプロイを行いますので、そのために必要なポリシーを設定した IAM ロールを作成します。
これも前回の記事の内容を参考に行えます。
ただし、許可ポリシーは下記のように AWS SAM によるデプロイを許可する内容にします。
許可ポリシーの例は、以前に紹介した記事(下記)にありますので、これを利用します。
また、信頼ポリシーは使用するリポジトリに合わせて下記のように設定します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::000000000000:oidc-provider/token.actions.githubusercontent.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "token.actions.githubusercontent.com:aud": "sts.amazonaws.com" }, "StringLike": { "token.actions.githubusercontent.com:sub": "repo:<GitHubユーザーID>/<GitHubリポジトリ名>:*" } } } ] }
IAM ロールを作成したら、ARN の値をメモしておきます。これは次の手順で使用します。
3. GitHub でリポジトリで IAM ロールの ARN の値を Secret として保存する
前の手順でメモしておいた IAM ロールの値を、GitHub リポジトリの Secretとして保存します。
この手順も前回の記事を参考に行えます。
4. AWS SAM のリソースを作成する
AWS SAM CLI をインストールしている環境で、初期化を行います。
利用する AWS SAM CLI のバージョンは、 1.76.0 以降を前提としています。
sam --version SAM CLI, version 1.76.0
今回は、Python 3.8 をラインタイムとして指定します。X-Ray トレースや Amazon CloudWatch Application Insights のモニタリング を無効化する前提です。
--name は、任意の名前を設定します。
sam init --runtime python3.8 \ --app-template hello-world \ --name actions-aws-sam \ --no-tracing \ --no-application-insights
--name で指定したフォルダが作成されるので、そこに移動し、git init と git remote add を実行します。
cd actions-aws-sam git init git remote add origin https://github.com/<GitHubユーザーID>/<GitHubリポジトリ名.git
この段階で、AWS SAM CLI により HelloWorld メッセージを出力する Python の AWS Lambda 関数と、それと統合した Amazon API Gateway の API のリソースは揃っています。
ただ 今回は、GitHub Actions のワークフローからデプロイする際に必要な AWS SAM の細かいパラメータは、ファイルに保存しておくようにしたいと思います。
そのため、--name で指定したフォルダ に、samconfig.toml というファイルを作成し、下記の内容を指定して保存します。
version=0.1 [default.deploy.parameters] stack_name = "<任意のスタック名>" s3_bucket = "<AWS SAM のリソースをアップロードする S3バケット名>" s3_prefix = "<上記 S3 バケットのフォルダ名>" confirm_changeset = false capabilities = "CAPABILITY_IAM"
s3_bucket で指定するバケットはあらかじめ作成しておきましょう。s3_prefix で指定した名前は S3 バケットのフォルダになり、任意の名前を設定できますがあらかじめフォルダを作成しておく必要はありません。
これで AWS SAM のリソースの準備は完了です。
5. GitHub Actions のワークフローの YAML ファイルを作成する
では、AWS SAM リソースをデプロイするワークフローの YAML を 作成します。
--name で指定したフォルダ の下に .github/workflows フォルダ作成して、そこに 任意の名前の YAML ファイルを作成します。
内容については、下記のドキュメントにサンプルがあるので、これを活用します。
ただし、このサンプルでは OIDC を使用せず Secret に AWS アカウントの認証情報を指定していますので、この部分は OIDC を使うように変更します。
また、--no-confirm-changeset オプションは すでに samconfig.toml 内で指定しているので、このオプションの指定も削除します。
on: push: branches: - main env: AWS_REGION : "ap-northeast-1" # permission can be added at job level or workflow level permissions: id-token: write # This is required for requesting the JWT contents: read # This is required for actions/checkout jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - uses: actions/setup-python@v3 - uses: aws-actions/setup-sam@v2 - uses: aws-actions/configure-aws-credentials@v1 with: role-to-assume: ${{ secrets.AWS_ROLE_ARN }} role-session-name: samplerolesession aws-region: ${{ env.AWS_REGION }} - run: sam build --use-container - run: sam deploy --no-fail-on-empty-changeset
ポイントは 17 行目の - uses: aws-actions/setup-sam@v2 ですね。 AWS SAM を使用するためのアクションがあるので、それを使用することで ワークフローから AWS SAM CLI を実行できます。
これでワークフローの準備も完了しました。
6. リポジトリに push してワークフローの実行結果を確認する
では、いよいよ リポジトリに push してワークフローを実行します。
git add. git commit -m "commit sam resource" git push -u origin main
無事に ワークフローが完了していれば、下図の赤枠の Run sam deploy のステップを展開表示してみましょう
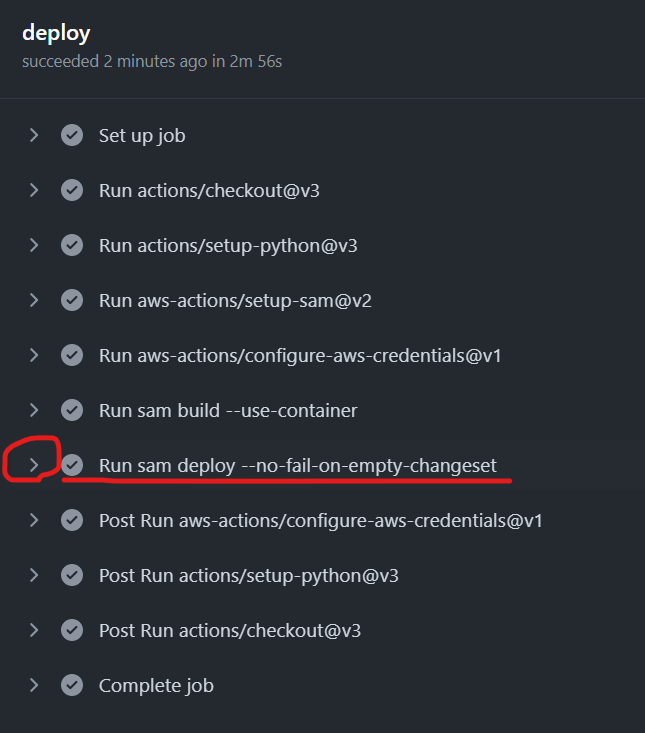
AWS SAM による deploy の結果として、Outputs セクションが表示されています。
CloudFormation outputs from deployed stack ---------------------------------------------------------------------------------- Outputs ---------------------------------------------------------------------------------- Key HelloWorldFunctionIamRole Description Implicit IAM Role created for Hello World function Value arn:aws:iam::***:role/actions-aws-sam-stack- HelloWorldFunctionRole-WCPOUUNE5S2W Key HelloWorldApi Description API Gateway endpoint URL for Prod stage for Hello World function Value https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/
その中の Key が HelloWorldApi の Value のURL の値をコピーして Web ブラウザでアクセスします。
結果、下記のようなメッセージが表示されればアプリケーションが正常にデプロイされています。
{"message": "hello world"}
今回の所感
今回で GitHub Actions のワークフローを使用し、AWS SAM によるアプリケーションのデプロイができました。
知識ゼロのところから、下記の記事を書き連ね、コツコツと学んで積み上げてきた知識を組み合わせて実現できたと感じています。
今回は GitHub Actions 側の視点から AWS SAM を使用する方法を確認しましたが、AWS SAM には、実は GitHub Actions のワークフローを自動生成する機能があります。
これも一応触ってみたので、また別の機会に記事で紹介したいと思います。


今さらながら GitHub Actions をさわってみる: (AWS へのアクセス編)
前回、前々回に引き続き、GitHub Actions のワークフローを触っていきます。
今回は、ワークフローから AWS アカウントへアクセスする方法を整理しつつ、実際にアクセスを試していきます。
最終的には、GitHub Actions を使用して アプリケーションをビルドし、AWS アカウントにデプロイするワークフローを作成しようと思っているので、AWS アカウントへのアクセス方法の理解はその事前準備となります。
なお、この記事は 2023 年 3 月時点で検証した内容に基づいて記載しています。
目次
- AWS アカウントへアクセスする方法の整理
- 方法 1. AWS のアクセスキー ID やシークレットアクセスキー を GitHub の Secret として保存してワークフローから使用する方法
- 方法 2. GitHub の OpenID Connect (OIDC) プロバイダを使用し、AWS アカウントにアクセスできるトークンを使用する方法
- 今回の所感
AWS アカウントへアクセスする方法の整理
まず、GitHub のドキュメントを参照して AWS アカウントへのアクセス方法を整理してみましたが、基本的には下記の 2パターンがあるようです。
- AWS のアクセスキー ID やシークレットアクセスキー を GitHub の Secret として保存してワークフローから使用する方法
- GitHub の OpenID Connect (OIDC) プロバイダを使用し、AWS アカウントにアクセスできるトークンを使用する方法
セキュリティの観点から上記 2 の方法が推奨 のようですが、とりあえず両方の方法を試します。
方法 1. AWS のアクセスキー ID やシークレットアクセスキー を GitHub の Secret として保存してワークフローから使用する方法
GitHub の Secret については、次のドキュメントに記載があります。AWS アカウントのアクセスキーなど、秘匿すべき認証情報を保存する用途に使えそうです。
この Secret を使ったワークフローのイメージ図を描いてみました。
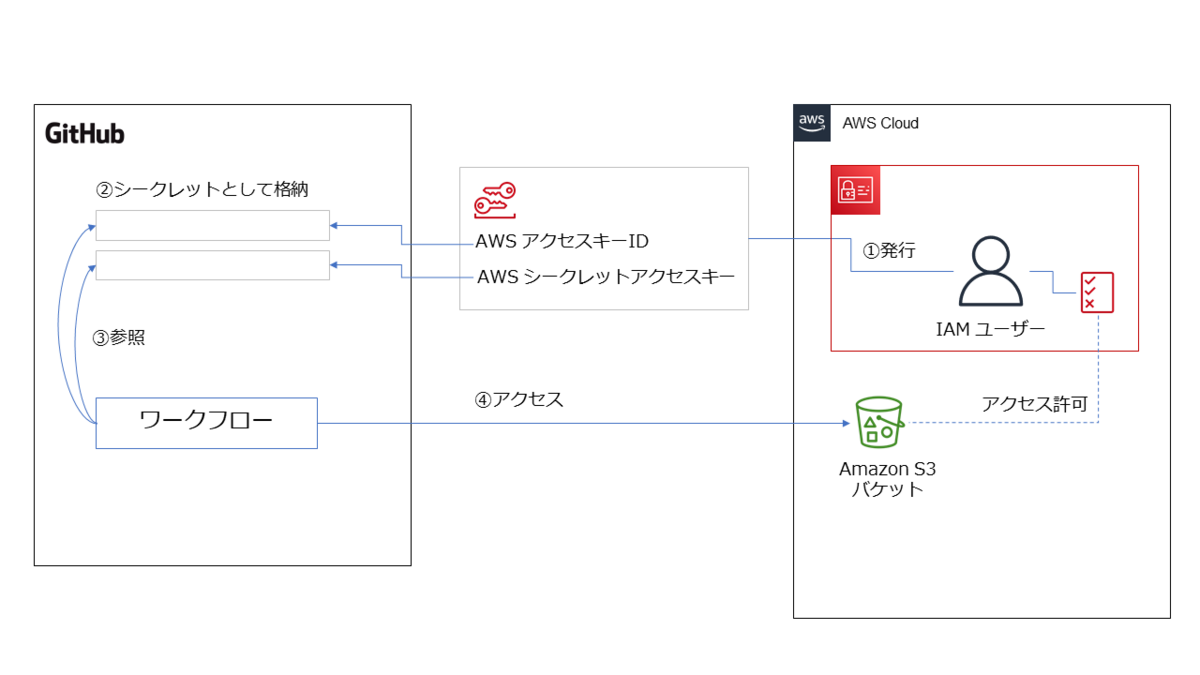
上図のように、仕組みとしてはシンプルでわかりやすいですよね。
ただし、前述のようにこの方法はお薦めできません。
Secret という仕組みはあるにせよ、永続的に使用できるアクセスキー ID を発行してそれを一つの場所にずっと保管することはセキュリティ面での懸念があるからです。
後で説明する 2番目の方法のように、必要なタイミングで一時的に使用できるトークンを発行して使用する 方が望ましいのですが、今回は勉強の一環として試してみました。
まず、AWS アカウントで 下記の IAM ポリシーを作成します。(ここでは便宜上、s3-listAllMyBuckets-policy と名付けます。)
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" } ] }
次に IAM ユーザーを作成して作成した s3-listAllMyBuckets-policy を設定し、アクセスキーID とシークレットアクセスキーを発行します。
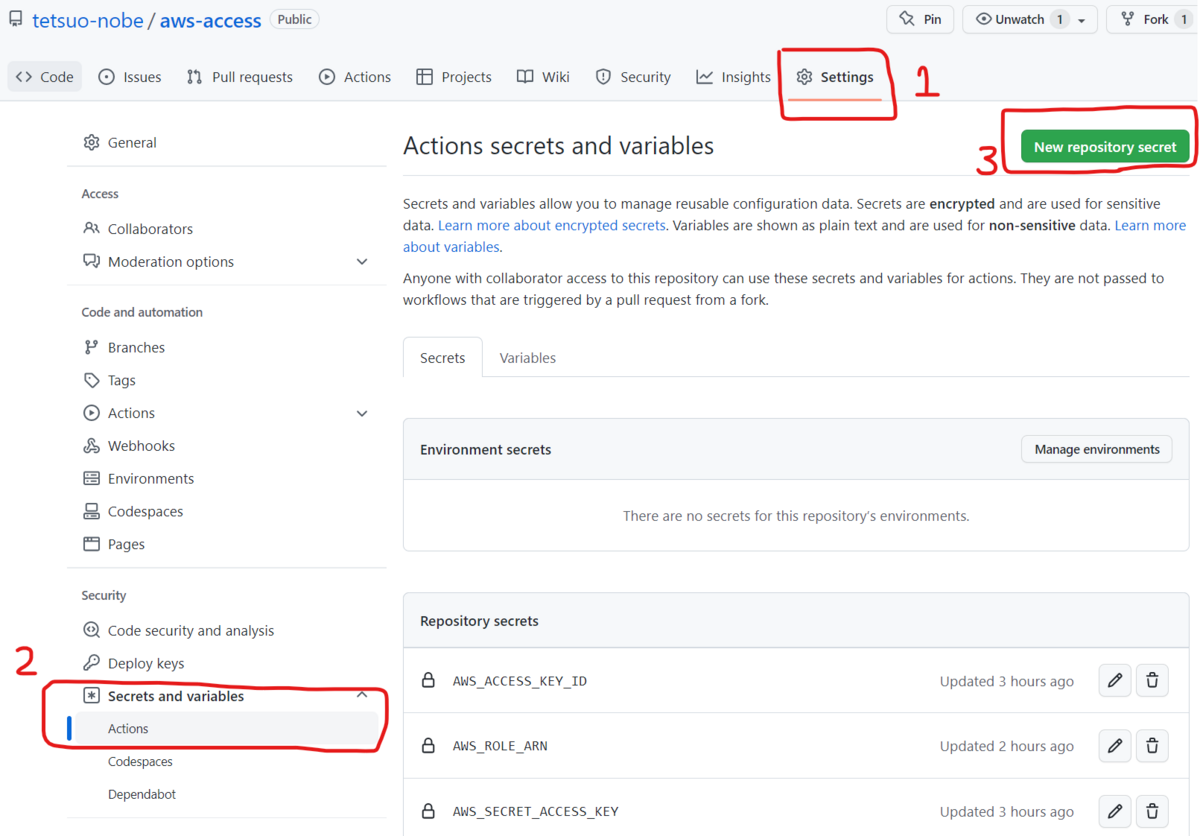
そのアクセスキーID とシークレットアクセスキーを GitHub の Secret として設定します。
設定方法は、Web ブラウザからでも GitHub CLI からでも可能です。
Web ブラウザの場合は、対象リポジトリのページから [ Settings ] タブ、左側のメニューで [ Secrets and variables ] - [ Actions ] を選択して、右上の [ New repository secret ] を選択して設定します。設定した Secret の名前は後でワークフローの中で指定します。
では次にワークフローの YAML ファイルを作ります。
今回は、下記のドキュメントを参考にしました。
ただし、今回は AWS アカウントへのアクセスを試すのが目的なので、 AWS SAM は使用せず、AWS CLI のコマンドを aws s3 ls を発行するだけのシンプルなワークフロー(下記)に変えることにしました。
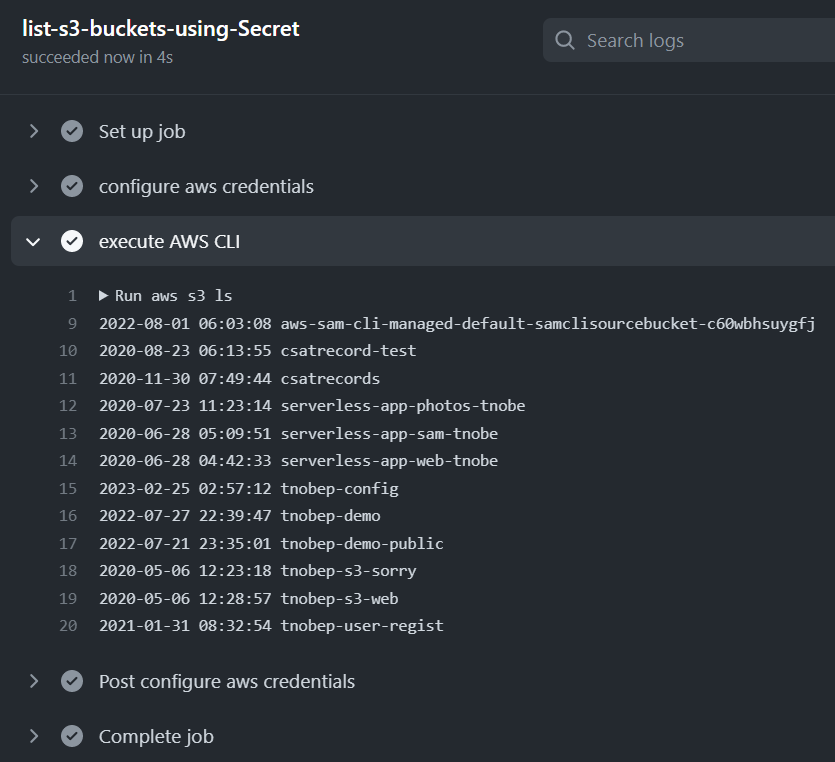
aws s3 ls が正常に実行され、Amazon S3 バケットの一覧が表示されれば AWS アカウントへアクセスできたという確認になります。
name: AWS access using secrets in GitHub on: push: branches: - main jobs: list-s3-buckets-using-Secret: runs-on: ubuntu-latest steps: - name: configure aws credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: execute AWS CLI run: aws s3 ls
上記の YAML でポイントになるのは、10 行目から 15 行目のステップです。
aws-actions/configure-aws-credentials というアクションを用いることで、AWS アカウントのアクセスするための認証情報をセットして、AWS CLI も利用できるようになります。
そのため、次の 16 行目からのステップでは、すぐに AWS CLI で aws s3 ls を実行しています。
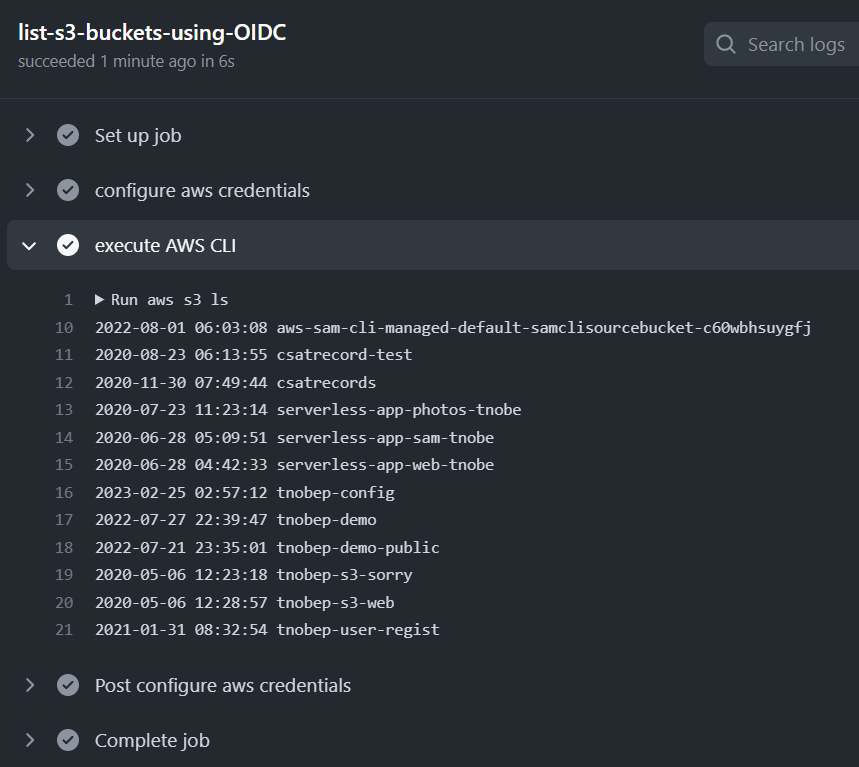
このワークフローを実行すると、正常に Amazon S3 バケットの一覧が表示されました。
GitHub のワークフローから AWS アカウントへアクセスを確認できたわけです。
方法 2. GitHub の OpenID Connect (OIDC) プロバイダを使用し、AWS アカウントにアクセスできるトークンを使用する方法
ただ、(繰り返しになりますが)前述の方法 1 よりもお薦めなのが この OIDC を使用する方法です。
下図は、この仕組みを図にしてみたものです。
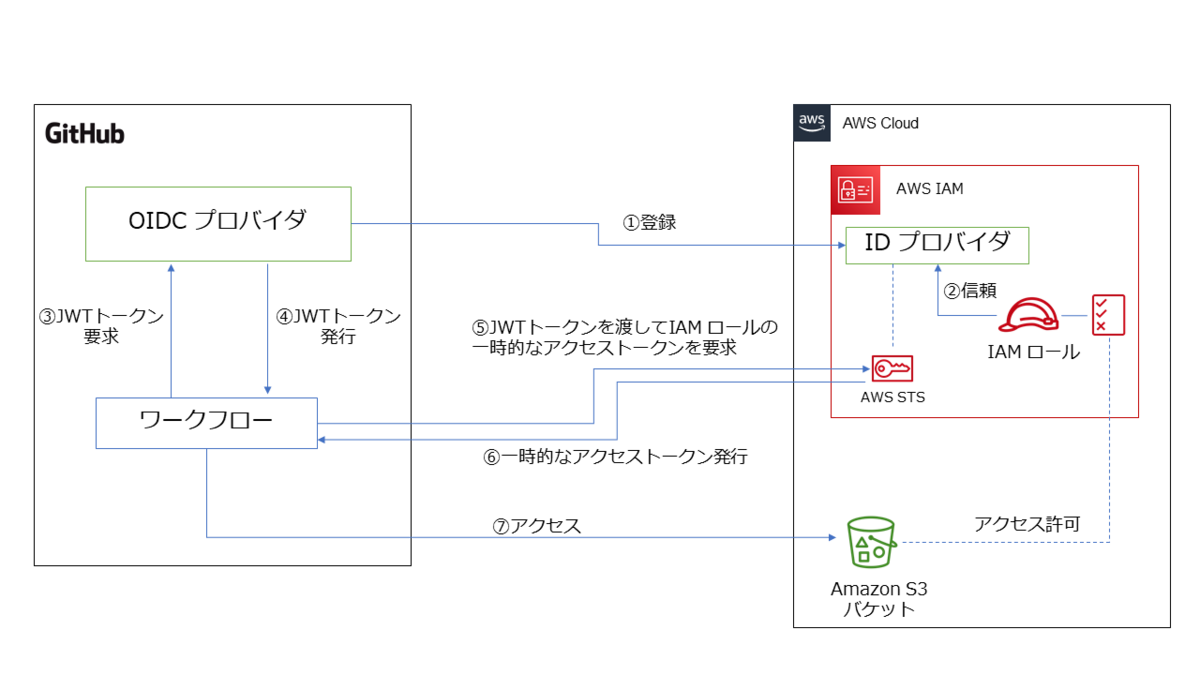
方法 1 よりは複雑に感じるかもしれませんが、要するに AWS アカウントがGitHub の OIDC プロバイダを信頼する ことで、その OIDC プロバイダが発行した JWT (ジョット)トークンがあれば AWS の IAM ロールを使用できるようにする仕組みです。
GitHub の OIDC プロバイダが発行するJWTトークンがあれば、AWS 側からアクセストークンが発行されるので、そのアクセストークンで AWS アカウントにアクセスすれば、事前に設定した IAM ロールに紐づく IAM ポリシーの権限の範囲で AWS リソースを操作できます。
この仕組みを実現するには、まず GitHub の OIDC プロバイダを AWS アカウント側に登録します。
この方法は、GitHub の下記のドキュメントにも記載されています。
この登録ですが、AWS マネジメントコンソールでも AWS CLI でも行えますが、個人的には AWS マネジメントコンソール を使う方が簡単 でお薦めです。
その理由は、OIDC プロバイダ登録時には TLS 証明書のサムプリント ( thumbprint ) の値が必要なのですが、AWS CLI の場合は、事前に様々なコマンドを発行したり編集したりしてそのサムプリントの値を自分で導出したうえでパラメータに指定する必要があるのに対して、AWS マネジメントコンソール ではサムプリントの値は自動的に取得、設定可能なためです。
参考として下記のドキュメントを紹介しますので、興味があれば実施してみて下さい。
ここではシンプルに設定できる AWS マネジメントコンソールを使用する方法を紹介します。
まず IAM のコンソールの左側のメニューから [ アクセス管理 ] - [ ID プロバイダ ] を選択し、右側にある [ プロバイダを追加 ] を選択します。
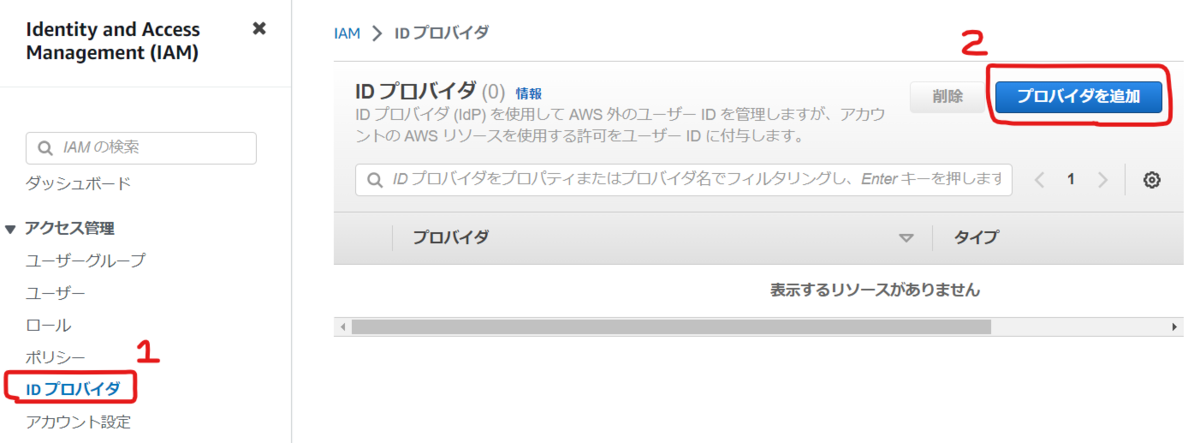
[ プロバイダのタイプ ] に [ OpenID Connect ] を選択します。
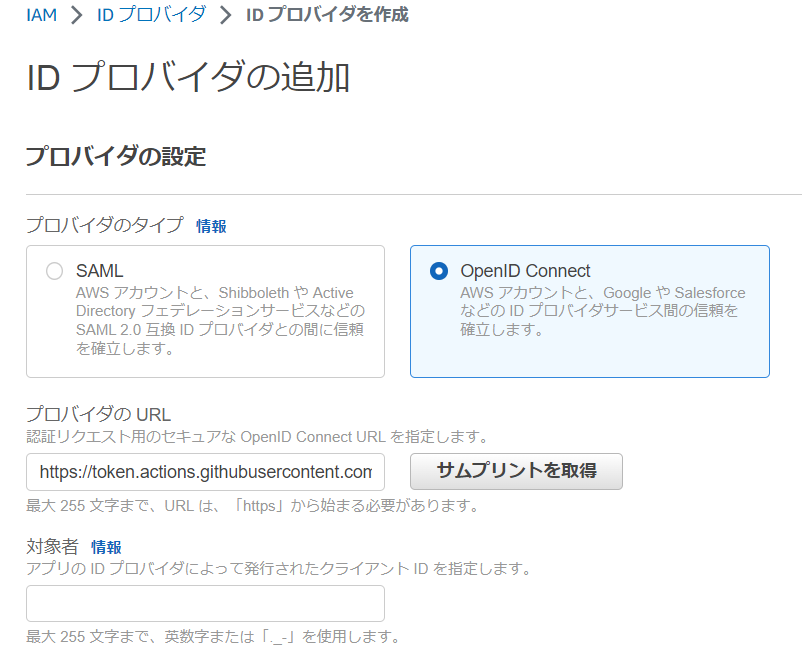
[ プロバイダの URL ] に https://token.actions.githubusercontent.com を入力して [ サムプリントを取得 ] を選択します。
その後、その下にある [ 対象者 ] に sts.amazonaws.com と入力して、ページ右下にある [ プロバイダを追加 ] をクリックします。
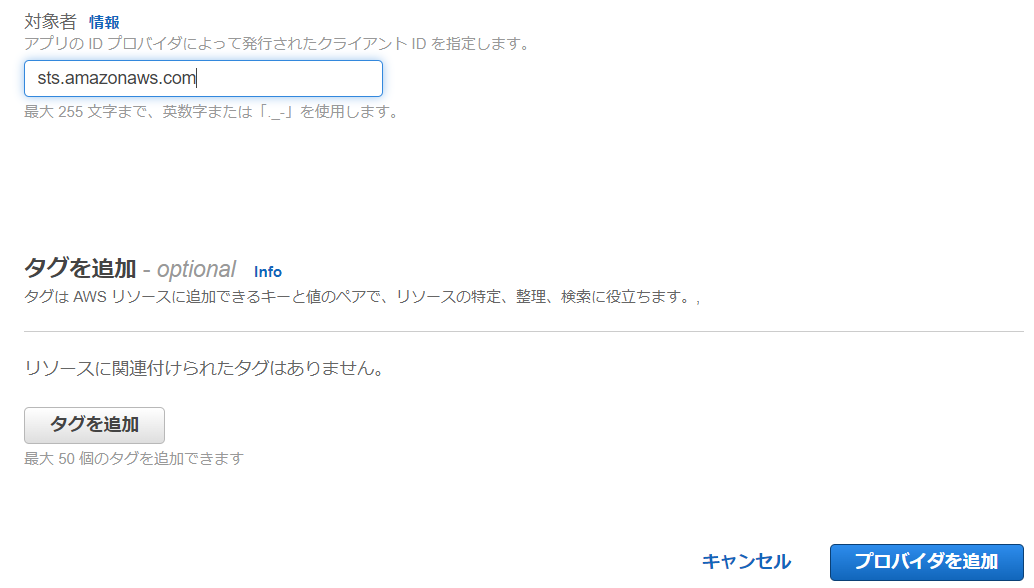
これで OIDC プロバイダの登録は完了です。
次に、この OIDC プロバイダを信頼する IAM ロールを作成します。
AWS マネジメントコンソールで作成する場合は、IAM のページから左側のメニューで[ アクセス管理 ] - [ ロール ] を選択し、右側にある [ ロールを作成 ] を選択します。
[ 信頼されたエンティティを選択 ] のページで [ 信頼されたエンティティタイプ ] に [ ウェブアイデンティティ ] を選択します。
[ アイデンティティプロバイダー ] に [ token.actions.githubusercontent.com ] を選択します。
[ Audience ] に [ sts.amazonaws.com ] を選択して、[ 次へ ] を選択します。

その後は、方法 1 で作成した s3-listAllMyBuckets-policy の IAM ポリシー(下記)を許可ポリシーとして設定します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" } ] }
ロールの名前は任意の値を入力してロールを作成します。今回の例では、s3-listAllMyBuckets-role とします。
これでロールは作成したのですが、ロールの信頼ポリシーで GitHub のリポジトリを限定するように条件を追加しておきましょう。
作成したロールの名前をクリックして、[ 信頼関係 ] タブを選択して、[ 信頼ポリシーを編集 ] を選択します。
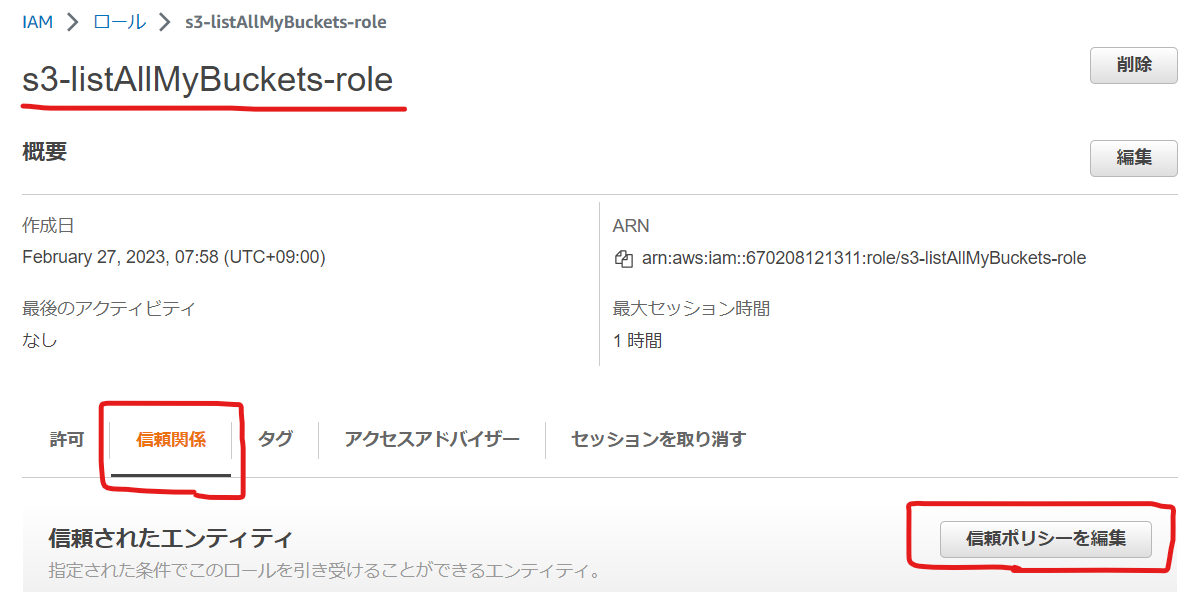
そしてポリシーの Condition に下記を追加します。
これは、GitHub の特定のリポジトリだけを対象に IAM ロールの引き受けを可能にするための条件設定です。
セキュリティの面から IAM ロールを引き受けを認める範囲を限定する必要があるため、必ず設定して下さい。
"StringLike": {
"token.actions.githubusercontent.com:sub": "repo:<GitHubのユーザーID>/<GitHubのリポジトリ名>:*"
}
下記は、条件を追記した信頼ポリシー全体の例です。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::111111111111:oidc-provider/token.actions.githubusercontent.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "token.actions.githubusercontent.com:aud": "sts.amazonaws.com" }, "StringLike": { "token.actions.githubusercontent.com:sub": "repo:tetsuo-nobe/aws-access:*" } } } ] }
これで AWS アカウント側の事前準備は終わったので、GitHub のワークフローを作成していきます。
下記のドキュメントにワークフローの例があるので、これを参考に方法 1 と同じく AWS CLI で aws s3 ls を実行するワークフローを作成します。
ただ、上記のドキュメントの例をみて、おや❓ と感じました。
ワークフローの YAML には、引き受ける IAM ロールの ARN を指定する必要がありますが、この例では、ワークフローが引き受ける IAM ロールの ARN の値を YAML ファイルにそのまま記述しています。
しかし、ARN には AWS アカウント ID の 12桁の数字も含まれるので、YAML ファイルにそのまま記述するのは避けたいですよね。
ということで、IAM ロールの ARN は GitHub の Secret に保存し、それを参照することにしました。
OIDC の方法を用いれば Secret は使わなくてもいいかなと思っていたのですが、やはり AWS アカウントID は秘匿しておきたいですよね。
結果、完成した ワークフローの YAML が下記です。
name: AWS access using OIDC provider on: push: branches: - main env: AWS_REGION : "ap-northeast-1" # permission can be added at job level or workflow level permissions: id-token: write # This is required for requesting the JWT contents: read # This is required for actions/checkout jobs: list-s3-buckets-using-OIDC: runs-on: ubuntu-latest steps: - name: configure aws credentials uses: aws-actions/configure-aws-credentials@v1 with: role-to-assume: ${{ secrets.AWS_ROLE_ARN }} role-session-name: samplerolesession aws-region: ${{ env.AWS_REGION }} - name: execute AWS CLI run: aws s3 ls
19 行目では、Secret を使って IAM ロールの ARN を取得するようにしています。
実行してみると、下図のように aws s3 ls が正常に実行されたことを確認できました。
今回の所感
今回の記事の中で紹介した OIDC を使用する方法により、 AWS のアクセスキー ID を発行して GitHub 側に保存しなくても AWS アカウントへアクセスできるが確認できました。
この方法を理解できたことで、GitHub Actions を使用して AWS アカウントへ アプリケーション環境を構築するワークフローの作成方法のイメージが大きく膨らんできました!
次回は、今回の記事の内容をベースにしつつ、AWS アカウントへアプリケーション環境を構築するワークフローを作成したいと思います!
今さらながら GitHub Actions をさわってみる: (入門編)
これまで GitHub はリポジトリとしてのみ活用することがほとんどでしたが、GitHub Actions のワークフローを触ってみようと思い至りました。
なぜそう思ったかというと、Amazon CodeCatalyst を触ってみたからです。
Amazon CodeCatalyst を触っていくうちに、「これはどうも GitHub の全体的な機能と似ているんじゃないかな」と個人的な感触を得ました。
Amazon CodeCatalyst のさらなる理解を深めるためには、GitHub の様々な機能を理解しておくのがよいのでは、と思ったわけです。
Amazon CodeCatalyst だけを Dive Deep するのではなく、また、GutHub だけを Dive Deep するのではなく、これら 2 つのサービスを理解し、比較していくことでさらなる理解や知見を深めることができそうだと感じています。
ということで、ひとまず GitHub Actions でワークフローを使って CI/CD 関連の機能を試していきたいと思います。
個人的には CI/CD の環境は、これまでほとんど AWS CodeBuild や AWS CodePipeline を使ってきたのですが、GitHub Actions のワークフローではどんなことができるか、AWS のクラウドのリソースと連携できるのか、などを実際に触って確認してみるつもりです。
今回は、全然知識がない中からのスタートなので、入門編 として簡単なワークフローを動かすところまでやって、その時に気づいたこと、思ったことを書いていきたいと思います!
(なお、この記事の内容は 2023 年 2 月時点で触ってみた結果に基づいています。)
クイックスタートを触ってみる
GitHub Actions を入門する上では、まず下記を試してみるのが良さそうです。
このクイックスタートは、「細かいことはさておき、ひとまず動かしてみよう!」という位置づけのようです。
ふむふむ、GutHub のリポジトリで .github/workflows フォルダをつくって、そこに YAML ファイルを作成すればよさそうです。
ただ、このクイックスタートの 手順は、Web ブラウザで GitHub のページからファイルを編集しているようですが、今回は手元の PC のローカルのリポジトリを編集して、リモートに反映させる形で試していきます。
まずは適当な名前で GitHub のリポジトリを作成して、git clone を実行します。
git clone https://github.com/tetsuo-nobe/test.git
そして .github/workflows フォルダ を作成し、クイックスタートに記載されている通りに github-actions-demo.yml というファイルを作成します。ファイル名は任意ですが、今回はクイックスタート通りにしておきました。
内容は下記です。
name: GitHub Actions Demo run-name: ${{ github.actor }} is testing out GitHub Actions 🚀 on: [push] jobs: Explore-GitHub-Actions: runs-on: ubuntu-latest steps: - run: echo "🎉 The job was automatically triggered by a ${{ github.event_name }} event." - run: echo "🐧 This job is now running on a ${{ runner.os }} server hosted by GitHub!" - run: echo "🔎 The name of your branch is ${{ github.ref }} and your repository is ${{ github.repository }}." - name: Check out repository code uses: actions/checkout@v3 - run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner." - run: echo "🖥️ The workflow is now ready to test your code on the runner." - name: List files in the repository run: | ls ${{ github.workspace }} - run: echo "🍏 This job's status is ${{ job.status }}."
上記がワークフローの内容を示すものですね。ざっとみると、どんなことが記述されているかが何となくわかります。
例えば、name や run-name は名前に関する定義だな、とか、時々出てくる ${{ }} は事前定義済の変数の内容を出力するのだろうな、とか...
さらに、steps: 以下に記載されている内容がワークフローとして実行すべき処理なのだろうな、とか...
run: は OS に対するコマンドっぽいけど、use: actions/checkout@v3 は何か違うようだ... でも、その下の echo コマンドをみると、どうもリポジトリから clone するためのもののようだ... などとボンヤリわかります。
ともあれ、クイックスタートでは、ひとまず動かしてみる ことが目的なので、このファイルを保存してリモートに push します。
実際のクイックスタートから少し手順を変えてますが、ブランチに push することにより ワークフローが実行されるはずです。
git add . git commit -m "1st commit" git push
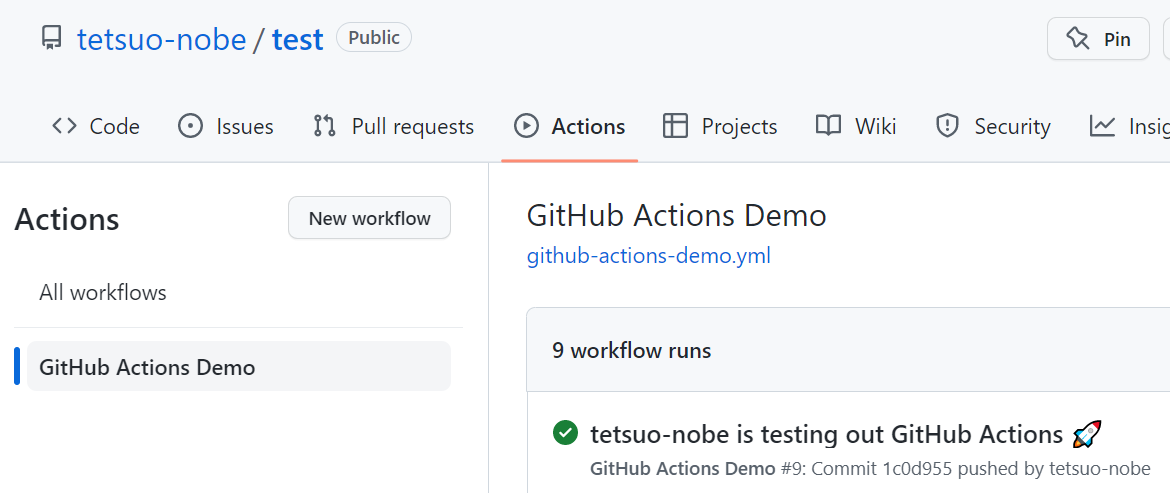
Webブラウザから GitHub のリポジトリのページで Actions タブを選択します。
ページ左側に GitHub Actions Demo と表示されています。 YAML ファイルの冒頭にある name: で指定した名前ですね!
これが ワークフローの名前のようです。
それをクリックすると、右側にこのワークフローが実行された履歴の一覧が表示されます。
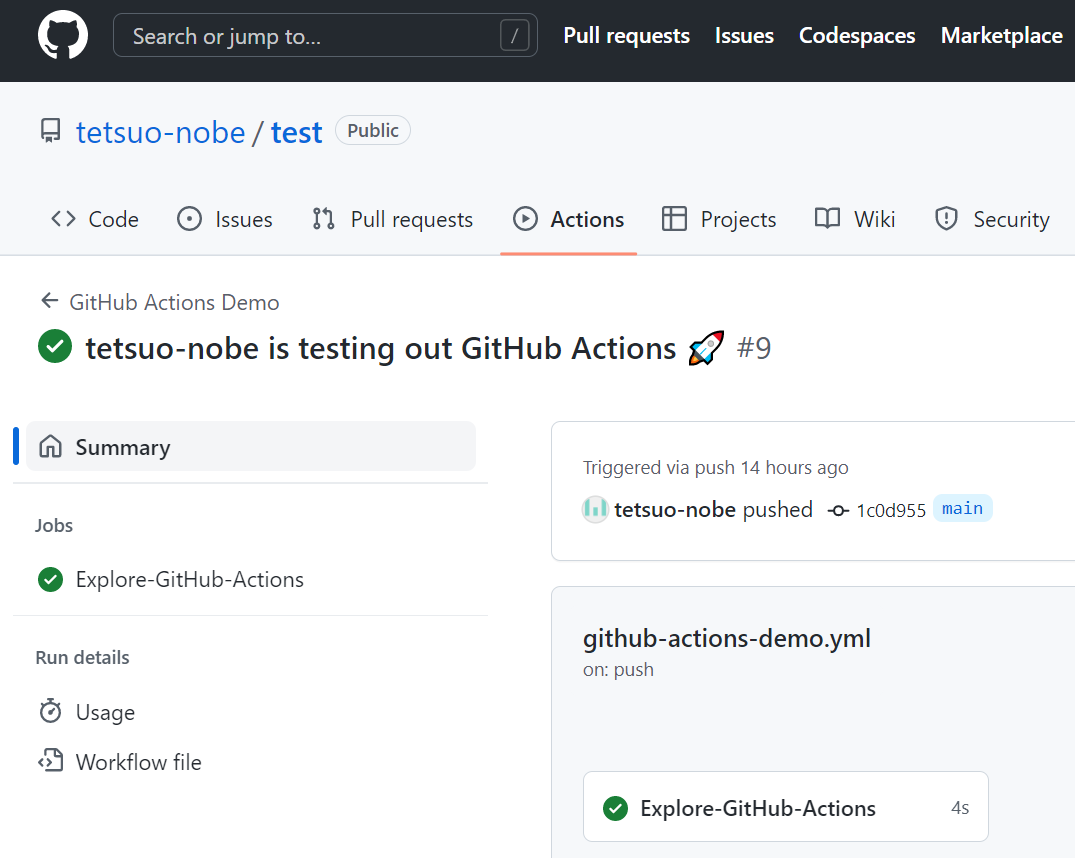
履歴の一覧の中で xxxx is testing out GitHub Actions 🚀 のリンクをクリックします。(xxxx は環境に応じて読み替えて下さい。)
緑色のチェックマークのアイコンが表示されているので、ワークフローが成功したようです。ちなみに失敗すると 赤色の × アイコンが表示されます。
ワークフローのページが表示されるので、その中の Explore-GitHub-Actions をクリックします。
これは、ワークフローの YAML の中の jobs: で指定したジョブ名のようですね。
クリックすると、ワークフローのログが参照できます。
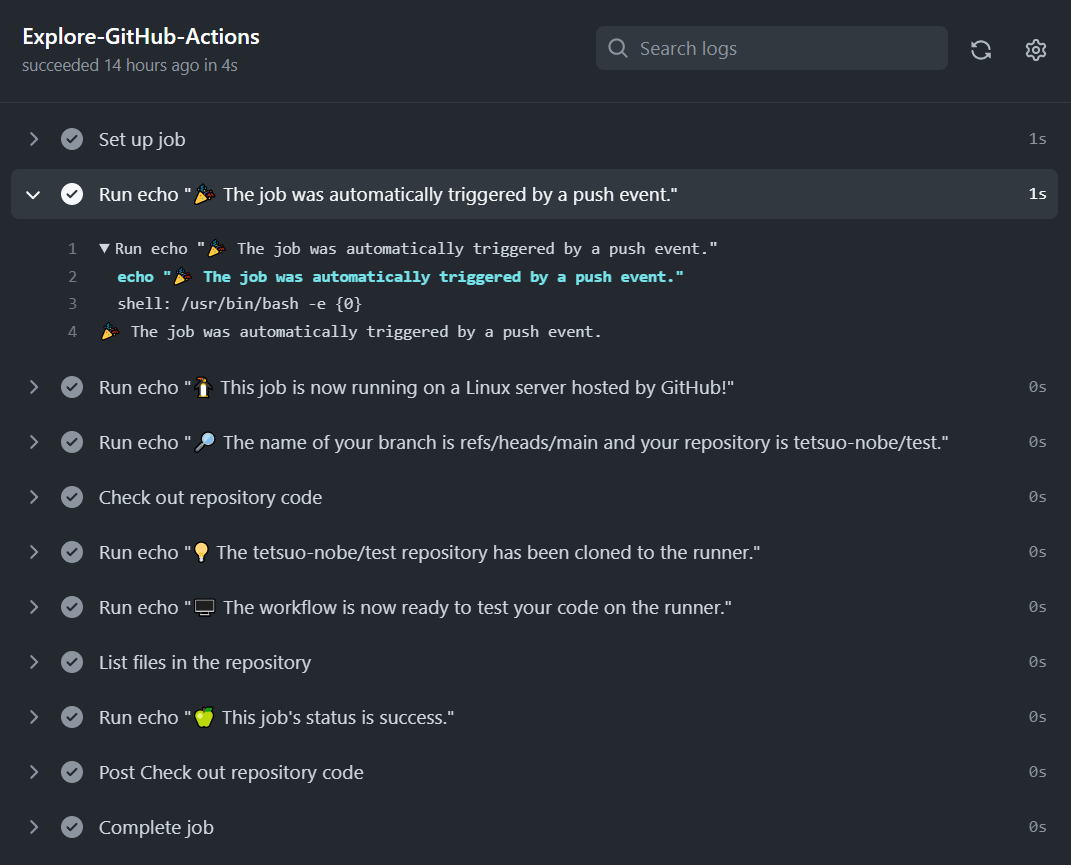
ログを見ると、ワークフローの YAML ファイルの中で steps: として定義した処理が実行されている様子がわかりますね。
ほとんど echo コマンドを実行する内容でしたが、無事にクイックスタートのワークフローは動かせたようです!
ワークフローの基本を理解する。
さて、クイックスタートでは「細かいことはさておき、とりあえず動かしてみよう」という位置づけでワークフローを実行してみましたが、もう少し体系的にワークフローの基本を理解していきたいですよね。
そこで、下記のページを読んで、さらにサンプルのワークフローを動かしてみました。
このページでは、クイックスタートと異なり、サンプルのワークフローを取り上げつつ、基本概念やワークフローの YAML の各構成要素を解説してくれています。
例えば「ワークフロー」、「ジョブ」、「ステップ」、「ランナー」という基本概念も、このページで説明されています。
また、クイックスタートで出てきた uses: actions/checkout@v3 が何だったのかがわかりますね。
actions/checkout は 複雑で頻繁に繰り返されるタスクを実行するための「アクション」であり、@v3 はバージョンの指定、use: はそのアクションをジョブのステップとして実行するキーワードであることがわかりました。
ここで、ふと疑問がわきました。クイックスタートの YAMLファイルを .github/workflows フォルダ に置いたまま、上記ページのサンプルのワークフローの YAML ファイルを追加してもいいのかな?という疑問です。
早速試してみましたが、2つの ワークフローが push をトリガーに正常に動作することを確認できました。
今回は 2つのワークフローは push をトリガーのイベントとしていますが、ワークフローの YAML の中の on: で イベントを変更することもできるようですね。
今回の所感
クイックスタートや、サンプルのワークフローを簡単に、問題なく実行できたのは嬉しいですね。
ワークフローの YAML の書き方を一度に全部覚えるのは無理があるので、色々試しながら、調べながら記憶に定着させていきます。
まだ基本中の基本の「小さな成功」でしかありませんが、この小さいな成功を積み上げていきたいです。
次回は、シンプルなアプリケーションのビルドを行うワークフローを試して記事にするつもりです!