AWS X-Ray における Amazon SQS × AWS Lambda の新しいトレースリンクの機能を試してみる
今回は、最近発表されたAWS X-Ray の次の新機能を試してみます。
従来までどうだったか、この新機能により何ができるようになったか、というのを簡単に図にまとめてみました。
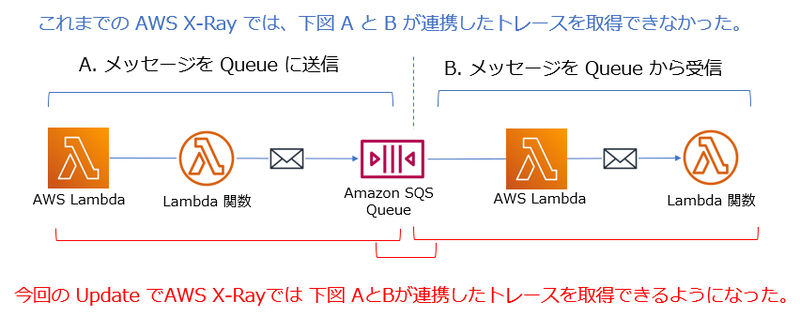
Amazon SQS にメッセージが送信され、その後 AWS Lambda 関数により取り出される処理についてもトレースを取得できるようになったわけですね。
この機能は自動的に適用されるので、使用している Amazon SQS の Queue や AWS Lambda 関数について追加の設定は不要です。
あくまで例ですが、次のような AWS SAM テンプレートから作成すれば、この機能を試すことができます。
上記の SAM テンプレートでは、Amazon SQS の Queue にメッセージを送信する AWS Lambda 関数と、受信する AWS Lambda 関数がリソースとして定義されています。
Globalsセクションで、それぞれの AWS Lambda 関数のプロパティに対して、Tracing: Active を設定し、AWS X-Ray のトレースを取得するようにしています。
Globals: Function: Timeout: 15 Environment: Variables: SQS_QUEUE: !Ref SQSQUEUE DDB_TABLE: !Ref DDBTABLE Tracing: Active
同じく Globals セクションで、Amazon API Gateway にも AWS X-Rayのトレースを取得するようにしています。
Api: TracingEnabled: True
またこのテンプレートでは、Amazon SQS の Queue にメッセージを送信する AWS Lambda 関数 は Python で作成しています。
この AWS Lambda 関数の中で下記のコードを適用して AWS Lambda 関数から他の AWS サービスにアクセスする処理のトレースも取得しています。
from aws_xray_sdk.core import patch patch(['boto3'])
これらをみると、特に何も新しい設定やコードの追加などは行っていませんね。
では、この SAM テンプレートからスタックを作成します。テンプレートの中の Parameters セクションで、S3 バケット名は任意の値に変更して下さい。
SAMのリソース全体は、次から参照できます。samconfig.toml の内容も環境に応じて変更して下さい。
この SAM テンプレートで作成するアプリは、作成した S3 バケットにあらかじめ何かテキストファイルを入れてから実行する前提になっているので、適当なテキストファイルを S3 バケットに入れておきましょう。
その後、Amazon API Gateway に対して API リクエストを送ってみます。
curl -X POST \ https://(API Gateway のURL)/Prod/xray \ -d '{"bucket": "(バケット名)", "key": "(テキストファイル名)"}'
その後、AWS マネジメントコンソールで Amazon CloudWatch のコンソールを開き、左側のナビゲーションメニューから X-Ray トレース の下の サービスマップ を選択します。
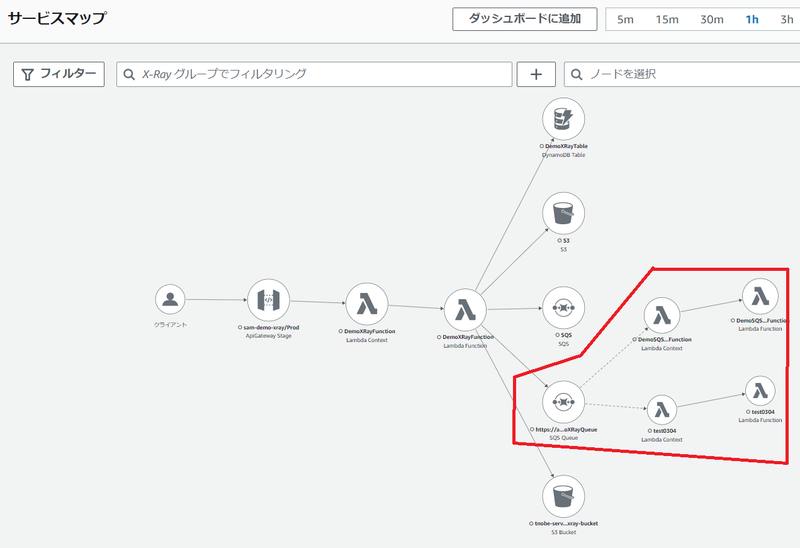
次のようなマップが表示されます。赤枠の部分が新機能により表示されるようになったものです。
Amazon SQS の Queue の後にも、そのメッセージを受信している AWS Lambda 関数の情報が表示されていますね。
次に左側のナビゲーションメニューから X-Ray トレース の下の トレース を選択し、ページ下側にある トレース セクションの中の ID のリンクを選択します。
次のようなトレースマップが表示されます。赤枠の部分が新機能により表示されるようになったものです。
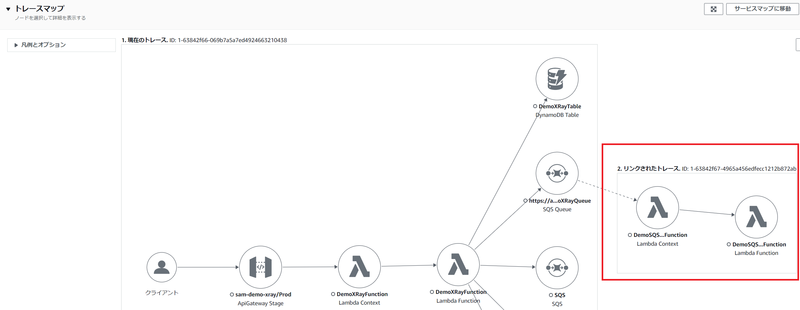
ページ下側に表示されるセグメントのタイムラインでは、次のような情報が参照できます。赤枠の部分が新機能により表示されるようになったものです。

このように、Amazon SQS の Queue が介在する場合でも、一気通貫的なトレースを参照できるようになったので、Queue からメッセージを受信している AWS Lambda 関数をすぐに把握できてトレース分析ができるようになりました。個人的には、これはとてもありがたいことだと感動しています!


Amazon SNS の ペイロードベースのメッセージフィルタリングを試してみる
従来、Amazon SNS のサブスクリプションでは、メッセージの属性値ベースのフィルタリングは可能だったんですが、最近の Update でメッセージ本文、つまり『ペイロード』ベースのフィルタリングも可能になりました。
下記の AWS ブログでは、AWS SAM テンプレートを使用してこの機能を試せるように解説してくれています。
個人的には、この Update は大きい と感じています。
従来、他のアプリケーションやサービスに送信したいメッセージの本文に対してフィルタリングを設定したい場合は、Amazon EventBridge を使うことが多かったのですが、Amazon SNS でも可能になったので選択肢の幅が広がったといえます。例えば、シンプルに AWS Lambda 関数にメッセージを送信したいだけであれば、Amazon SNS の場合は通知件数に対する課金は無料になるので、コスト節減も期待できます。(データ転送容量に対する課金は発生します。)
では、今回は AWS マネジメントコンソール を使ってシンプルにこの機能を試していきます。
なお、ここで紹介する内容は、 2022年 11月 27日時点に確認した内容に基づきます。
今回は、Amazon SNS のサブスクライバーに Amazon SQS の標準キューを使用する前提とします。
任意の名前で 標準キューを作成します。また、そのキューのアクセスポリシーに次ようなステートメントを追加しておきます。(デフォルトのステートメントの変更や削除はしません。)
{ "Sid": "__sns_statement", "Effect": "Allow", "Principal": { "Service": "sns.amazonaws.com" }, "Action": "SQS:SendMessage", "Resource": "arn:aws:sqs:ap-northeast-1:123412341234:MyQueue" }
Resource: で指定するのは 作成した Amazon SQS のキューのARN なので、環境に応じて変更して下さい。
次に、Amazon SNS の 標準トピックを任意の名前で作成します。
続いて、その標準トピックのサブスクリプションを作成します。
サブスクリプションは、事前に作成しておいた Amazon SQS のキューを指定します。
その後は、いよいよフィルターの設定です。
次の図のように、[サブスクリプションポリシー] を展開表示して、[サブスクリプションフィルターポリシー]のトグルを ON にします。そして、[メッセージ本文]を選択します。
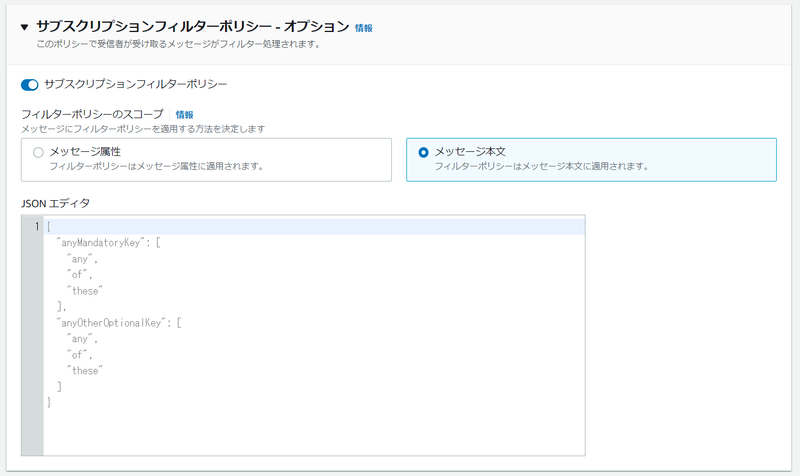
[ JSON エディタ]にフィルターとなる JSON を指定しますが、今回はシンプルに下記のように設定しました。
{ "test": [ 0, 1, 2 ], "check": [ "A", "B", "C" ] }
このフィルターでは、メッセージは "test" キーと "check" キーを持ち、"test" キーは、0,1,2 のいずれかの値、"check"キーは、"A","B","C"のいずれかの値が条件になります。
ここまで設定出来たら、サブスクリプションの作成を完了します。
AWS マネジメントコンソールを使って、作成した標準トピックにメッセージを発行しましょう。
[件名]は任意の値を入力しますが、[本文]では、フィルターの条件にマッチするように次の JSON を入力します。
{ "test": 0, "check":"A" }
メッセージを発行した後、AWS マネジメントコンソールを使ってサブスクリプションに指定したAmazon SQS のキューのメッセージを受信してみましょう。1件、メッセージを受信しているはずです。メッセージの ID のリンクを選択して、送信したメッセージを受信できていることを確認しましょう。
また、他のメッセージも送信してみましょう。
例えば、次のメッセージだとフィルターの条件にマッチするので、キューでは受信されません。
{ "test": 9, "check":"A" }
次のメッセージも、フィルターの条件にマッチしません。
{ "test": 0 }
サブスクリプションのフィルターの内容を変更して色々試してみてもよいでしょう。 複雑なフィルターを記述することもできるので、次のドキュメントを参考にしてみて下さい!
Amazon EventBridge で新たに追加されたフィルターの機能を試してみる
Amazon EventBridge のルールで指定できるフィルター機能が拡張され、下記の評価方法が利用できるようになりました。
- suffix filter (拡張子を指定したフィルター)
- equals-ignore-case (大文字小文字を区別しないマッチング)
- OR matching (複数のフィールドの条件で1つでもtrueであればよい)
地味な機能拡張と思われるかもしれませんが、以前、拡張子を指定したフィルターができなくて困ったことがあったので、個人的には嬉しく感じています!
今回は、この suffix filter (拡張子を指定したフィルター)の機能を試していきます。
なお、この記事の内容は 2022 年 11月 20 日時点で確認したものになります。
簡単にこの機能を試したいだけなので、次のような構成を作ることにしました。

Amazon S3 バケットから Amazon EventBridge への通知については、次のドキュメントも参考にしてみて下さい。
今回は、EventBridge のターゲットになる Lambda 関数は、Python を使う前提です。
上図の構成を作成する AWS SAM テンプレートは、次のようになります。
S3 バケット名はパラメータにしていますが EventBridge ルール名、Lambda 関数名は任意のものに変更して下さい。
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > Demo of EventBridge suffix filter rule Globals: Function: Timeout: 3 Parameters: DemoBucketName: Type: String Default: "tnobe-test-suffix-filter-bucket" Description: "Bucket name for demo of EventBridge suffix filter rule" Resources: S3Bucket: Type: AWS::S3::Bucket Properties: BucketName: !Ref DemoBucketName NotificationConfiguration: EventBridgeConfiguration: EventBridgeEnabled: true EventPrinterFunction: Type: AWS::Serverless::Function Properties: FunctionName: "test-suffix-filter-function" CodeUri: event_printer/ Handler: app.lambda_handler Runtime: python3.7 SuffixFilterRule: Type: AWS::Events::Rule Properties: Name: "test-suffix-filter-rule" Description: " .jpg or .jpeg files only" EventPattern: source: - "aws.s3" detail-type: - "Object Created" detail: bucket: name: - !Ref DemoBucketName object: key: - suffix: ".jpg" - suffix: ".jpeg" State: "ENABLED" Targets: - Arn: Fn::GetAtt: - "EventPrinterFunction" - "Arn" Id: "Target1" PermissionForEventsToInvokeLambda: Type: AWS::Lambda::Permission Properties: FunctionName: Ref: "EventPrinterFunction" Action: "lambda:InvokeFunction" Principal: "events.amazonaws.com" SourceArn: Fn::GetAtt: - "SuffixFilterRule" - "Arn" Outputs: EventPrinterFunction: Description: "EventPrinter Lambda Function ARN" Value: !GetAtt EventPrinterFunction.Arn EventPrinterFunctionIamRole: Description: "Implicit IAM Role created for EventPrinterFunction " Value: !GetAtt EventPrinterFunctionRole.Arn
今回は AWS SAM を使用して Amazon EventBridge のルールを作成していますが、もちろん AWS マネジメントコンソールから作成することもできます。
AWS マネジメントコンソールから作成する場合は、ルールのフィルター設定を JSON で指定する必要があるので、参考までに JSON での拡張子フィルター例を次に掲載しておきます。
{ "source": ["aws.s3"], "detail-type": ["Object Created"], "detail": { "bucket": { "name": ["tnobe-test-suffix-filter-bucket"] }, "object": { "key": [ { "suffix": ".jpg" }, { "suffix": ".jpeg" }] } } }
また、この AWS SAM テンプレートでは、Lambda 関数のコードのファイルが event_printer/ フォルダにあることを指定しています。
よって、テンプレートが存在する場所の event_printer フォルダに app.py のファイルを作成します。
コードの内容は、受け取った Event をそのまま CloudWatch Logs に出力するだけの非常にシンプルなものです。
import json def lambda_handler(event, context): print(event) return { "statusCode": 200, "body": "hello" }
これで環境作成の準備ができたので、AWS SAM CLI でデプロイを行います。
sam build sam deploy --guided
sam deploy --guided を実行すると、対話式で入力が求めらるので、入力します。
(基本的にS3 バケットの名前は入力が必要ですが、それ以外についてはデフォルトの値でかまいません。)
デプロイが完了すると、次のようなメッセージが表示されます。
Successfully created/updated stack - (スタック名) in ap-northeast-1
これで環境は作成できたので、作成した S3バケットに .jpg の拡張子をもつファイルを用意して、アップロードしてみましょう。
下記は例です。
BUCKET_NAME="tnobe-test-suffix-filter-bucket" aws s3 cp cat.jpg s3://${BUCKET_NAME}
この後、作成した Lamnda関数の CloudWatch Logs のログを見てみます。すると、次の例のようなログが出力されます。
START RequestId: b569974b-28d3-4416-886b-4dc9699d0d7e Version: $LATEST
{'version': '0', 'id': 'c95b6b28-0376-cd78-ecf2-d0d100264f3d', 'detail-type': 'Object Created', 'source': 'aws.s3', 'account': '330174381929', 'time': '2022-11-20T04:13:37Z', 'region': 'ap-northeast-1', 'resources': ['arn:aws:s3:::tnobe-test-suffix-filter-bucket'], 'detail': {'version': '0', 'bucket': {'name': 'tnobe-test-suffix-filter-bucket'}, 'object': {'key': 'cat.jpg', 'size': 480853, 'etag': 'b9e3d3da605744062c9a84561a425f47', 'sequencer': '006379A971A6A2DC0E'}, 'request-id': 'RD147W3MYT7D1075', 'requester': '123412341234', 'source-ip-address': '54.238.13.87', 'reason': 'PutObject'}}
END RequestId: b569974b-28d3-4416-886b-4dc9699d0d7e
REPORT RequestId: b569974b-28d3-4416-886b-4dc9699d0d7e Duration: 8.76 ms Billed Duration: 9 ms Memory Size: 128 MB Max Memory Used: 37 MB
ログが出力されたことで、まず EventBridge の拡張子のフィルターで評価され、Lambda 関数が実行されたことがわかります。
またログ内容から、自分が指定したファイルのアップロードによるイベントでこのLambda 関数が実行されたことがわかります。
他にも、拡張子が .jpeg のものや、フィルター条件にマッチしないもの (.png や .txt など)も試してみて下さい。
aws s3 cp cat.jpeg s3://${BUCKET_NAME} aws s3 cp dog.png s3://${BUCKET_NAME} aws s3 cp test.txt s3://${BUCKET_NAME}
上記の例だと、cat.jpeg では、Lambda 関数は実行されますが、それ以外については実行されないことがわかります。
今回は非常にシンプルな構成で試しましたが、このように Amazon EventBridgeの拡張子によるフィルタリングは、S3 バケットのイベントを扱う時に便利ではないか!!と感じます。
AWS Step Functions の Map ステートに動的に生成した配列を渡してみる
前回の記事で AWS Step Functions の Map ステートの基本的な使い方を試してみました。
前回は、ステートマシン実行時のパラメータに配列を手入力して、その配列を Map ステートにそのまま渡していましたが、今回はステートマシンの中で動的に配列を生成し、それを Map ステートに渡すようにしたいと思います。
ステートマシンの Map ステートから呼び出す Lambda 関数は、前回の記事と同じものとします。
それに加え、今回は動的に配列を生成する AWS Lambda 関数を作成します。今回は、Python 3.9 で作成しました。
便宜上、このLambda 関数を ArrayGenerator と呼ぶことにします。
この ArrayGenerator 関数は、イベントオブジェクトから length というキーで指定された数値に基づき、動的に配列を生成してリターンします。
import json def lambda_handler(event, context): print(event) length = event['length'] items = [] for id in range(length): items.append({'item': id}) return items
次に、ステートマシンを作成します。下記の JSON を使用して、前回の記事と同様の手順で作成します。
{ "Comment": "test map state", "StartAt": "Generate Array", "States": { "Generate Array": { "Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "Parameters": { "Payload.$": "$", "FunctionName": "arn:aws:lambda:ap-northeast-1:123412341234:function:ArrayGenerator" }, "Retry": [ { "ErrorEquals": [ "Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException" ], "IntervalSeconds": 2, "MaxAttempts": 6, "BackoffRate": 2 } ], "Next": "Map", "ResultPath": "$.generatedArray" }, "Map": { "Type": "Map", "End": true, "Iterator": { "StartAt": "Lambda Invoke by Map", "States": { "Lambda Invoke by Map": { "Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "OutputPath": "$.Payload", "Parameters": { "Payload.$": "$", "FunctionName": "arn:aws:lambda:ap-northeast-1:123412341234:function:maptest" }, "Retry": [ { "ErrorEquals": [ "Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException" ], "IntervalSeconds": 2, "MaxAttempts": 6, "BackoffRate": 2 } ], "End": true } } }, "MaxConcurrency": 32, "ItemsPath": "$.generatedArray.Payload" } } }
作成したステートマシンは、下図のようになります。
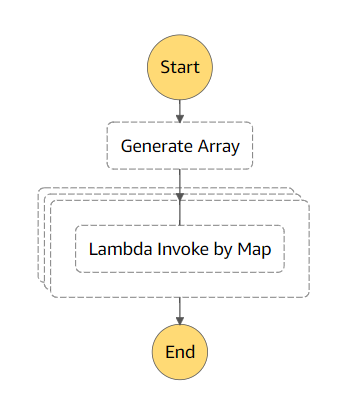
ステートマシンの内容を少し見ていきます。
このステートマシンは前回の記事と異なり、まず Generate Array ステートで、Array Generator 関数を呼び出しています。
ArrayGenerator 関数に 渡すパラメータは、ステートマシン実行時に指定するパラメータをそのまま渡す、という前提です。
そのために、Generate Array ステートでは、ArrayGenerator 関数に 渡すパラメータに、"Payload.$": "$" を指定しています。
また、"ResultPath": "$.generatedArray" という指定があります。
これは、ArrayGenerator 関数がリターンする配列をステートマシンのデータに追加し、$.generatedArray というキーで参照できるようにするための指定です。
後続の Map ステートでは、この配列を受け取るため、"ItemsPath": "$.generatedArray.Payload" という指定をしています。
では、AWS マネジメントコンソールから実行してみます。今回は、配列の要素数を 3 を指定してみます。
作成したステートマシンのページで [実行の開始] ボタンを選択して [入力] に下記のパラメータを指定します。[実行の開始] をクリックします。
{"length": 3}
結果、下図のようにステートマシンは成功します。
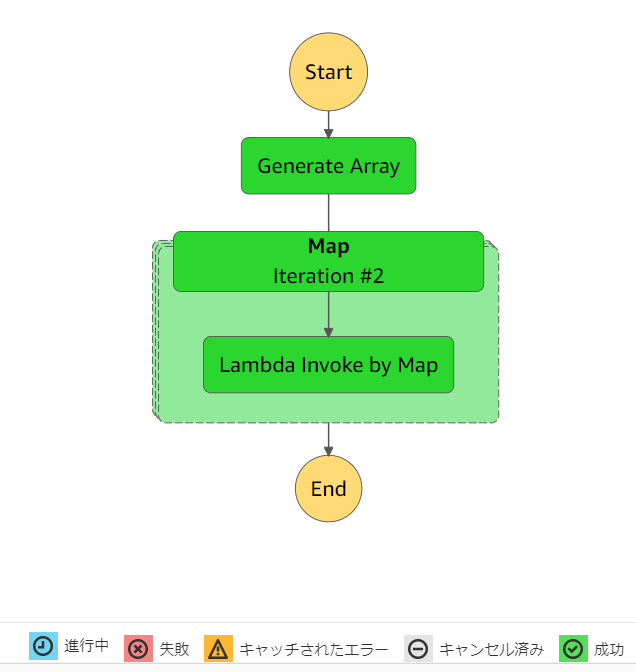
前回の記事と同じように、ページを少し下にスクロールして、[イベント] セクションが表示させ、その中から Lambda Invoke ステップの [Logs] のリンクを選択すると、CloudWatch Logs のページが表示させます。
そこで、3 つのログストリームが作成されていることを確認します。
続けて実行する時は、まずログストリームをすべて削除してから実行すると、手っ取り早く並列性を確認できます。
今回作成したステートマシンは、パラメータにより生成する配列の要素数を指定できるので、値を変更して Map による並列での呼び出し数が変更されることも確認してみましょう!
AWS Step Functions の Map ステートを触ってみる
AWS Step Functions Map ステートで色々試したいことがあるのですが、その事前準備として今回は Map ステートの基本的な機能を確認してみます。
Map は、配列の要素数に応じて同じ処理を並列に実行してくれるステートです。
例えば Map ステート内で Lambda 関数 Aを呼び出すステートを設定し、その Map ステートに対して 要素数 3 の配列を指定すると、Lambda 関数 Aが3並列で呼び出されます。
今回は、シンプルにこの動作を確認してみます。
まず、Map ステートから呼び出す Lambda 関数を作成します。今回は Python 3.9 で作成しました。
このLambda 関数の並列実行を後で確認しやすくするため、このLambda 関数は敢えて 実行に 3 秒かかるように実装しています。
import json import time def lambda_handler(event, context): # TODO implement time.sleep(3) print(event) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }
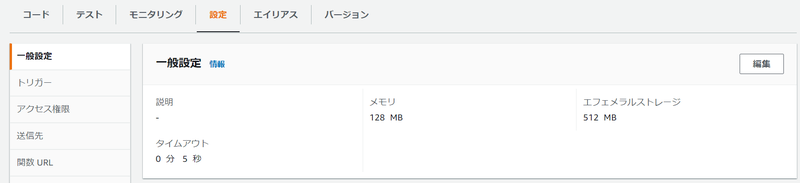
よって、Lambda 関数のタイムアウトを 5 秒に設定しておきましょう。
AWS マネジメントコンソールからだと、[設定]タブを選択して、左側メニューで [一般設定]を選択して、[一般設定]セクションから設定できます。
次は、この Lambda 関数を呼び出す AWS Step Functions のステートマシンです。
下記は例ですが、FunctionName は、作成しておいた Lambda 関数の ARN を指定します。
{ "Comment": "test map state", "StartAt": "Map", "States": { "Map": { "Type": "Map", "End": true, "Iterator": { "StartAt": "Lambda Invoke", "States": { "Lambda Invoke": { "Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "OutputPath": "$.Payload", "Parameters": { "Payload.$": "$", "FunctionName": "arn:aws:lambda:ap-northeast-1:123412341234:function:maptest" }, "Retry": [ { "ErrorEquals": [ "Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException" ], "IntervalSeconds": 2, "MaxAttempts": 6, "BackoffRate": 2 } ], "End": true } } }, "MaxConcurrency": 40 } } }
このJSON を使用してステートマシンを作成します。
AWS マネジメントコンソールから作成する場合は、AWS Step Functions のページで [ステートマシンの作成] を選択して、[コードでワークフローを記述] を選択し、[定義] セクションに JSON を貼り付けます。
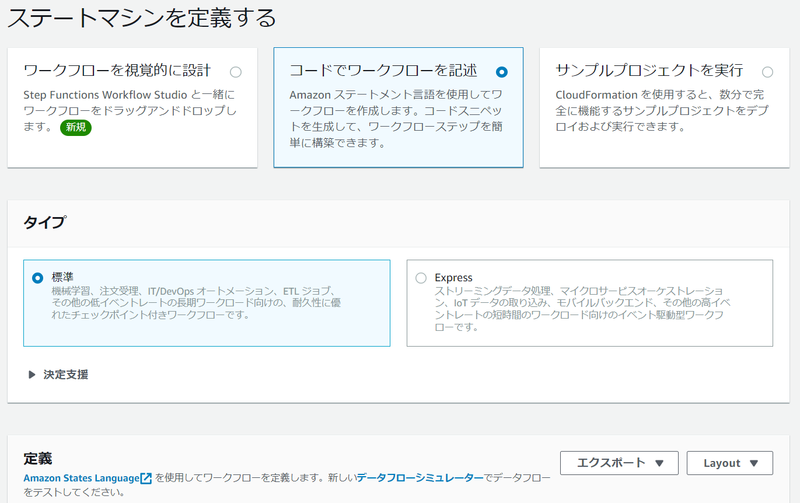
その後、[次へ] ボタンを選択して、ステートマシンに任意の名前をつけて [ステートマシンの作成] をクリックします。
作成したステートマシンは下図のようになります。

また、Workflow Studio でみると、下図のようになります。
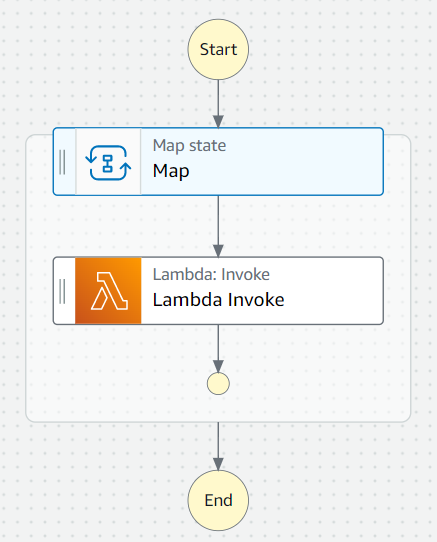
では、作成したステートマシンを実行してみます。
今回は、ステートマシンのパラメータを配列にして、そのまま Map ステートに渡す前提にしていますので、パラメータに JSONの配列を指定します。
内容は、どんなものでもかまいませんが、要素を識別できるような値にすると、あとあと Lambda 関数の実行確認に役立ちます。
下記は例です。
[ {"id": 1}, {"id": 2}, {"id": 3} ]
では、AWS マネジメントコンソールから実行してみます。作成したステートマシンのページで [実行の開始] ボタンを選択して [入力] に上記のパラメータを指定します。[実行の開始] をクリックします。

最終的に下図のように、Map ステートと、その内側の Lambda 関数を呼び出すステートが緑色に表示されることを確認します。
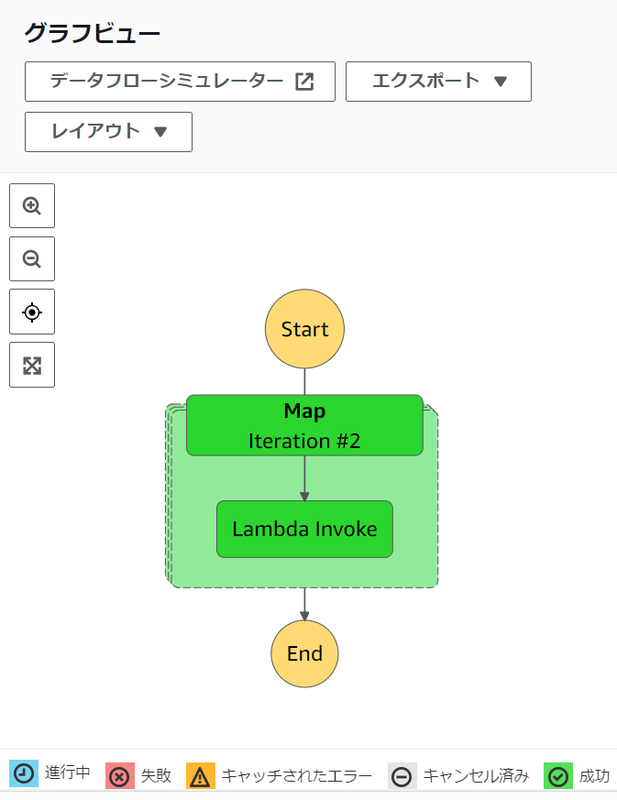
ページを少し下にスクロールすると、[イベント] セクションが表示されています。その中から Lambda Invoke ステップの [Logs] のリンクを選択すると、CloudWatch Logs のページが表示されます。
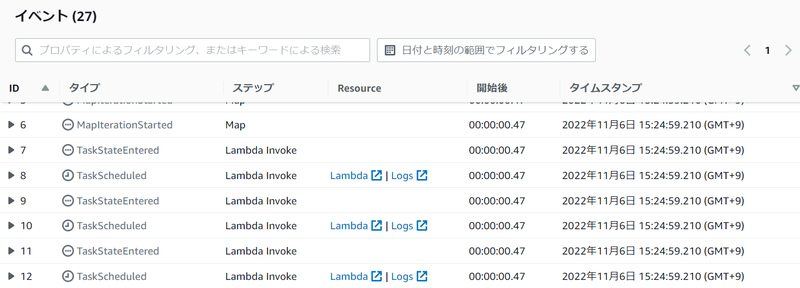
ここで、3 つのログストリームが作成されていることを確認します。これは 3つの Lambda関数の実行環境が作成されて、それぞれログが出力されたことを表します。
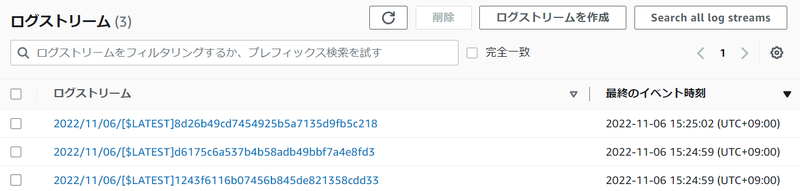
それぞれログをみてみましょう。ステートマシンのパラメータで指定した配列の要素が出力されています。下記は例です。
START RequestId: d348870f-69a7-4778-953b-e8dccd23b444 Version: $LATEST
{'id': 2}
END RequestId: d348870f-69a7-4778-953b-e8dccd23b444
REPORT RequestId: d348870f-69a7-4778-953b-e8dccd23b444 Duration: 3005.46 ms Billed Duration: 3006 ms Memory Size: 128 MB Max Memory Used: 36 MB Init Duration: 101.36 ms
これで、Map ステートから 3並列で Lambda関数を呼び出せたことを確認できました。
Map ステートでやりたいことは他にもあるのですが、まずは超基本の動作確認を行いました。
また Map ステートのネタで記事を書きたいと思います!
AWS Parameters and Secrets Lambda Extension を試してみる
前回のブログ記事で、AWS Parameters and Secrets Lambda Extension のドキュメントの記載の注意点について説明しましたが、今回は AWS CLI を主体としてシンプルに試す手順を説明します。
なお、この記事の内容は 2022年 10月 23日時点のものになります。
まず、Lambda 関数からアクセスする Secrets Manager のシークレットを作成します。
aws secretsmanager create-secret \ --name MyTestSecret \ --description "My test secret created with the CLI." \ --secret-string "{\"user\":\"admin\",\"password\":\"admin1234\"}"
次に、Lambda関数の実行ロールを作成し、ポリシーをアタッチします。
なお、今回はサンプルのため管理ポリシーとして SecretsManagerReadWrite を設定していますが、実際は最小限の権限に絞ったポリシーを設定して下さい。
aws iam create-role --role-name my-function-role --assume-role-policy-document '{"Version": "2012-10-17","Statement": [{ "Effect": "Allow", "Principal": {"Service": "lambda.amazonaws.com"}, "Action": "sts:AssumeRole"}]}' aws iam attach-role-policy --role-name my-function-role --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole aws iam attach-role-policy --role-name my-function-role --policy-arn arn:aws:iam::aws:policy/SecretsManagerReadWrite
次に Lambda 関数のコードを用意します。 今回は、ラインタイムとして Python 3.9 の関数のコードを my-function.py に保存します。
import json import os import urllib.request secrets_extension_http_port = os.environ.get('PARAMETERS_SECRETS_EXTENSION_HTTP_PORT',"2773") # default 2773 def lambda_handler(event, context): # TODO implement secret_name = os.environ.get('MY_SECRET_NAME') secrets_extension_endpoint = "http://localhost:" + \ secrets_extension_http_port + \ "/secretsmanager/get?secretId=" + \ secret_name req = urllib.request.Request(secrets_extension_endpoint) req.add_header('X-Aws-Parameters-Secrets-Token', os.environ.get('AWS_SESSION_TOKEN')) with urllib.request.urlopen(req) as res: secret = json.loads(res.read())['SecretString'] user = json.loads(secret)['user'] return { 'statusCode': 200, 'body': user }
このコードをみるとわかるように、Paramerer Store や Secrets Manager の値は、内部に構成された Web サーバーに対してリクエストを送ることで取得できます。
リクエストには、X-Aws-Parameters-Secrets-Token ヘッダで、環境変数の AWS_SESSION_TOKEN の値をセットします。
このコードのファイルを zip 化します。
zip my-function.zip my-function.py
次に Lamnda関数を作成します。ここでは、AWS アカウント ID は すべて 0 にしています。
aws lambda create-function --function-name my-function \ --zip-file fileb://my-function.zip --handler my-function.lambda_handler --runtime python3.9 \ --role arn:aws:iam::000000000000:role/my-function-role
次に、この Lambda 関数に AWS Parameters and Secrets Lambda Extension の Lambda レイヤーを設定します。
レイヤーの ARN はリージョンにより異なります。次のドキュメントを参照してください。
aws lambda update-function-configuration --function-name my-function \ --layers arn:aws:lambda:ap-northeast-1:133490724326:layer:AWS-Parameters-and-Secrets-Lambda-Extension:2
また、今回は Secrets Manager のシークレット名を環境変数で渡す前提にしているので、Lambda 関数に環境変数を設定します。
aws lambda update-function-configuration \ --function-name my-function \ --environment Variables='{MY_SECRET_NAME="MyTestSecret"}' \
では、Lambda 関数を実行してみます。
aws lambda invoke --function-name my-function response.json cat response.json
次の出力例のように、body に Secrets Manager のシークレットで格納していた user の値である admin が表示されればOKです。
{"statusCode": 200, "body": "admin"}
キャッシュの機能を試したい場合は、次のような手順で試します。
Lambda 関数に SECRETS_MANAGER_TTL の環境変数 で 120 秒ほど設定します。
Lambda 関数を実行して値を取得します。
その後、すぐに Secrets Manager の値を変更します。
Lambda 関数を実行を繰り返して、何度も値を取得し続けます。
すると、2 分経過するまでは、変更前の値が取得されますが、2 分経過後は新しい値が取得されます。
このキャッシュ機能を試すには、作成されたLambda 関数の実行環境を維持する必要があるので、Lambda関数のバージョンを作成し、「プロビジョニングされた同時実行」を 1 にすると試しやすいです。ただし、この機能は別途料金がかかるので、注意して下さい!
AWS Parameters and Secrets Lambda Extension のドキュメントの記載に注意
AWS Parameters and Secrets Lambda Extension を触ってみたところ、ドキュメントで混乱を招く記載があったので、その点を記載していきます。
なお、この記事の内容は 2022年 10月 23日時点のものになります。
AWS Parameters and Secrets Lambda Extension は、AWS Systems Manager の Parameter Store や AWS Secrets Manager の値を Lambda関数からシンプルに取得し、かつ一度取得した値をキャッシュする機能を提供します。
このキャッシュの有効期限 ( TTL ) はLambda関数の環境変数で設定します。
例えば、Secrets Manager の場合は、SECRETS_MANAGER_TTL という環境変数で、Parameter Store の場合は、SSM_PARAMETER_STORE_TTL という環境変数になります。
この環境変数に指定する時間の単位ですが、Parameter Store のドキュメントの記載では次のように、デフォルト値として 300000 ms 、つまり 5分 と記述されています。
この記載をみて、「ms単位で指定するのか」と思ったんですが、これは誤りで実際は、秒単位で指定する必要があります。
間違えて ms 単位で指定すると、その内容は無視されてデフォルトの 5 分が適用されます。
最初、2分、つまり 120000ms で値を設定してみたのですが、キャッシュの無効化が5分だったので、PARAMETERS_SECRETS_EXTENSION_LOG_LEVEL 環境変数を DEBUG に設定してデバッグログを取得してみました。
すると次のようなログが出たので、ms単位ではない!と気づいたわけです。
[AWS Parameters and Secrets Lambda Extension] 2022/10/23 02:07:01 WARN SECRETS_MANAGER_TTL exceeds max limit. Setting Secrets Manger TTL to 5m0s. [AWS Parameters and Secrets Lambda Extension] 2022/10/23 02:07:01 WARN SSM_PARAMETER_STORE_TTL exceeds max limit. Setting SSM Parameter Store TTL to 5m0s.
ちなみに、Secrets Manager のドキュメントには、このような誤解を招く記載はありません。
これについては、すでに AWS 側に フィードバックを送りましたが、デフォルト値には正しい単位で記載することと、そもそも何の単位で指定するのかを明記していただきたいものだと思いました。
実際にAWS Parameters and Secrets Lambda Extensionを試す手順については、次のブログ記事に記載します。